在Java开发中,经常会使用到多线程来处理一些数据聚合的场景或者是多任务的场景,尝尝使用到线程池技术,这边文章将详细的讲解在创建线程池时的7个参数的解释;
多线程使用的得当的话,可以很好的提高代码的执行效率,提高任务的处理性能;如果使用的不当,相反会造成各种问题并且不太好排查;
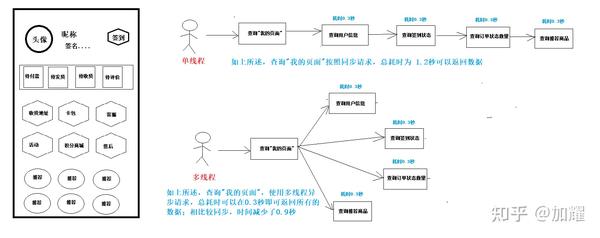
如下图所示,在使用多线程场景异步消息,可以有效的降低数据聚合的时间,从何提高用户体验;
在阿里巴巴Java开发手册中明确禁止线程池使用Executors去创建,而是通过ThreadPoolExecutor的方式进行创建,这样的处理方式让写的同学更加明确线程池的运行规则,从而可以避免资源耗尽的风险;
构造函数
通过源码可以看到ThreadPoolExecutor的构造函数如下
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
构造参数
通过上述构造函数可以看到,在创建一个线程池的时候,一共有7个参数,这7个参数的意思如下:
- corePoolSize:表示当前线程池的核心线程数大小,即最小线程数(初始化线程数),线程池会维护当前数据的线程在线程池中,即使这些线程一直处于闲置状态,也不会被销毁;
- maximumPoolSize:表示线程池中允许的最大线程数;后文中会详细讲解
- keepAliveTime :表示空闲线程的存活时间,当线程池中的线程数量大于核心线程数且线程处于空闲状态,那么在指定时间后,这个空闲线程将会被销毁,从而逐渐恢复到稳定的核心线程数数量;
- unit:当前unit表示的是keepAliveTime存活时间的计量单位,通常使用TimeUnit.SECONDS秒级;
- workQueue:任务工作队列;后文会结合maximumPoolSize一块来讲
- threadFactory:线程工厂,用于创建新线程以及为线程起名字等
- handler:拒绝策略,即当任务过多无法及时处理时所需采取的策略;
在上面有提到一个最大线程数,当一个新任务来到线程池时,首先会先将当前任务放到workQueue(任务工作队列)里面,然后交由调度任务从队列中取出任务,交由线程池中的线程进行处理;
如果工作队列满了,则会通过线程工厂创建一个新的线程到线程池,然后从工作任务中取出一个任务交由新线程处理,而刚提交的任务则放入到工作任务队列中;
当工作队列中的任务也达到最大限制并且线程池中的线程数量达到最大线程数,这时候则会触发线程池的拒绝策略;
工作任务队列分类
在jdk中,一共提供了4种工作任务队列,分别如下所示:
1、ArrayBlockingQueue:通过名字我们可以推测出,当前队列是基于Array数组实现的,数组的特性是初始化时需要指定数组的大小,也就是指定了存储的工作任务上限;ArrayBlockingQueue是一个基于数据的有界的阻塞队列,新加入的任务放到队列的队尾,等待被调度;如果队列已经满了,则会创建新线程;如果线程池数量也满了,则会执行拒绝策略;
2、LinkedBlockingQuene:通过名字我们可以推测出,当前队列是基于Linked链表来实现的,链表的特性是没有初始容量,也就意味着这个队列是无界的,最大容量可以达到Integer.MAX。也由于LinkedBlockingQuene的无界特性,当有新的任务进来,会一直存储在当前队列中,等待调度任务来进行调度;在此场景下,参数maximumPoolSize是无效的;LinkedBlockingQuene可能会带来资源耗尽的问题;
3、SynchronousQuene:同步队列,一个不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出任务,直接被调度任务调度执行当前任务;如果没有空闲的可用线程,则直接创建新的线程进行处理,当线程池数量达到maximumPoolSize时,则触发拒绝策略;
4、PriorityBlockingQueue:优先考虑无界阻塞队列,优先级可以通过Comparator来实现;
线程池拒绝策略
在前面提到过,当工作任务队列达到最大值并且线程池的容量也达到了最大线程数时,当有新的任务进来时,则会触发拒绝策略;在JDK中一共提供了4种拒绝策略,分别如下:
1、CallerRunsPolicy
该策略下,在调用者线程中直接执行被拒绝任务的run方法,除非线程池已经shutdown,则直接抛弃任务。
2、AbortPolicy
该策略下,直接丢弃任务,并抛出RejectedExecutionException异常。
3、DiscardPolicy
该策略下,直接丢弃任务,什么都不做。
4、DiscardOldestPolicy
该策略下,抛弃进入队列最早的那个任务,然后尝试把这次拒绝的任务放入队列
创建线程池示例代码
在实际应用场景中,可能大部分线程池的创建如下所示
/**
* 获取当前运行机器的可用CPU核心数
*/
private final static int POLLER_THREAD_COUNT = Runtime.getRuntime().availableProcessors();
@Bean
public ExecutorService executorService(){
return new ThreadPoolExecutor(
POLLER_THREAD_COUNT,
POLLER_THREAD_COUNT * 8,
10L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(64),
new ThreadFactoryBuilder().setNameFormat("AppName_FutureTask-%d").setDaemon(true).build(),
new ThreadPoolExecutor.CallerRunsPolicy());
}
通过运行代码可以看到如下

在上述代码中,通过函数Runtime.getRuntime().availableProcessors()获取到当前运行环境的可用处理器数量,然后基于当前可用核心数数量来决定最大线程数;
我们可以根据实际的业务场景或者是硬件指标来决定最大核心线程数,也就是所谓的 CPU密集型 与 IO密集型;
另外提一点,我们在使用线程时,很多时候为线程配置一下环境信息,通常会使用 ThreadLocal 用来存储数据;但是在多线程线程下,如果子线程需要使用主线程的数据时,使用ThreadLocal 是无法实现数据访问的;
这个时候可以采用InheritableThreadLocal来实现,InheritableThreadLocal可以实现父线程传递本地变量到子线程;不过在实际应用场景中,好像也还是有一点缺陷,我看我们这边项目中最后逐渐迭代到使用阿里的TransmittableThreadLocal,即阿里的TTL,引入依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>transmittable-thread-local</artifactId>
<version>2.12.1</version>
</dependency>