二分查找
二分查找的数组必须是有序的数组,通过折半查找,很方便的找到查找的值。

如上图所示,原理很简单,代码如下


package com.liuixnghang.test; import org.junit.Test; public class ErFeng { @Test public void run(){ int[] a=new int[]{1,4,7,9}; int index = erfeng1(a, 0, a.length - 1, 6); System.out.println(index); } //非递归 public int erfeng(int[] a,int left,int right,int value){ while(left<=right){ //得到中间索引 int mid=(left+right)/2; if(value>a[mid]){ left=mid+1; }else if(value<a[mid]){ right=mid-1; }else { return mid; } } return -1; } //递归 public int erfeng1(int[] a,int left,int right,int value){ if(left>right){ return -1; } int mid=(left+right)/2; if(a[mid]>value){ return erfeng1(a,left,mid-1,value); }else if(a[mid]<value){ return erfeng1(a,mid+1,right,value); }else { return mid; } } }
哈希表
根据关键码值直接进行访问的数据结构,
每次有id进来,都可以根据id的值,存入相应的哈希表中,取的时候也只会在相应的哈希表中取。
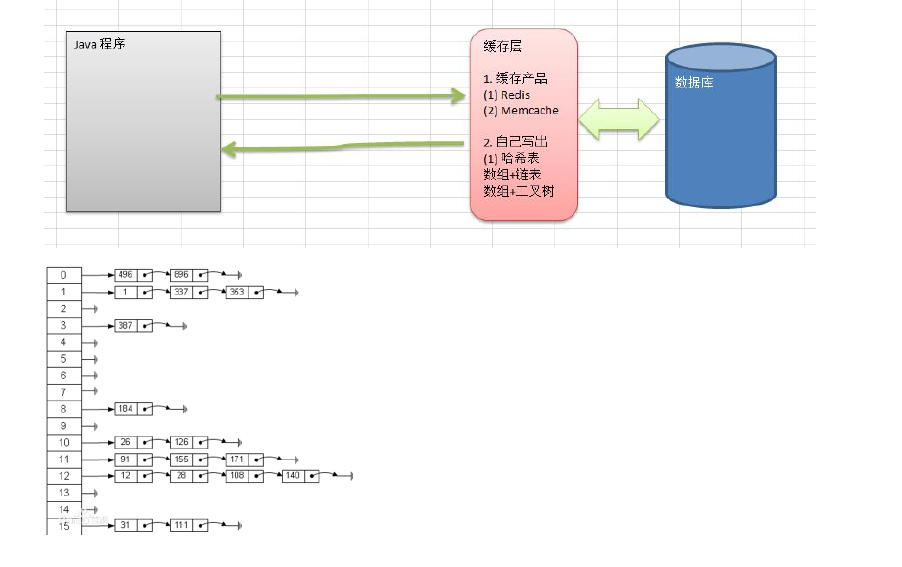
二叉树
每个节点最多只能有两个子节点。
二叉树的遍历
代码如下:
package com.liuixnghang.btree; public class Main{ public static void main(String[] args) { //1.创建二叉树 BTreeNote root=new BTreeNote(10); BTreeNote note1=new BTreeNote(7); BTreeNote note2=new BTreeNote(6); BTreeNote note3=new BTreeNote(2); BTreeNote note4=new BTreeNote(0); root.left=note1; root.right=note2; note1.left=note3; note2.right=note4; //遍历二叉树 //BTreeNote.pre(root); //BTreeNote.mid(root); BTreeNote.aft(root); } } class BTreeNote { public int val; public BTreeNote left; public BTreeNote right; public BTreeNote(int val){ this.val=val; } public static void pre(BTreeNote root){ if(root!=null){ System.out.println(root.val); if(root.left!=null){ pre(root.left); } if(root.right!=null){ pre(root.right); } } } public static void mid(BTreeNote root){ if(root!=null){ if(root.left!=null){ mid(root.left); } System.out.println(root.val); if(root.right!=null){ mid(root.right); } } } public static void aft(BTreeNote root){ if(root!=null){ if(root.left!=null){ aft(root.left); } if(root.right!=null){ aft(root.right); } System.out.println(root.val); } } }
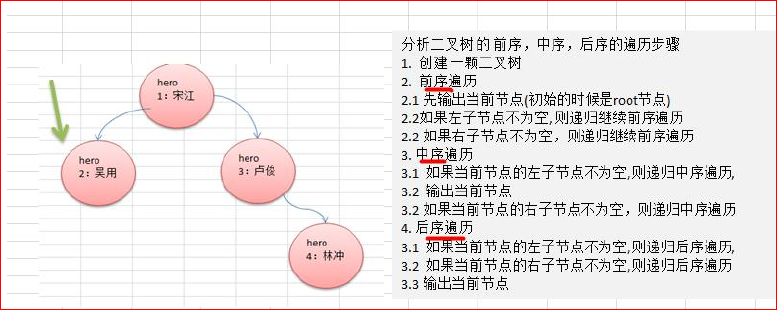
二叉树查找指定节点
代码与遍历代码一致
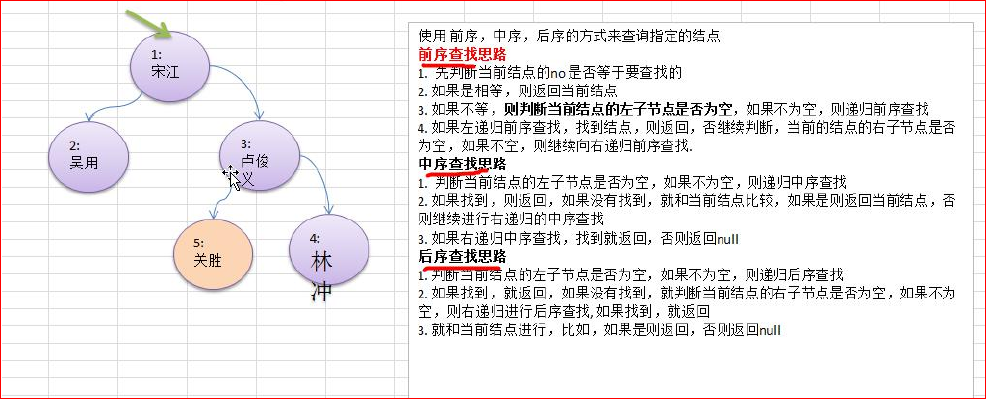
二叉树删除节点
线索化二叉树

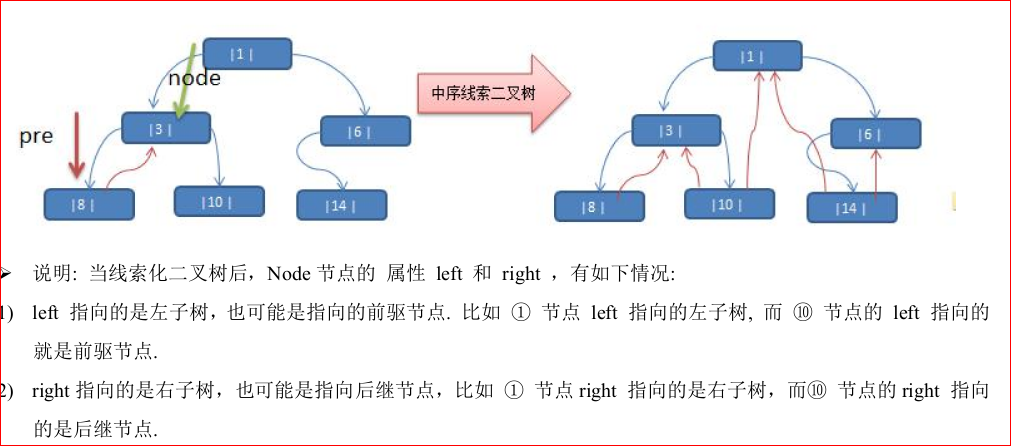
以上说明了线索二叉树的精髓:left指针不仅指向左子树还指向前驱节点;right不止指向右子树还指向后继节点。
因此,线索化二叉树在节点的属性上需要比普通二叉树多两个属性,标志其左节点表示的是左节点还是前驱节点。
代码如下
package com.liuixnghang.btree; import org.junit.Test; public class ThreadBTree { private BTreeNote pre=null; @Test public void run(){ //1.创建二叉树 BTreeNote root=new BTreeNote(10); BTreeNote note1=new BTreeNote(7); BTreeNote note2=new BTreeNote(6); BTreeNote note3=new BTreeNote(2); BTreeNote note4=new BTreeNote(0); root.left=note1; root.right=note2; note1.left=note3; note2.right=note4; thread(root); list(root); } //将二叉树线索化。 //中序线索化 public void thread(BTreeNote note){ if(note==null){ return; } //线索化左子树 thread(note.left); //线索化当前节点 if(note.left==null){ note.left=pre; note.leftType=1; } if(pre!=null && pre.right==null){ pre.right=note; pre.rightType=1; } pre=note; //线索化右子树 thread(note.right); } //遍历线索化二叉树 public void list(BTreeNote root){ while(root!=null){ //得到第一个节点 while (root.leftType==0){ root=root.left; } System.out.println(root.val); while(root.rightType==1){ root=root.right; System.out.println(root.val); } root=root.right; } } }
堆排序
通过构造大顶堆,每次能得到一个根节点是最大值的二叉树,循环,就能依次找出次大值。因此,堆排序相当于一个选择排序。

首先,将一个数组构建成一个大顶堆:
代码如下
package com.liuixnghang.btree; import org.junit.Test; import java.util.Arrays; public class Dadingdui { @Test public void run(){ int a[]=new int[]{7,2,-8,9,3,0,6}; // adjust(a,2,a.length); for(int i=a.length/2-1;i>=0;i--){ adjust(a,i,a.length); } for(int j=a.length-1;j>0;j--) { int temp = a[0]; a[0] = a[j]; a[j] = temp; adjust(a,0,j); } System.out.println(Arrays.toString(a)); } /** * * @param a 待调整的数组 * @param i 非叶子节点,待调整的位置 * @param length 待调整的长度,递减 */ public void adjust(int [] a,int i,int length){ int temp=a[i]; for(int k=i*2+1;k<length;k=k*2+1){ if(k+1<length &&a[k]<a[k+1]){ k++; } if(temp<a[k]){ a[i]=a[k]; i=k; }else { break; } } a[i]=temp; } }
赫夫曼树
给定n个权值作为n个叶子节点,构造一颗二叉树,若该树的带权路径长度wpl达到最小,则为赫夫曼树

构造赫夫曼树的步骤
步骤1:将节点从小到大顺序排序,每个节点都是一个二叉树。
步骤2:取出根节点的权值最小的两颗树,组成一颗新二叉树,该二叉树的根节点的权值是两颗二叉树权值之和。
步骤3:将现有的节点再次以根节点权值大小排序,然后重复步骤2,3,直到所有节点组成一颗二叉树为止。
代码如下:
package com.liuixnghang.btree; import org.junit.Test; import java.util.ArrayList; import java.util.Collections; import java.util.List; public class Huffman { @Test public void run(){ int[] a=new int[]{13,7,8,3,29,6,1}; creat(a); } //构建赫夫曼树 public void creat(int[] a){ //利用数组得到节点 List<BTree> list=new ArrayList<BTree>(); for(int i=0;i<a.length;i++){ BTree note=new BTree(a[i]); list.add(note); } while (list.size()>1) { Collections.sort(list); // System.out.println(list); BTree leftNote = list.get(0); BTree rightNote = list.get(1); BTree parent = new BTree(leftNote.val + rightNote.val); parent.left = leftNote; parent.right = rightNote; list.remove(leftNote); list.remove(rightNote); list.add(parent); } pre(list.get(0)); } public void pre(BTree root){ System.out.println(root.val); if(root.left!=null){ pre(root.left); } if(root.right!=null){ pre(root.right); } } } class BTree implements Comparable<BTree>{ public int val; public BTree left; public BTree right; public BTree(int val){ this.val=val; } @Override public String toString() { return "BTree{" + "val=" + val + '}'; } public int compareTo(BTree o) { return this.val-o.val; } }
二叉排序树
任何一个非叶子节点,其左子节点的值要比当前节点的小,右子节点的值要比当前节点大。
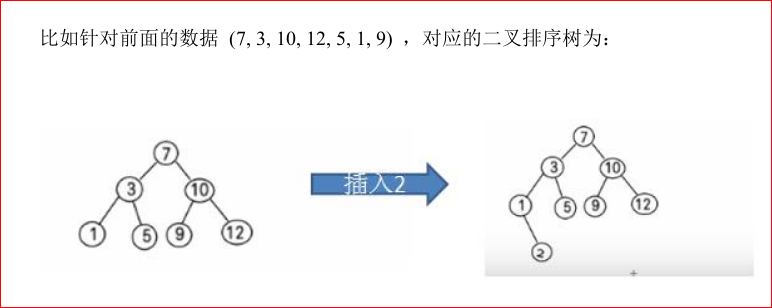
二叉排序树的创建和遍历(使用中序遍历就可以使二叉排序树有序输出)
代码如下:
package com.liuixnghang.btree; import org.junit.Test; public class BST { @Test public void run(){ int[] a = {7, 3, 10, 12, 5, 1, 9, 2,7}; BSTree binarySortTree = new BSTree(); //循环的添加结点到二叉排序树 for(int i = 0; i< a.length; i++) { binarySortTree.add(new Node(a[i])); } binarySortTree.infixOrder(); } } //二叉排序树 class BSTree{ public Node root; public void add(Node node) { if(root == null) { root = node;//如果root为空则直接让root指向node } else { root.add(node); } } //中序遍历 public void infixOrder() { if(root != null) { root.infixOrder(); } else { System.out.println("二叉排序树为空,不能遍历"); } } } //节点 class Node{ int val; Node left; Node right; @Override public String toString() { return "Node{" + "val=" + val + '}'; } public Node(int val){ this.val=val; } public void add(Node node){ if(node==null){ return; } if(node.val<this.val){ if(this.left==null){ this.left=node; }else { this.left.add(node); } }else { if(this.right==null){ this.right=node; }else { this.right.add(node); } } } public void infixOrder() { if(this.left != null) { this.left.infixOrder(); } System.out.println(this); if(this.right != null) { this.right.infixOrder(); } } }
二叉排序树的删除

以上就是删除一个二叉排序树需要考虑的情况,代码如下:
package com.liuixnghang.btree; import org.junit.Test; public class BST { @Test public void run(){ int[] a = {7, 3, 10, 12, 5, 1, 9, 2}; BSTree binarySortTree = new BSTree(); //循环的添加结点到二叉排序树 for(int i = 0; i< a.length; i++) { binarySortTree.add(new Node(a[i])); } binarySortTree.delNode(7); binarySortTree.infixOrder(); } } //二叉排序树 class BSTree{ public Node root; public void add(Node node) { if(root == null) { root = node;//如果root为空则直接让root指向node } else { root.add(node); } } //中序遍历 public void infixOrder() { if(root != null) { root.infixOrder(); } else { System.out.println("二叉排序树为空,不能遍历"); } } //查找要删除的节点 public Node search(int value){ if(root==null){ return null; } else { return root.search(value); } } //查找要删除节点的父节点 public Node searchParent(int value) { if(root == null) { return null; } else { return root.searchParent(value); } } //删除以node为根节点的二叉排序树的最小节点 public int delRightTreeMin(Node node) { Node target = node; //循环的查找左子节点,就会找到最小值 while(target.left != null) { target = target.left; } //这时 target就指向了最小结点 //删除最小结点 delNode(target.val); return target.val; } //删除节点 public void delNode(int value) { if(root == null) { return; }else { //1.需求先去找到要删除的结点 targetNode Node targetNode = search(value); //如果没有找到要删除的结点 if(targetNode == null) { return; } //如果我们发现当前这颗二叉排序树只有一个结点 if(root.left == null && root.right == null) { root = null; return; } //去找到targetNode的父结点 Node parent = searchParent(value); //如果要删除的结点是叶子结点 if(targetNode.left == null && targetNode.right == null) { //判断targetNode 是父结点的左子结点,还是右子结点 if(parent.left != null && parent.left.val == value) { //是左子结点 parent.left = null; } else if (parent.right != null && parent.right.val == value) {//是由子结点 parent.right = null; } } else if (targetNode.left != null && targetNode.right != null) { //删除有两颗子树的节点 int minVal = delRightTreeMin(targetNode.right); targetNode.val = minVal; } else { // 删除只有一颗子树的结点 //如果要删除的结点有左子结点 if(targetNode.left != null) { if(parent != null) { //如果 targetNode 是 parent 的左子结点 if(parent.left.val == value) { parent.left = targetNode.left; } else { // targetNode 是 parent 的右子结点 parent.right = targetNode.left; } } else { root = targetNode.left; } } else { //如果要删除的结点有右子结点 if(parent != null) { //如果 targetNode 是 parent 的左子结点 if(parent.left.val == value) { parent.left = targetNode.right; } else { //如果 targetNode 是 parent 的右子结点 parent.right = targetNode.right; } } else { root = targetNode.right; } } } } } } //节点 class Node{ int val; Node left; Node right; @Override public String toString() { return "Node{" + "val=" + val + '}'; } public Node(int val){ this.val=val; } //查找要删除的节点 public Node search(int value){ if(this.val==value){ return this; } else if(this.val>val){ if(this.left==null){ return null; } return this.left.search(value); }else { if(this.right==null){ return null; } return this.right.search(value); } } //查找要删除节点的父节点 public Node searchParent(int value){ if((this.left != null && this.left.val == value) || (this.right != null && this.right.val == value)) { return this; } else { //如果查找的值小于当前结点的值, 并且当前结点的左子结点不为空 if(value < this.val && this.left != null) { return this.left.searchParent(value); //向左子树递归查找 } else if (value >= this.val && this.right != null) { return this.right.searchParent(value); //向右子树递归查找 } else { return null; // 没有找到父结点 } } } public void add(Node node){ if(node==null){ return; } if(node.val<this.val){ if(this.left==null){ this.left=node; }else { this.left.add(node); } }else { if(this.right==null){ this.right=node; }else { this.right.add(node); } } } public void infixOrder() { if(this.left != null) { this.left.infixOrder(); } System.out.println(this); if(this.right != null) { this.right.infixOrder(); } } }
平衡二叉搜索树

如上图所示,平衡二叉搜索树首先是一颗二叉排序树,只不过AVL树是平衡的,左右子树的高度相差不超过1,因此,在查找过程中会比普通二叉排序树效率高。
要创建一颗AVL树,需要弄清楚,当左右子树的高度差大于1的时候该如何处理,分以下三种情况:左旋转、右旋转、双旋转
左旋转

左旋转的条件:右子树的高度-左子树的高度>1 旋转的固定程序:如上图所示
右旋转:
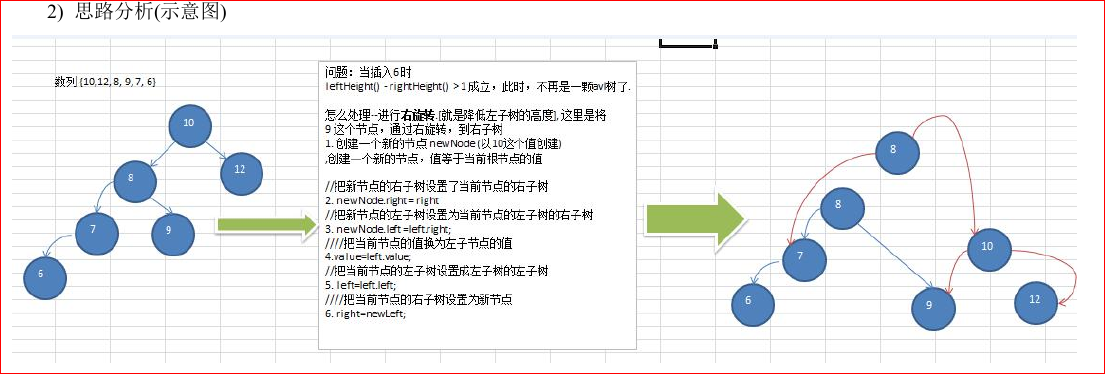
双旋转

代码省略
多路查找树
对于二叉树而言,其只有一个数据项而且最多有两个子节点,如果是海量数据,会造成节点数和高度很大,搜索会造成时间消耗。
改进二叉树的数据结构,重新组织节点,减少树的高度。
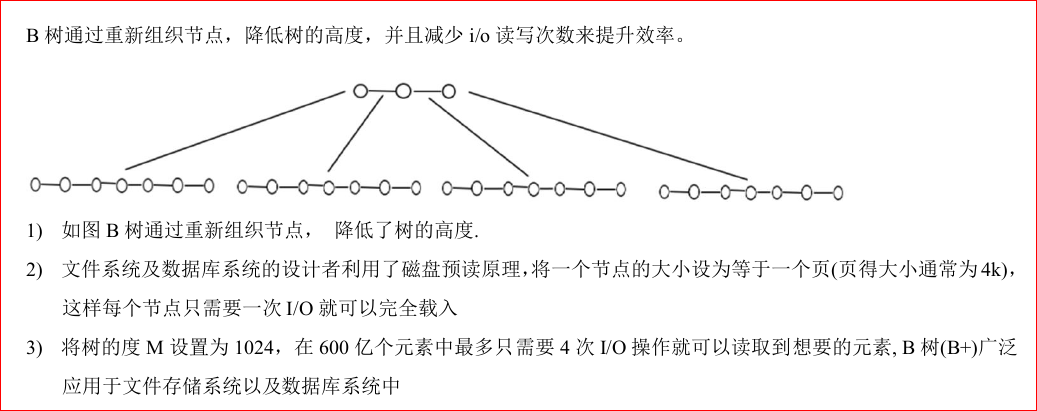
B树
2-3树
满足条件:所有的叶子节点都在同一层;有两个子节点的叫二节点,二节点要么有两个子节点,要么有0个子节点;有三个子节点的叫三节点,三节点要么有三个子节点,要么有0个子节点;
插入规则:

B树的搜索:

B+树
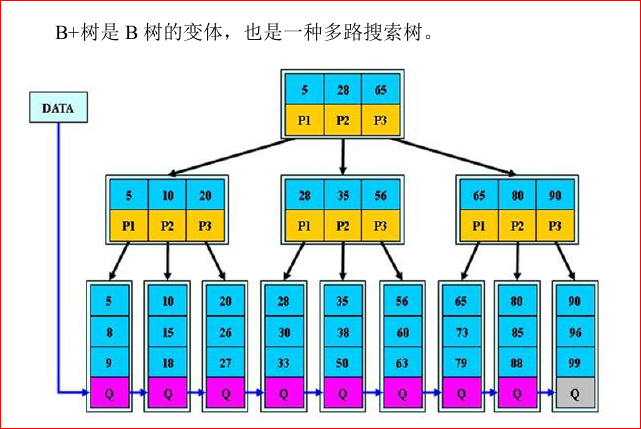

图
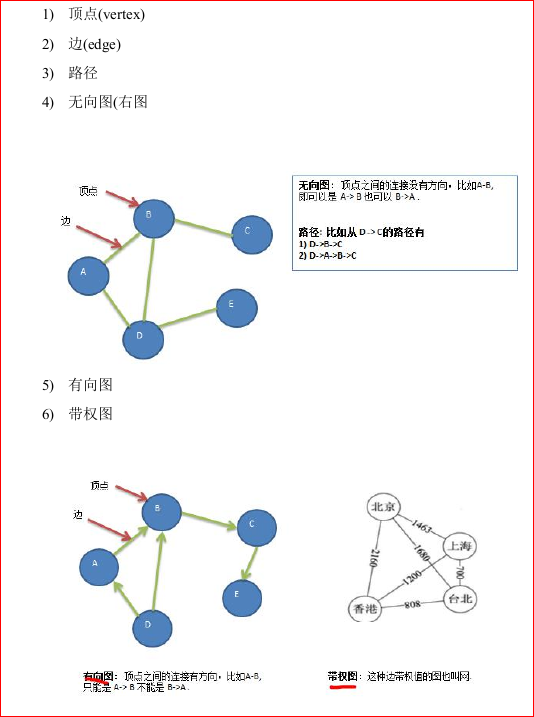
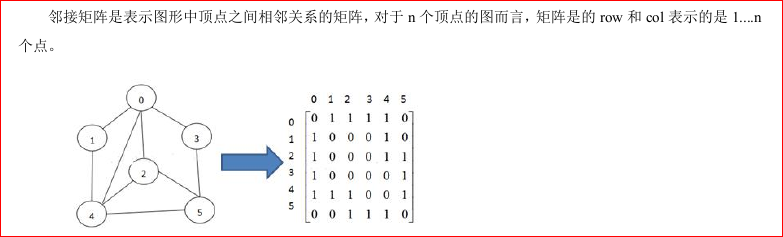
图的表示方式
邻接矩阵:表示图中顶点之间相邻关系的矩阵其中行和列的索引表示顶点,对应的数0表示没有连接,数1表示连接。
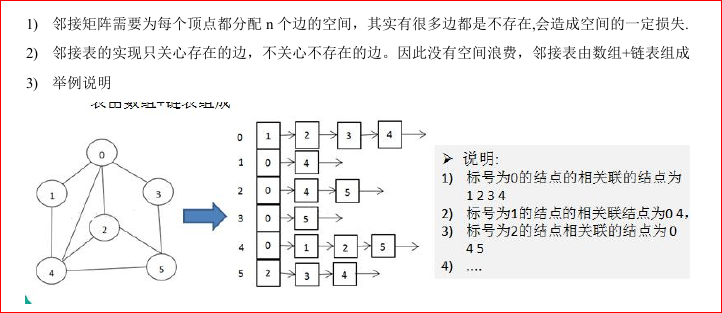
邻接表:
图的深度优先遍历:

代码如下:
package com.liuixnghang.graph; import java.util.ArrayList; import java.util.Arrays; public class Graph { //根据邻接矩阵来实现一个图的深度遍历 private ArrayList<String> vertexList; //存储顶点的集合 private int[][] edges; //存储图对应的邻接矩阵 private int numOfEdges; //表示边的数目 //定义一个数组来记录某个节点是否被访问 private boolean[] isVisited; //构造器 public Graph(int n){ edges=new int[n][n]; vertexList=new ArrayList<String>(n); numOfEdges=0; } public static void main(String[] args) { int n=5; String Vertexs[] = {"A", "B", "C", "D", "E"}; //创建图对象 Graph graph = new Graph(n); for(String vertex : Vertexs){ graph.insertVertex(vertex); } graph.insertEdge(0, 1, 1); // A-B graph.insertEdge(0, 2, 1); // graph.insertEdge(1, 2, 1); // graph.insertEdge(1, 3, 1); // graph.insertEdge(1, 4, 1); // //graph.showGraph(); System.out.println("深度遍历"); graph.dfs(); } //得到第一个临接节点的下标 从第index开始找 public int getFirstNeighbor(int index) { for(int j = 0; j < vertexList.size(); j++) { if(edges[index][j] > 0) { return j; } } return -1; } //从临接节点来获取下一个临接节点 public int getNextNeighbor(int v1, int v2) { for(int j = v2 + 1; j < vertexList.size(); j++) { if(edges[v1][j] > 0) { return j; } } return -1; } //深度优先遍历算法 //i 第一次就是 0 private void dfs(boolean[] isVisited, int i) { //首先我们访问该结点,输出 System.out.print(getValueByIndex(i) + "->"); //将结点设置为已经访问 isVisited[i] = true; //查找结点i的第一个邻接结点w int w = getFirstNeighbor(i); while(w != -1) {//说明有 if(!isVisited[w]) { dfs(isVisited, w); } //如果w结点已经被访问过 w = getNextNeighbor(i, w); } } //对dfs 进行一个重载, 遍历我们所有的结点,并进行 dfs public void dfs() { isVisited = new boolean[vertexList.size()]; //遍历所有的结点,进行dfs[回溯] for(int i = 0; i < getNumOfVertex(); i++) { if(!isVisited[i]) { dfs(isVisited, i); } } } //图中常用的方法 //返回结点的个数 public int getNumOfVertex() { return vertexList.size(); } //显示图对应的矩阵 public void showGraph() { for(int[] link : edges) { System.err.println(Arrays.toString(link)); } } //得到边的数目 public int getNumOfEdges() { return numOfEdges; } //返回结点i(下标)对应的数据 0->"A" 1->"B" 2->"C" public String getValueByIndex(int i) { return vertexList.get(i); } //返回v1和v2的权值 public int getWeight(int v1, int v2) { return edges[v1][v2]; } //插入结点 public void insertVertex(String vertex) { vertexList.add(vertex); } //添加边 /** * * @param v1 表示点的下标即使第几个顶点 "A"-"B" "A"->0 "B"->1 * @param v2 第二个顶点对应的下标 * @param weight 表示 */ public void insertEdge(int v1, int v2, int weight) { edges[v1][v2] = weight; edges[v2][v1] = weight; numOfEdges++; } }
图的广度优先遍历

代码如下:
package com.liuixnghang.graph; import java.util.ArrayList; import java.util.Arrays; import java.util.LinkedList; public class Graph { //根据邻接矩阵来实现一个图的深度遍历 private ArrayList<String> vertexList; //存储顶点的集合 private int[][] edges; //存储图对应的邻接矩阵 private int numOfEdges; //表示边的数目 //定义一个数组来记录某个节点是否被访问 private boolean[] isVisited; //构造器 public Graph(int n){ edges=new int[n][n]; vertexList=new ArrayList<String>(n); numOfEdges=0; } public static void main(String[] args) { int n=5; String Vertexs[] = {"A", "B", "C", "D", "E"}; //创建图对象 Graph graph = new Graph(n); for(String vertex : Vertexs){ graph.insertVertex(vertex); } graph.insertEdge(0, 1, 1); // A-B graph.insertEdge(0, 2, 1); // graph.insertEdge(1, 2, 1); // graph.insertEdge(1, 3, 1); // graph.insertEdge(1, 4, 1); // //graph.showGraph(); // System.out.println("深度遍历"); // graph.dfs(); System.out.println("广度优先!"); graph.bfs(); } //得到第一个临接节点的下标 从第index开始找 public int getFirstNeighbor(int index) { for(int j = 0; j < vertexList.size(); j++) { if(edges[index][j] > 0) { return j; } } return -1; } //从临接节点来获取下一个临接节点 public int getNextNeighbor(int v1, int v2) { for(int j = v2 + 1; j < vertexList.size(); j++) { if(edges[v1][j] > 0) { return j; } } return -1; } //深度优先遍历算法 //i 第一次就是 0 private void dfs(boolean[] isVisited, int i) { //首先我们访问该结点,输出 System.out.print(getValueByIndex(i) + "->"); //将结点设置为已经访问 isVisited[i] = true; //查找结点i的第一个邻接结点w int w = getFirstNeighbor(i); while(w != -1) {//说明有 if(!isVisited[w]) { dfs(isVisited, w); } //如果w结点已经被访问过 w = getNextNeighbor(i, w); } } //对dfs 进行一个重载, 遍历我们所有的结点,并进行 dfs public void dfs() { isVisited = new boolean[vertexList.size()]; //遍历所有的结点,进行dfs[回溯] for(int i = 0; i < getNumOfVertex(); i++) { if(!isVisited[i]) { dfs(isVisited, i); } } } //对一个结点进行广度优先遍历的方法 private void bfs(boolean[] isVisited, int i) { int u ; // 表示队列的头结点对应下标 int w ; // 邻接结点w //队列,记录结点访问的顺序 LinkedList queue = new LinkedList(); //访问结点,输出结点信息 System.out.print(getValueByIndex(i) + "=>"); //标记为已访问 isVisited[i] = true; //将结点加入队列 queue.addLast(i); while( !queue.isEmpty()) { //取出队列的头结点下标 u = (Integer)queue.removeFirst(); //得到第一个邻接结点的下标 w w = getFirstNeighbor(u); while(w != -1) {//找到 //是否访问过 if(!isVisited[w]) { System.out.print(getValueByIndex(w) + "=>"); //标记已经访问 isVisited[w] = true; //入队 queue.addLast(w); } //以u为前驱点,找w后面的下一个邻结点 w = getNextNeighbor(u, w); //体现出我们的广度优先 } } } //遍历所有的结点,都进行广度优先搜索 public void bfs() { isVisited = new boolean[vertexList.size()]; for(int i = 0; i < getNumOfVertex(); i++) { if(!isVisited[i]) { bfs(isVisited, i); } } } //图中常用的方法 //返回结点的个数 public int getNumOfVertex() { return vertexList.size(); } //显示图对应的矩阵 public void showGraph() { for(int[] link : edges) { System.err.println(Arrays.toString(link)); } } //得到边的数目 public int getNumOfEdges() { return numOfEdges; } //返回结点i(下标)对应的数据 0->"A" 1->"B" 2->"C" public String getValueByIndex(int i) { return vertexList.get(i); } //返回v1和v2的权值 public int getWeight(int v1, int v2) { return edges[v1][v2]; } //插入结点 public void insertVertex(String vertex) { vertexList.add(vertex); } //添加边 /** * * @param v1 表示点的下标即使第几个顶点 "A"-"B" "A"->0 "B"->1 * @param v2 第二个顶点对应的下标 * @param weight 表示 */ public void insertEdge(int v1, int v2, int weight) { edges[v1][v2] = weight; edges[v2][v1] = weight; numOfEdges++; } }