本文先叙述如何配置eclipse中maven+scala的开发环境,之后,叙述如何实现spark的本地运行。最后,成功运行scala编写的spark程序。
刚开始我的eclipse+maven环境是配置好的。
系统:win7
eclipse版本:Luna Release(4.4.0)
maven是从EclipseMarket中安装的,如图1。
当初构建eclipse+maven环境时,仅仅安装了第一个。
这里可以先不用急着安装maven,下面在安装maven for scala时,也提供了maven for eclipse。
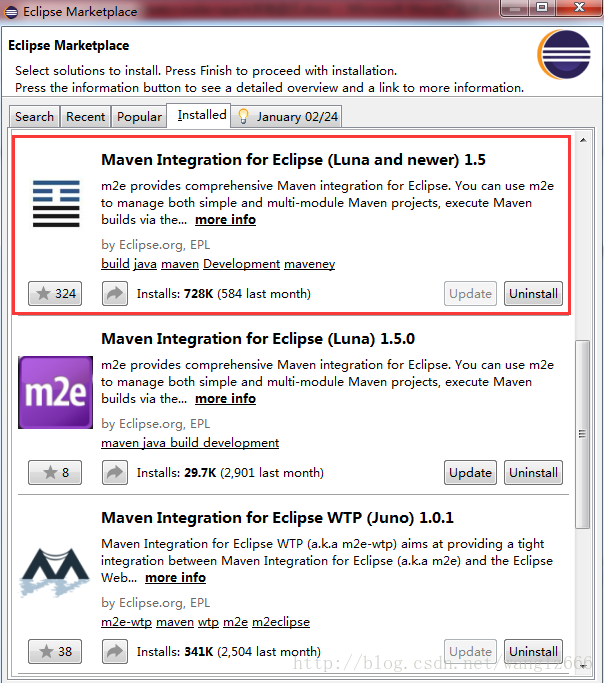
图1-eclipse安装的m2e插件
一、配置eclipse + maven + scala环境
1. 在Eclipse Market中安装Scala IDE
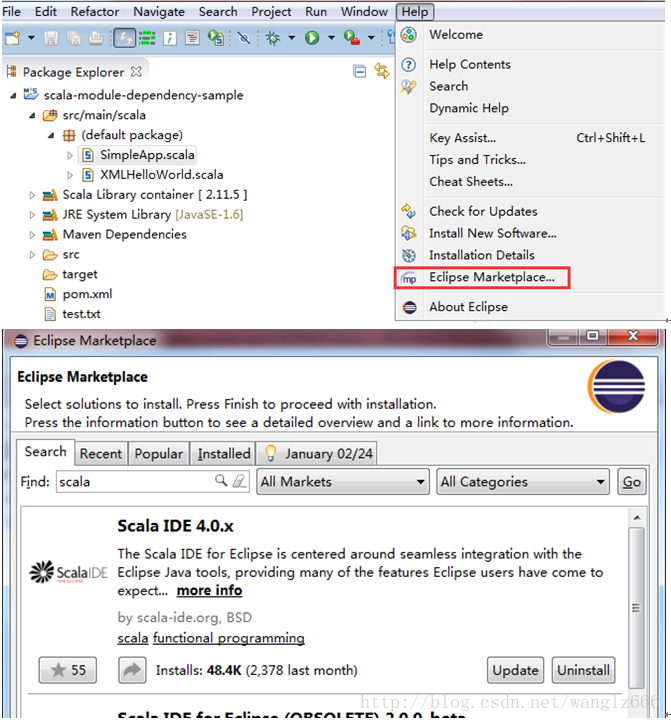
图2-eclipse安装Scala IDE
2. 安装m2e-scala
如图3,图中的url是:http://alchim31.free.fr/m2e-scala/update-site/
从图3中搜索到的插件名称中可以看到,这里同时也配置了m2e,也即eclipse需要的maven插件。如果eclipse没有eclipse插件,则可以全部选中安装;若已经有了可以单独安装第三个Maven Integration for Scala IDE。
安装完成了MavenIntegration for Scala IDE之后,再输入上面的url,可安装列表里就没有Maven Integration for Scala IDE这一项了。
(PS:此处我是将MavenIntegration for Scala IDE卸载了之后重新截图的)
(PS:如果再看图1,除了第一个MavenIntegration for Eclipse(Luna and newer)1.5之外,还有一个MavenIntegration for Eclipse(Luna)1.5.0,。这是我在使用上述 url安装m2e-scala时,没有注意其中还包含了MavenIntegration for Eclipse,导致安装了两个版本的Maven Integration for Eclipse)
(PS:虽然我已经安装上述url中的MavenIntegration for Eclipse,并且并没有卸载,而图3中依然显示了Maven Integration for Eclipse的选项,是因为其版本有了更新。可以从其中看到其最新的版本是1.5.1,此时若继续安装该Maven Integration for Eclipse,则是对版本进行更新。)
(PS:图1中还有一个MavenIntegration for Eclipse WTP(Juno)1.0.1暂时不知道是怎么安装上去的)
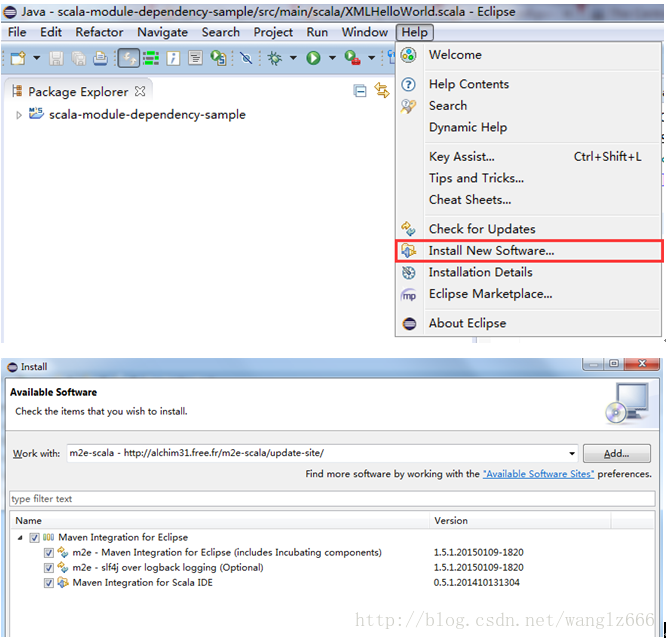
图3-安装m2e-scala
二、测试eclipse+maven+scala的运行环境
1. 先来简单测试一下eclipse+scala
新建一个名为Scala Project,右键工程添加一个名为test的Scala Object,代码如下:
- package test
- object test {
- def main(args : Array[String]) {
- println("hello world")
- }
- }
最终如图4、5所示。
图4-新建scalaproject
、
图5-scala工程目录
右键test.scala,Run as…-> Scala Application,在终端成功输出了hello world。
从图5中可以看到,我们安装的ScalaIDE中自带的scala版本是2.11.5的。
(PS:如果不在终端以命令行的形式使用scala的话,似乎可以不用单独下载scala包并设置环境变量)
2. 再来测试一下ecliipse+scala+maven
本来新建一个scala+maven的流程可以是这样的,如图6所示。
新建maven工程,不勾选Createa simple project,选择与scala有关的archetype。
eclipse的archetype是一种模板,给人的感觉就是其中的目录架构及相关文件(比如说pom.xml)都是按照某种模式(如scala maven)构造好的。如果选择如图6中的1.2版本的scala相关archetype,则新建的maven工程就有了scala maven工程的目录结构,pom.xml也是配置好的,并且还有几个scala的代码文件。
但是,有一些错误,编译无法通过。我想,这主要是因为scala的版本问题,从工程中的pom.xml中可以看到,这个模板是基于scala 2.7.0构建的。而我们安装的scala IDE是基于scala 2.11.5。
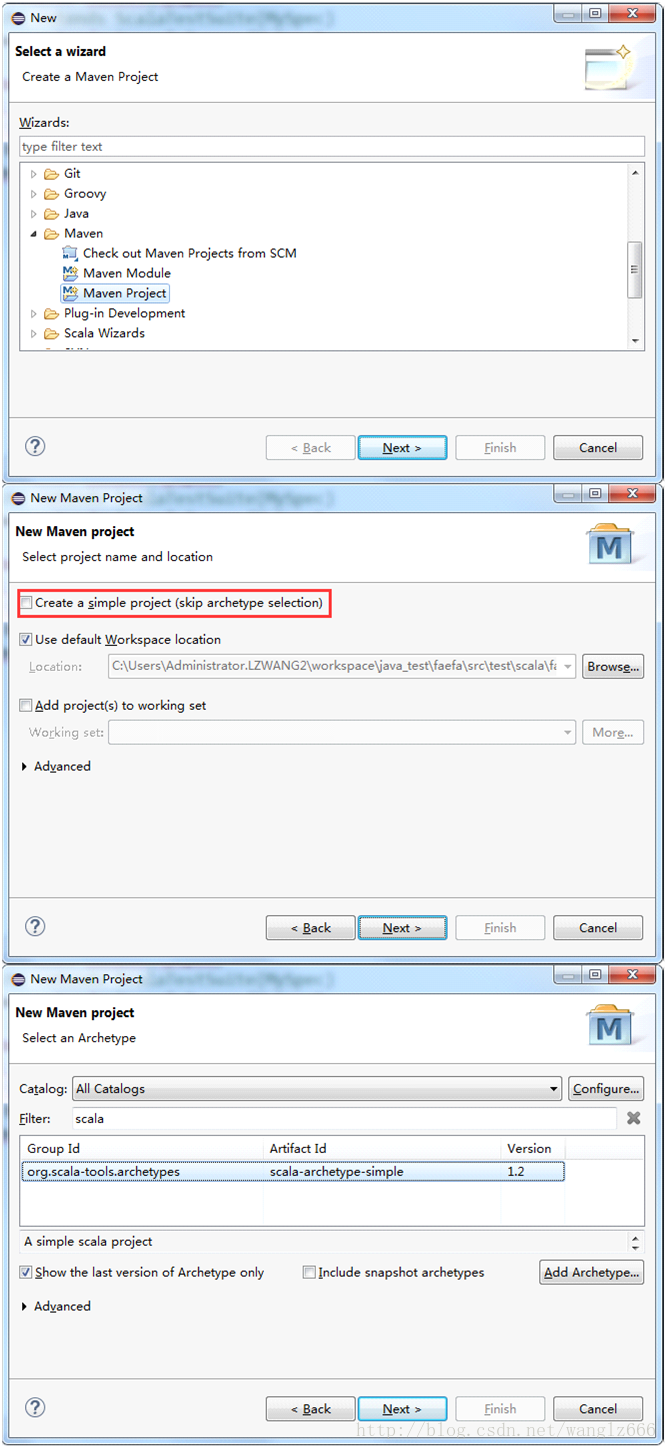
图6-新建scala maven工程
scala的新版本对老版本的兼容似乎并不好。这里可以自己修正pom.xml文件,不过估计代码可能也要修改。
我这里是从git上下载了一个现成的基于scala2.11.5的maven工程。
git网址:https://github.com/scala/scala-module-dependency-sample
使用git clone下来之后,在eclipse中导入maven工程(maven-sample)。
从其pom.xml中可以看到,是基于scala-2.11.5的。其中只有一个代码文件,即是XMLHelloWorld.scala。只要能够顺利的拉取到pom.xml中的依赖包,就可以直接右键XMLHelloWorld.scala, Run as -> Scala Application。
至此,ecipse+scala+maven就搭建好了。接下来配置spark的本地运行环境。
三、配置spark的本地运行
1. 配置所需依赖包
这里我是在maven-sample工程的基础上配置spark的。
在pom.xml中添加spark-core。
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-core_2.11</artifactId>
- <version>1.2.1</version>
- </dependency>
在default package中添加scala object – SimpleApp。代码如下:
- /* SimpleApp.scala */
- import org.apache.spark.SparkContext
- import org.apache.spark.SparkContext._
- import org.apache.spark.SparkConf
- object SimpleApp {
- def main(args: Array[String]) {
- val logFile = "test.txt" // Should be some file on your system
- val conf = new SparkConf().setAppName("Simple Application").setMaster("local[2]")
- val sc = new SparkContext(conf)
- val logData = sc.textFile(logFile, 2).cache()
- val numAs = logData.filter(line => line.contains("a")).count()
- val numBs = logData.filter(line => line.contains("b")).count()
- println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
- }
- }
此时,编译已经通过了,但是如果Run as–> Scala Application的话,会有ClassDefNotFound的异常。
这是因为spark-core其实需要依赖很多其他的jar包来运行,但这些包在spark-core包中并没有,并且在我们的classpath中也没有。
我们可以方便的从在线maven库里找到spark-core包。
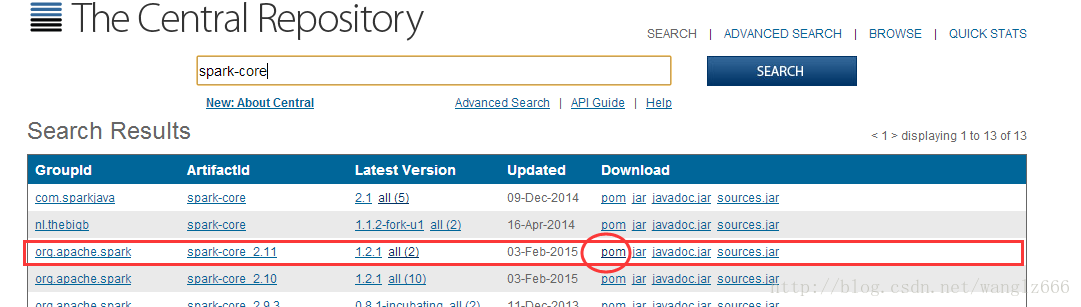
图7-spark-core
我们点击后面的pom链接,可以看到spark-core的pom.xml文件,其中依赖的包很多。
将其中所有的dependency拷贝到我们的maven-sample工程的pom.xml中。重新build工程的时候,需要下载很多包,可能需要很长时间。
(PS:从spark-core的pom.xml文件中可以很直观看到的是,其中org.scala-lang.scala-library组件我们原本已经有了,不过版本稍有不同,可以删掉,也可不删。)
其实,也可自己根据ClassDefNotFound的提示一步步自己添加依赖包,不过,需要添加的可不少。
并且,因为spark-core依赖的众多包,又依赖了其他的包。所以,你可能在根据ClassDefNotFound异常添加依赖包的过程中,发现一些Class所依赖的包在spark-core的pom.xml文件中并未看到。这是因为它们存在于spark-core的依赖包的依赖包中。而且,spark-core的依赖包所依赖的包,还有些版本的冲突,手动添加的过程中,可能还会遇到MethodNotFound的错误。
最简单的方法就是将所有的依赖拷贝过来。
2. 测试运行
现在,我们先在工程目录下配置test.txt文件。

图8-添加test.txt文件
文件内容如下:
- a
- b
- c
- ab
- abab
- d
右键SimpleApp.scala,Run as -> Scala Application,发现打了很多日志。
我也只明白最后一行。
Lineswith a: 3, Lines with b: 3
是spark程序运行的正确输出。
但是可以看到日志中还是有一条异常。
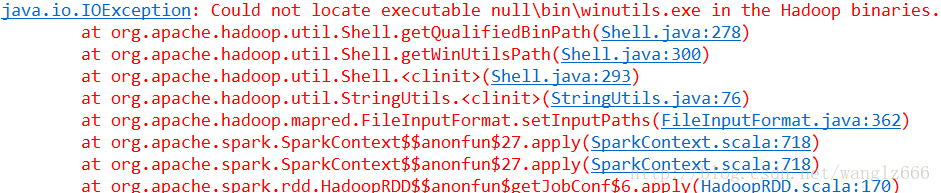
图9-hadoop异常
这条异常似乎并不影响程序的正确运行,不过还是先考虑将该异常解决掉。
有关这个异常可以参考
这个网页的主体内容很简短,意思就是hadoop2.2.0的发布版本对windows的支持并不好。网页中提供了“Build, Install, Configure and Run Apache Hadoop 2.2.0 in MicrosoftWindows OS”的链接,也提供了现成的编译好的包。
我是直接将包下载下来,在工程目录下按照异常提示建立了null/bin目录,并将下载包中的所有文件拷贝进了null/bin目录。
图10-bin目录
接下来,再运行SimpleApp程序,就没有异常了。
但是,这种方法是否本质上解决了该异常就不知道了。因为我发现,即使手动随便建一个null/bin/winutils.exe文件,只要路径及文件名相同,也可以消除上述有关hadoop2.2.0的异常。