前言
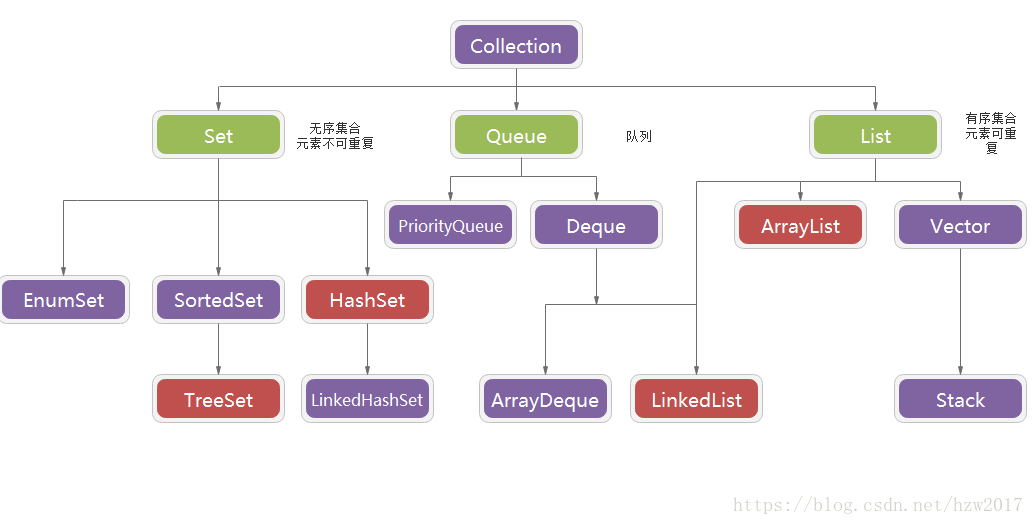
集合只能存储对象,存放的是多个对象的引用,对象本身还是放在堆内存中。
Collections和Arrays工具类:
两个工具类分别操作集合和数组,可以进行常用的排序,合并等操作。
TreeMap和TreeSet:
主要是基于红黑树实现的两个数据结构,可以保证key序列是有序的。
HashMap和HashSet:
基于哈希表实现,支持快速查找。
ArrayList(有序列表,允许存放重复的元素,允许使用null元素)
接口:
List
实现类:
LinkedList,Vector,ArrayList:
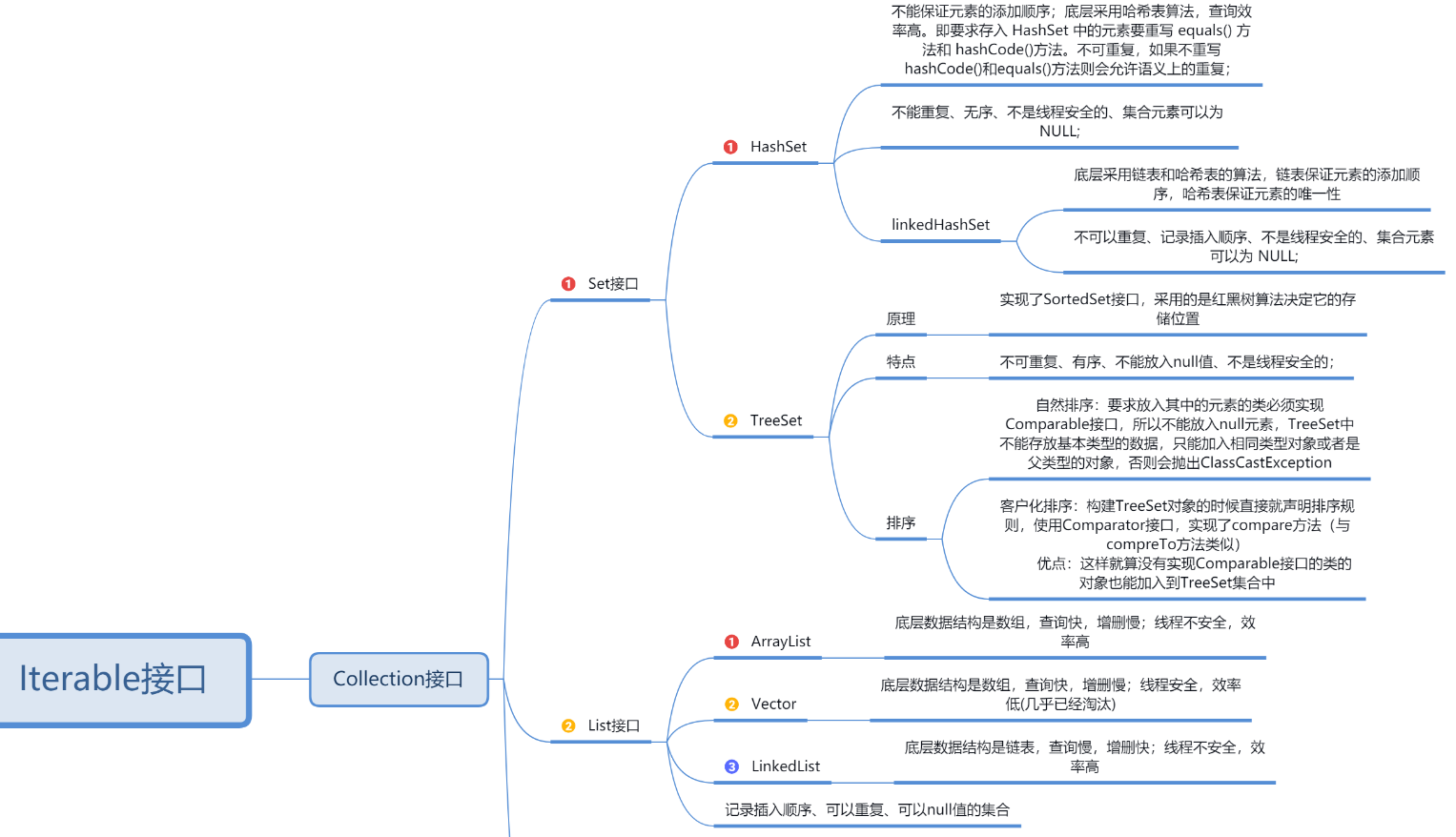
ArrayList:数组实现,查询快,增删慢,轻量级(线程不安全)
LinkedList:双向链表实现,增删快,查询慢,轻量级(线程不安全)
Vector:数组实现,重量级(线程安全、使用少)
ArrayList是实现List接口的动态数组。
同步访问:List list = Collections.synchronizedList(new ArrayList(...));
ArrayList:
继承:
AbstractList抽象父类
实现:
List接口(规定了List的操作规范)
RandomAccess(可随机访问)
Cloneable(可拷贝)
Serializable(可序列化)
ArrayList:
优点:
get(int index) set(int index, E element)与顺序添加( add(E e) )非常快。时间复杂度O(1)
缺点:
插入删除( add(int index, E element) 和 remove(int index) )非常慢,因为涉及元素复制。时间复杂度O(n)
public class ArrayList<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
Vector大部分方法都使用了synchronized修饰符,所以他是线层安全的集合类。
public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
public class Stack<E> extends Vector<E>
LinkedList(有序列表,允许存放重复的元素,允许使用null元素)
LinkedList是采用双向循环链表实现的:
利用LinkedList实现栈(stack)、队列(queue)、双向队列(double-ended queue)。
它具有方法addFirst()、addLast()、getFirst()、getLast()、removeFirst()、removeLast()等。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
LinkedList在插入和删除时更优于ArrayList,而随机访问则比ArrayList差。
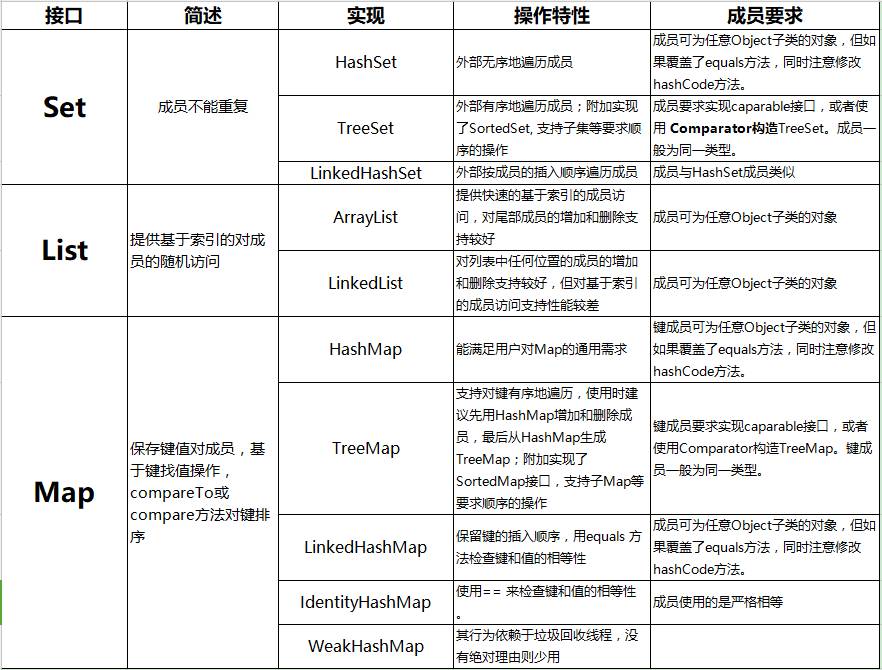
Set(不允许存放重复的元素,允许使用null元素)
接口:Set
实现类:HashSet (无序,查找时间复杂度为O(1) )、LinkedHashSet(有序)
Set的子接口:SortedSet
实现类:TreeSet (排序, 查找时间复杂度O(logN) )
HashSet常用方法:
public boolean contains(Object o); //如果set包含指定元素,返回true
HashSet需要同时通过equals和HashCode来判断两个元素是否相等:
具体规则是,如果两个元素通过equals为true,并且两个元素的hashCode相等,则这两个元素相等(即重复)。
LinkedHashSet本质上也是从LinkedHashMap而来:
LinkedHashSet的所有方法都继承自HashSet, 而它能维持元素的插入顺序的性质则继承自LinkedHashMap。
TreeSet(只允许存入同一类的元素):
TreeSet的排序分两种类型,一种是自然排序,另一种是定制排序:
自然排序(在元素中写排序规则):
TreeSet 会调用compareTo()方法比较元素大小,然后按升序排序。所以自然排序中的元素对象,都必须实现了Comparable接口
定制排序(在集合中写排序规则)
TreeSet 还有一种排序就是定制排序,定制排序时候,需要关联一个 Comparator对象。
总结:
HashSet 的元素存放顺序和我们添加进去时候的顺序没有任何关系。
LinkedHashSet 则保持元素的添加顺序。
TreeSet 则是对我们的Set中的元素进行排序存放。
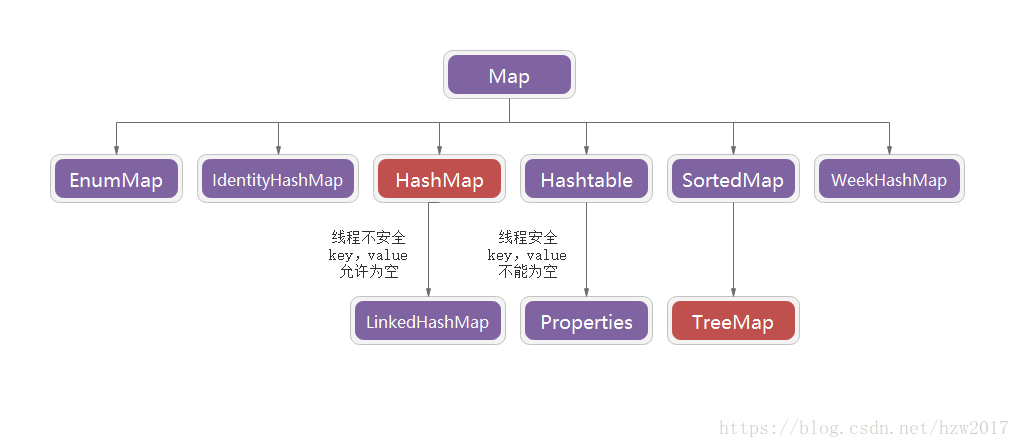
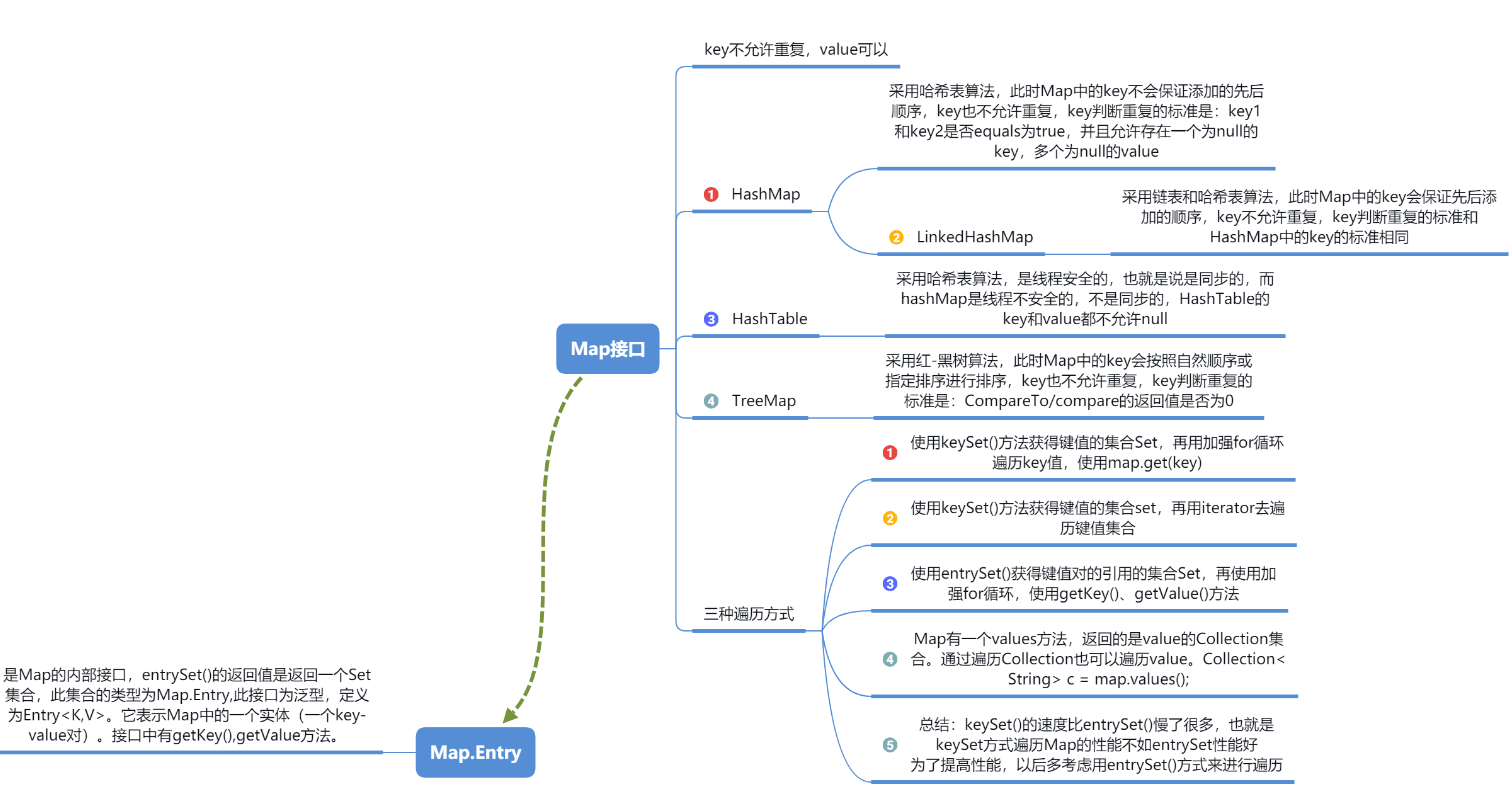
Map(关键字唯一,允许使用null元素)
实现类:
HashMap、TreeMap、LinkedHashMap、Hashtable
HashMap:
键值对,key不能重复,但是value可以重复,允许null的键或值。
Hashtable:
线程安全的,不允许null的键或值。
Properties:
key和value都是String类型,用来读配置文件。
TreeMap:
对key排好序的Map。key要实现Comparable接口或TreeMap有自己的构造器。
LinkedHashMap:
此实现与 HashMap 的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。存储的数据是有序的。
HashMap实现原理:散列
如果负载因子0.75,当散列表中已经有75%位置已经放满,那么将进行再散列。
负载因子越高(越接近1.0),内存的使用效率越高,元素的寻找时间越长。
负载因子越低(越接近0.0),元素的寻找时间越短,内存浪费越多。
Map集合比较:
HashMap 无序。
LinkedHashMap 保留了键值对的存入顺序。
TreeMap 则是对Map中的元素进行排序。
HashMap 和 LinkedHashMap 存储数据的速度比直接使用TreeMap 要快,存取效率要高。
注意:TreeMap中是根据键(Key)进行排序的。
而如果我们要使用TreeMap来进行正常的排序的话,Key中存放的对象必须实现Comparable接口。
Map常用方法:
boolean containsKey(Object key) :判断Map中是否存在某键(key)
boolean containsValue(Object value) :判断Map中是否存在某值(value)
public Set<K> keySet() :返回所有的键(key),并使用Set容器存放
public Collection<V> values() :返回所有的值(Value),并使用Collection存放
public Set<Map.Entry<K, V>> entrySet(); :返回一个实现 Map.Entry 接口的元素 Set
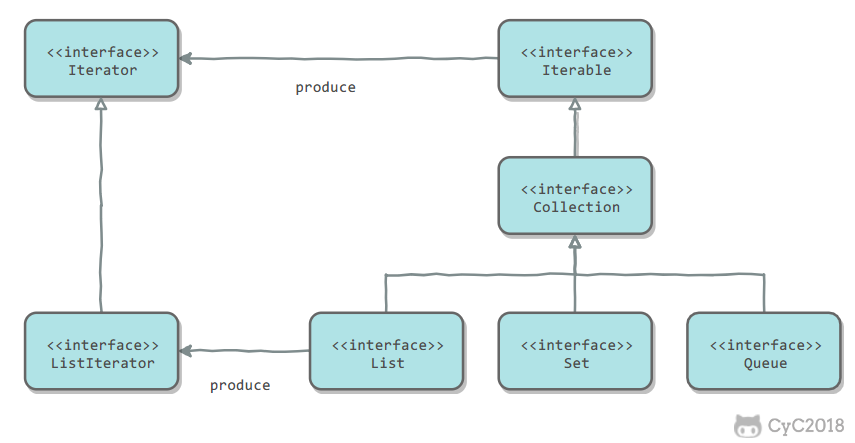
Queue
public interface Queue<E> extends Collection<E> {}
PriorityQueue:底层用数组实现堆的结构
public class PriorityQueue<E>
extends AbstractQueue<E>
implements java.io.Serializable
PriorityQueue不是一个线程安全的类:
如果要在多线程环境下使用,可以使用 PriorityBlockingQueue 这个优先阻塞队列。
其中add、poll、remove方法都使用 ReentrantLock 锁来保持同步,take() 方法中如果元素为空,则会一直保持阻塞。
Deque
public interface Deque<E> extends Queue<E> {}
ArrayDeque:底层使用循环数组实现双向队列
public class ArrayDeque<E>
extends AbstractCollection<E>
implements Deque<E>, Cloneable, Serializable {
transient Object[] elements;
transient int head;
transient int tail;
}
Iterator
Iterator iterator = list.iterator();
while(iterator.hasNext()){
String string = iterator.next();
do something;
}
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {throw new UnsupportedOperationException("remove");}
}
public class ArrayList<E> {
public Iterator<E> iterator() {return new Itr();}
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
}
}
迭代器模式
提供一个对象来顺序访问聚合对象中的一系列数据,而不暴露聚合对象的内部表示。
// 抽象迭代器
interface Iteratoring {
public boolean hasNext();
public Object next();
}
//具体迭代器
class ConcreteIterator implements Iteratoring {
private ArrayList<Object> li;
public ConcreteIterator(ArrayList<Object> li) {
this.li = li;
}
int count = 0;
@Override
public boolean hasNext() {
if (count < li.size()) {
return true;
}
return false;
}
@Override
public Object next() {
if (hasNext()) {
return li.get(count++);
}
return null;
}
}
//抽象聚合
interface Aggregate {
public void add(Object obj);
public void remove(Object obj);
public Iteratoring getIterator();
}
//具体聚合
class ConcreteAggregate implements Aggregate {
private ArrayList arr = new ArrayList();
@Override
public void add(Object obj) {
arr.add(obj);
}
@Override
public void remove(Object obj) {
arr.remove(obj);
}
@Override
public Iteratoring getIterator() {
return new ConcreteIterator(arr);
}
}
Comparable(内比较器,耦合强) 和 Comparator(外比较器)
public interface Comparable<T> {
public int compareTo(T o); //自然比较方法
}
public class Girl implements Comparable<Object> { //可以用Collections.sort() 或者 Arrays.sort() 进行排序
public int compareTo(Object o) {
Girl g = (Girl)o;
return this.age - g.getAge();
}
}
public interface Comparator<T> {
int compare(T o1, T o2);
boolean equals(Object obj);
default Comparator<T> reversed() {
return Collections.reverseOrder(this);
}
}
Comparator<User> byName = (User o1, User o2) -> o1.getName().compareTo(o2.getName());
list.sort((User o1,User o2) -> o1.getAge() - o2.getAge());
Fail-Fast 机制
对应非线程安全的数据结构,使用迭代器在发生线程不安全的操作时会报错。
实现通过 modCount 域(修改次数),对ArrayList 内容的修改都将增加这个值,
那么在迭代器初始化过程中会将这个值赋给迭代器的 expectedModCount。
在迭代过程中,判断 modCount 跟 expectedModCount 是否相等,如果不相等就表示已经有其他线程修改了 ArrayList。
因此,遍历那些非线程安全的数据结构时,尽量使用迭代器
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
asList() 与 subList() 的缺陷
8个基本类型是无法作为asList的参数的,要想作为泛型参数就必须使用其所对应的包装类型。
asList产生的列表不可操作。
subList()返回的只是原列表的一个视图,它所有的操作最终都会作用在原列表上。
对于子列表视图,它是动态生成的,生成之后就不要操作原列表了,否则必然都导致视图的不稳定而抛出异常。
最好的办法就是将原列表设置为只读状态,要操作就操作子列表。
删除100-200位置处的数据:
list.subList(100, 200).clear();