0.安装scrapy框架
pip install scrapy
注:找不到的库,或者安装部分库报错,去python第三方库中找,很详细
https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud
1.创建一个scrapy框架
scrapy startproject 项目名

2.使用scrapy框架爬虫的三个步骤
a.配置items文件,确定需要爬取的字段
b.配置pipeline文件,确定文件的存储方式,并在setting文件中配置管道文件
注:如果存的是json数据,json.dumps(dict(item), ensure_ascii=False)
这里要记得将ensure_ascii置为False,原因是因为默认为ascii编码,但是中文用ascii编码会有问题
c.配置爬虫文件(分为两种,父类为Spider,CrawlSpider)
在终端中进入到项目目录下,执行:
scrapy genspider 爬虫名 限制的域名范围(创建Spider模板)
scrapy genspider -t crawl 爬虫名 限制的域名范围(创建CrawlSpider模板)
3.Spider类的使用
a.三个变量:name(爬虫名), allowed_domains(限定域), start_urls(最先请求的网站)
b.重写parse()方法,方法名必须是这个
c.在函数的最后yield item,会把item交给管道文件处理
d.如果需要再次发送请求的话需要 yield scrapy.Request(url,meta,callback)方法
url:为再次请求的地址
meta:请求携带的内容(字典格式),可以被response.meta取到,用于两个函数之间变量的传递
callback:请求的回调函数
4.CrawlSpider类的使用
a.三个变量(与Spider类一致)
b.rules规则的定义(用于匹配需要爬取的链接内容,且每次请求的页面也遵循这个规则)
优点:比Spider类更简洁,不需要写scrapy.Request()再次发送请求
注:rule规则可以写多条,如第一个规则用于翻页,第二个规则用于匹配当前页内中的链接
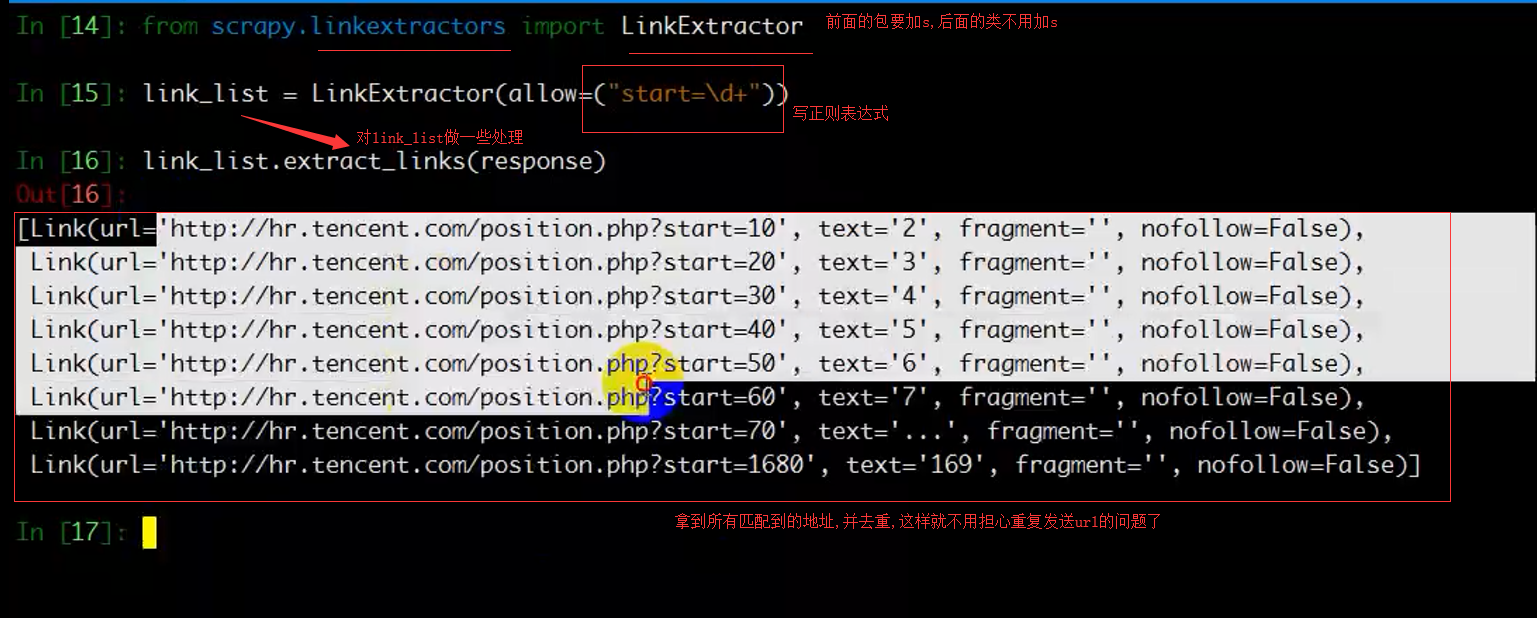
例:rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
allow:代表使用正则来匹配链接
restrict_xpaths:代表使用xpath来匹配链接
restrict_css:代表使用beautifulsoup4来匹配链接

callback:回调函数
follow:是否跟进(如果没有callback,follow默认为True),应用在匹配页码链接时,需要跟进
如果有callback,follow默认为False
注:在使用CrawlSpider时,callback不能再写parse,因为框架使用了parse实现其逻辑,我们在使用时,需要另起一个名字
5.中间件的设置
1.定义User-Agent列表,循环使用

2.如果需要使用代理服务器,需要设置代理,并附上对应的host和账号密码
