注 : 本文中注释因为方便写了# ,mysql中规范应为 --
创建用户
通过root管理员权限可以创建各种用户,并为他们分配权限及可以操作的数据库。
语法:create user '用户名'@'ip地址' identified by '密码'
creata user 'sakura'@'%' identified by '123456';
其中,ip地址可以用通配符%来表示任意地址。
例'%',代表任意ip地址都能链接。
'10.31.160.%',代表以10.31.160开头的ip地址可以链接。
为用户设置权限
grant select,insert,update on db1.t1 to 'sakura'@'%'; # 给用户设置查询,添加,修改的权限,范围为db1库的t1表。 grant all privileges on db1.t1 to 'sakura'@'%'; #给用户设置所有的权限。 revoke all privileges on db1.t1 from 'sakura'@'%'; #移除用户所有的权限。
操作库
create database db2; create database db2 default charset utf8; # 为库设置默认编码格式 show databases; drop database db2; # 删除数据库db2
操作文件
show tables; create table t1( 列名 类型 null, 列名 类型 not null, 列名 类型 not null auto_increment primary key, id int, name char(10) )engine=innodb default charset=utf8; # engine:引擎模式 # innodb 支持事务,原子性操作 # 当实行结果不满足预期时,数据会回滚,不会丢失。 auto_increment 表示:自增 primary key: 表示 约束(不能重复且不能为空); 加速查找;主键 not null: 是否为空
数据类型:
数字:
tinyint 比int范围小,推荐使用,运行速度快
int 整型
bigint 大数字
FLOAT 浮点型,在小数位置长时,结果不一定准确
DOUBLE 双精度,在小数位置长时,结果不一定准确,但比FLOAT准确
decimal 绝对准确,在底层是以字符串实现的数据存储,应用于银行卡余额之类的要求绝对准确的数据。
字符串:
char(10) 速度快,就算只写了3个字符,也会在系统中占10个字符。所以系统在扫描时是知道你的字符长度的,扫描速度快。
varchar(10) 节省空间,写了几个字符就在系统中占了多少字符,但是扫描的速度慢,系统不知道你的字符长度,每次都需要去判断。
PS: 创建数据表定长列往前放,即数据类型为char的列尽量往前放,例如手机号固定为11位,总归是要占11个字符的,用char可以加速系统的扫描速度。
表的基本操作
清空表:
delete from t1; # 只会清空表的内容,不会清空主键(id)的值
truncate table t1; # 清空表的内容,并连同主键(id)的值一并清空
删除表:
drop table t1;
修改表:


添加列:alter table 表名 add 列名 类型 删除列:alter table 表名 drop column 列名 修改列: alter table 表名 modify column 列名 类型; -- 类型 alter table 表名 change 原列名 新列名 类型; -- 列名,类型 添加主键: alter table 表名 add primary key(列名); 删除主键: alter table 表名 drop primary key; alter table 表名 modify 列名 int, drop primary key; 添加外键:alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段); 删除外键:alter table 表名 drop foreign key 外键名称 修改默认值:ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000; 删除默认值:ALTER TABLE testalter_tbl ALTER i DROP DEFAULT;
主键
主键作为一个表中的唯一标识,就像每个人的身份证号码一样,即便删除了表中间的一条数据,也不会引起别的数据id的变化
create table tb1( id int not null auto_increment primary key,#这里给id设置了主键并自增 name char(10), department int, )engine=innodb default charset=utf8;
外键
外键可以通过另一张表来限制本表的数据
为什么要使用外键??用一张图说明
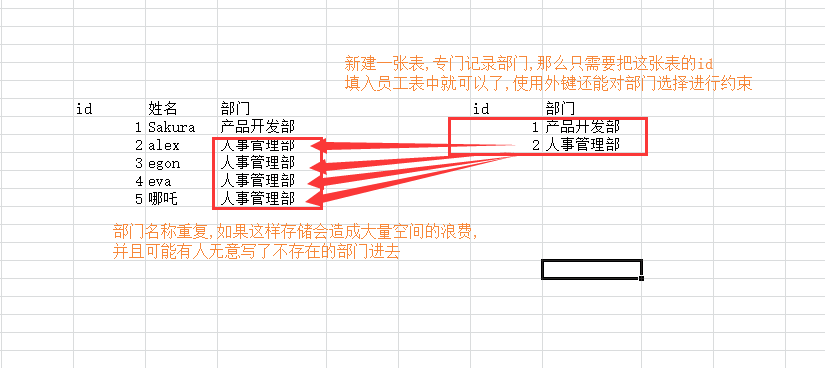
create table t1( id int auto_increment primary key, name char(10), id1 int, id2 int, CONSTRAINT fk_t1_t2 foreign key (id1,id2) REFERENCES t2(nid,pid) # fk_t1_t2表示外键名 把本表的id1,id2受到t2表中的nid,pid限制 )engine=innodb default charset=utf8;
索引
为什么要用索引?
1.索引可以加快查找的速度
2.索引可以限制一个字段的数据不能重复,例如name列中已经有了一个'sakura',那么在后面就不能再写'sakura'
索引可以为空,而主键不能为空
create table t1( id int ...., num int, xx int, unique 唯一索引名称 (列名,列名), constraint .... )
数据行操作

数据查询
select * from tb12; select id,name from tb12; select id,name from tb12 where id > 10 or name ='xxx'; # and not or 用法与python中一致 select id,name as cname from tb12 where id > 10 or name ='xxx'; # as 可以给字段取别名 select name,age,11 from tb12; # 会出现一个整列都是11的列 其他: select * from tb12 where id != 1 select * from tb12 where id in (1,5,12); select * from tb12 where id not in (1,5,12); select * from tb12 where id in (select id from tb11) # ()内也可以放一个查询的结果 select * from tb12 where id between 5 and 12; # 查询id 5-12之间所有的数据 通配符: select * from tb12 where name like "a%" # %可以匹配任意字符任意多个 select * from tb12 where name like "a_" # _只能匹配一个任意字符 分页: select * from tb12 limit 10; # 显示前10项的内容 select * from tb12 limit 0,10; select * from tb12 limit 10,10; # 从第10项开始,显示10项内容 select * from tb12 limit 20,10; # 从第20项开始,显示10项内容 select * from tb12 limit 10 offset 20; # 从第20行开始读取,读取10行; 结合Python分页: # page = input('请输入要查看的页码') # page = int(page) # (page-1) * 10 # select * from tb12 limit 0,10; 1 # select * from tb12 limit 10,10;2 排序: select * from tb12 order by id desc; 大到小 select * from tb12 order by id asc; 小到大 select * from tb12 order by age desc,id desc; 取后10条数据 select * from tb12 order by id desc limit 10; 分组: select count(id),max(id),part_id from userinfo5 group by part_id;
聚合函数: count max min sum avg **** 如果对于聚合函数结果进行二次筛选时 必须使用having
注:where后面不能写聚合函数 select count(id),part_id from userinfo5 group by part_id having count(id) > 1; select count(id),part_id from userinfo5 where id > 0 group by part_id having count(id) > 1; 连表操作:
# 获取两张表内的内容,并排显示 select * from userinfo5,department5 select * from userinfo5,department5 where userinfo5.part_id = department5.id select * from userinfo5 left join department5 on userinfo5.part_id = department5.id select * from department5 left join userinfo5 on userinfo5.part_id = department5.id # userinfo5左边全部显示 # select * from userinfo5 right join department5 on userinfo5.part_id = department5.id # department5右边全部显示 select * from userinfo5 innder join department5 on userinfo5.part_id = department5.id 将出现null时一行隐藏 select * from department5 left join userinfo5 on userinfo5.part_id = department5.id left join userinfo6 on userinfo5.part_id = department5.id select score.sid, student.sid from score left join student on score.student_id = student.sid left join course on score.course_id = course.cid left join class on student.class_id = class.cid left join teacher on course.teacher_id=teacher.tid select count(id) from userinfo5;