对于一个拥有输入层,隐藏层,输出层的三层神经网络,我们称之为shallow learning,它处理输入特征明显的数据效果很好,但对于比较复杂的数据需要引入更多的隐藏层,因为每一个隐藏层可以看作对上一层输出的非线性转换,也就可以学习到更加复杂的模型。
但是单纯的在原来三层网络上曾加隐藏层并没有带来更好的效果,因为层数曾加以后使用梯度下降法优化的是一个高度非凸的优化问题,训练误差很容易陷入局部极值,还有通过反向传导算法计算导数的时候,随着网络深度的增加,反向传导的梯度幅值会急剧减小,使得网络中最初几层的权值在训练过程中调整的幅度非常小,我在使用具体数据实验时,曾加隐藏层的个数对于最终的结果几乎没影响,原因在于,对于深度网络反向传导时主要训练的只是最后的logistic层,对于前面的几层只是进行一些微调。
要解决上述问题我们需要预训练深度网络,即逐层的训练参数,然后把预训练完成的隐藏层级联在一起,在这之前首先介绍自编码器,它是一种无监督学习,通过自编码器计算出的权重已收敛于合理的范围之内,相比之前随机的选择权重明显靠谱很多。
自编码器
自编码神经网络是一种无监督学习算法,它使用反向传播算法训练权重值,比如下图

可以看到输入层与输出层的神经元数量相等,自编码神经网络尝试学习一个  的函数。换句话说,它尝试逼近一个恒等函数,从而使得输出
的函数。换句话说,它尝试逼近一个恒等函数,从而使得输出 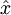 接近于输入
接近于输入 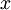 。恒等函数虽然看上去不太有学习的意义,但是当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入
。恒等函数虽然看上去不太有学习的意义,但是当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 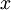 是一张
是一张  图像(共100个像素)的像素灰度值,于是
图像(共100个像素)的像素灰度值,于是 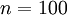 ,其隐藏层
,其隐藏层 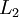 中有50个隐藏神经元。注意,输出也是100维的
中有50个隐藏神经元。注意,输出也是100维的 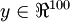 。由于只有50个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从50维的隐藏神经元激活度向量
。由于只有50个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从50维的隐藏神经元激活度向量 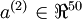 中重构出100维的像素灰度值输入
中重构出100维的像素灰度值输入 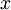 。如果网络的输入数据是完全随机的,比如每一个输入
。如果网络的输入数据是完全随机的,比如每一个输入 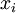 都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。事实上,这一简单的自编码神经网络通常可以学习出一个跟主元分析(PCA)结果非常相似的输入数据的低维表示。
都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。事实上,这一简单的自编码神经网络通常可以学习出一个跟主元分析(PCA)结果非常相似的输入数据的低维表示。
如果中间隐藏层是线性转换,那么n个隐藏神经元就相当于输入数据映射到最明显的n个主元,而如果是非线性转换,比如使用sigmoid激活函数,那么自编码器就与PCA有所不同,特别是当多个自编码器级联在一起构成深度网络的时候必须用非线性转换来求激活值。
我们还可以在自编码器上加上稀疏性的约束条件,一般来讲数据稀疏更有利于表达数据的特性,如果神经元输出接近于1,我们就认为是被激活的,接近于0就认为是被抑制的,要使数据尽量稀疏就要使被抑制的值远多于被激活的值。我们在原来的优化函数中加上稀疏性的惩罚项如下。
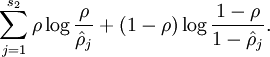
式子中 是个比较小的常量值(比如0.05),
是个比较小的常量值(比如0.05),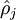 是第j个神经元的激活度,上面的惩罚项将对于两个值有明显差异的情况进行惩罚,从而使
是第j个神经元的激活度,上面的惩罚项将对于两个值有明显差异的情况进行惩罚,从而使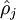 逐渐靠近
逐渐靠近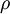 。
。
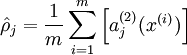
为了使隐藏层发掘出更具泛化能力的特性和防止过拟合,以一定比例清零输入数据,称作去噪自编码,它根据去噪后的数据编码,再重构出输入数据。可以理解为识别出被部分遮挡的某个物体。
具体实例:
首先输入原始数据记为x,训练完成后得到特征一与特征二 。
。


最后级联训练完的两个隐藏层和softmax层,构成一个完整的自编码网络,使用反向传播算法微调整个模型。

