几乎所有人的第一个程序是从“hello,world”程序开始学习的
#include "mpi.h" #include <stdio.h> int main(int argc, char* argv[]) { int rank, numproces; int namelen; char processor_name[MPI_MAX_PROCESSOR_NAME]; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank);//获得进程号 MPI_Comm_size(MPI_COMM_WORLD, &numproces);//返回通信子的进程数 MPI_Get_processor_name(processor_name, &namelen); fprintf(stderr, "hello world! process %d of %d on %s ", rank, numproces, processor_name); MPI_Finalize(); return 0; }
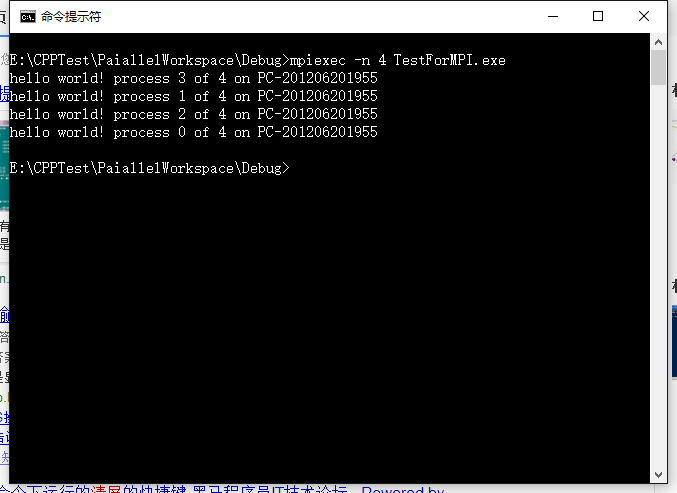
上述代码中,第1行中的#include "mpi.h" 头文件必须包含,在VS2015下编译生成exe文件(生成在debug文件中),通过cmd命令,进入debug文件夹目录中,敲入:mpiexec –n 4 TestForMPI.exe。其中命令中-n 4 表示使用4个进程进行并行计算,具体结果如图所示:
开始理论知识
通过上述的例子,我们对MPI编写的并行计算有了一个初步的认识,但是我们还不知道如何去真正编写一个MPI的并行程序,这需要我们学习一定的理论知识。在上面的例子中,有几个函数对于初学MPI的人来说并不明白是什么意思,下面就从这些函数入手。
MPI_Init:告知MPI系统进行所有必要的初始化设置。它是写在启动MPI并行计算的最前面的。具体的语法结构为:
MPI_Init( int* argc_p, char*** argv_p );
参数argc_p和argv_p分别指向main函数中的指针参数,为了弄明白这部分,还得从main函数的参数说起:C语言规定main函数的参数只能有两个,习惯上这两个参数写为argc和argv。因此,main函数的函数头可写为: main (argc,argv)。C语言还规定argc(第一个形参)必须是整型变量,argv( 第二个形参)必须是指向字符串的指针数组。其中argc参数表示了命令行中参数的个数(注意:文件名本身也 算一个参数),argc的值是在输入命令行时由系统按实际参数的个数自动赋予的。例如有命令行为: C:">E6 24 BASIC dbase FORTRAN由于文件名E6 24本身也算一个参数,所以共有4个参数,因此argc取得的值为4。argv参数是字符串指针数组,其各元素值为命令行中各字符串(参数均按字符串处 理)的首地址。
然而在MPI_Init函数中,并不一定都需要设置argc_p和argv_p这两个参数的,不需要的时候,将它们设置为NULL即可。
通讯子(communicator):MPI_COMM_WORLD表示一组可以互相发送消息的进程集合。
MPI_Comm_rank:用来获取正在调用进程的通信子中的进程号的函数。
MPI_Comm_size:用来得到通信子的进程数的函数。
这两个函数的具体结构如下:
int MPIAPI MPI_Comm_rank( __in MPI_Comm comm, __out int* rank ); int MPIAPI MPI_Comm_size( __in MPI_Comm comm, __out int* size );
它们的第一个参数都传入通信子作为参数,第二参数都用传出参数分别把正在调用通信子的进程号和通信的个数。
MPI_Finalize:告知MPI系统MPI已经使用完毕。它总是放到做并行计算的功能块的最后面,在此函数之后就不能再出现任何有关MPI相关的东西了。
以上只是表达了作为一个MPI并行计算的基本结构,并没有真正涉及进程之间的通信,为了更好的进行并行,必然需要进程间的通信,下面介绍两个进程间通信的函数,它们就是MPI_Send和MPI_Recv,分别用于消息的发送和接收。
MPI_Send:阻塞型消息发送。其结构为:
int MPI_Send (void *buf, int count, MPI_Datatype datatype,int dest, int tag,MPI_Comm comm)
参数buf为发送缓冲区;count为发送的数据个数;datatype为发送的数据类型;dest为消息的目的地址(进程号),其取值范围为0到np-1间的整数(np代表通信器comm中的进程数) 或MPI_PROC_NULL;tag为消息标签,其取值范围为0到MPI_TAG_UB间的整数;comm为通信器。
MPI_Recv:阻塞型消息接收。
int MPI_Recv (void *buf, int count, MPI_Datatype datatype,int source, int tag, MPI_Comm comm,MPI_Status *status)
参数buf为接收缓冲区;count为数据个数,它是接收数据长度的上限,具体接收到的数据长度可通过调用MPI_Get_count函数得到;datatype为接收的数据类型;source为消息源地址(进程号),其取值范围为0到np-1 间的整数(np代表通信器comm 中的进程数),或MPI_ANY_SOURCE,或MPI_PROC_NULL;tag为消息标签,其取值范围为0到MPI_TAG_UB间的整数或MPI_ANY_TAG;comm为通信器;status返回接收状态。
MPI_Status:返回消息传递的完成情况。数据结构的相关变量的意义就比较多了,具体可以参数使用手册。
typedef struct { ... ... int MPI_SOURCE; /*消息源地址*/ int MPI_TAG; /*消息标签*/ int MPI_ERROR; /*错误码*/ ... ... } MPI_Status;
通过编写程序来实现数据积分中的梯形积分法。
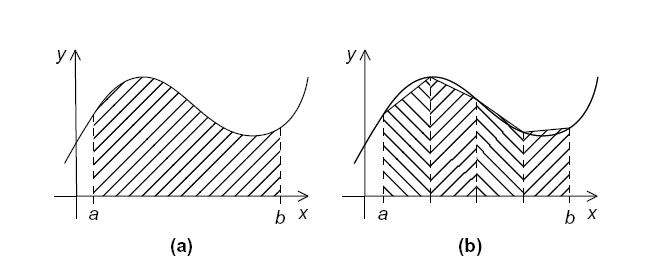
梯形积分法的基本思想是:将x轴上的区间划分为n个等长的子区间。然后计算子区间的和。
假设子区间的端点为xi和xi+1,那么子区间的长度为:h=xi+1-xi。那么梯形的面积就为:
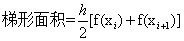
由于n个子区间是等分的,边界分别为xi=a和x=b,则:

这片区域的所有梯形的面积和为:

变换为:

因此,串行的程序代码就可以这样写:
h = (b - a) / h; approx = (f(a) + f(b)) / 2; for (int i = 1; i < n-1; i++) { x_i = a + i*h; approx += f(x_i); } approx = h*approx;
通过对串行程序的分析,对于这个例子,我们可以识别出两种任务:第一种获取单个矩形区域的面积,另一种是计算这些区域的面积和。

假设求f(x)=x3将梯形划分为1024个子区域计算[0,3]区域内的积分。
#include "mpi.h" #include <stdio.h> #include <cmath> double Trap(double left_endpt, double right_endpt, double trap_count, double base_len); double f(double x); int main(int argc, char* argv[]) { int my_rank = 0, comm_sz = 0, n = 1024, local_n = 0; double a = 0.0, b = 3.0, h = 0, local_a = 0, local_b = 0; double local_int = 0, total_int = 0; int source; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); MPI_Comm_size(MPI_COMM_WORLD, &comm_sz); h = (b - a) / n; /* h is the same for all processes */ local_n = n / comm_sz; /* So is the number of trapezoids */ local_a = a + my_rank*local_n*h; local_b = local_a + local_n*h; local_int = Trap(local_a, local_b, local_n, h); if (my_rank != 0) { MPI_Send(&local_int, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD); } else { total_int = local_int; for (source = 1; source < comm_sz; source++) { MPI_Recv(&local_int, 1, MPI_DOUBLE, source, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); total_int += local_int; } } if (my_rank == 0) { printf("With n = %d trapezoids, our estimate ", n); printf("of the integral from %f to %f = %.15e ", a, b, total_int); } MPI_Finalize(); return 0; } //子区域的积分函数 double Trap(double left_endpt, double right_endpt, double trap_count, double base_len) { double estimate = 0, x = 0; int i; estimate = (f(left_endpt) + f(right_endpt)) / 2.0; for (i = 1; i <= trap_count - 1; i++) { x = left_endpt + base_len; estimate += f(x); } estimate = estimate*base_len; return estimate; } //数学函数 double f(double x) { return pow(x, 3); }
上述代码中,运行结果:

这段程序代码中的意思是,通过输入的进程数,将1024个划分的子区间等分的分配到控制台输入的进程(100个)进行子任务求解,求解完成之后,1-99进程计算的结果值通过MPI_Send函数发送出去,而0号进程使用MPI_Recv函数接收汇总,将每个进程的结果求和,得到区间的积分值。
本次并行计算消息之间的通信如下图:

至此,我们已经能使用MPI_Send消息发送函数和MPI_Recv消息接收函数进行简单的并行程序计算了,但最后的求和都是用号进程去做。