写在前面的话,
.......写个P,直接上效果图。附上源码地址 github/lonhon
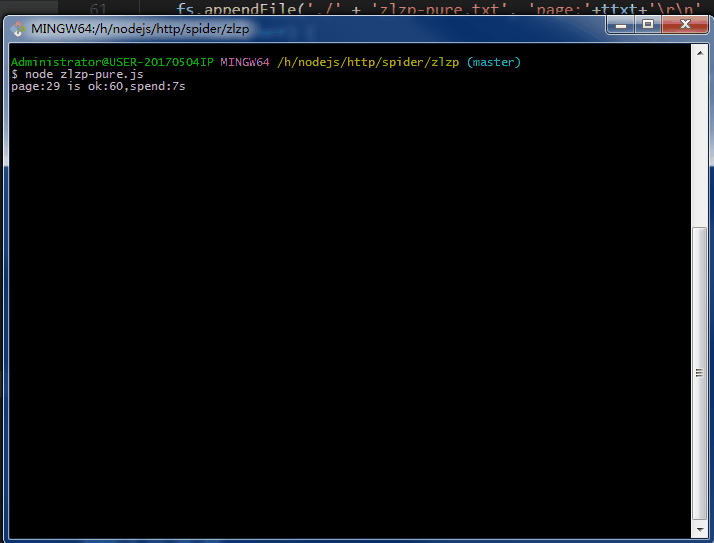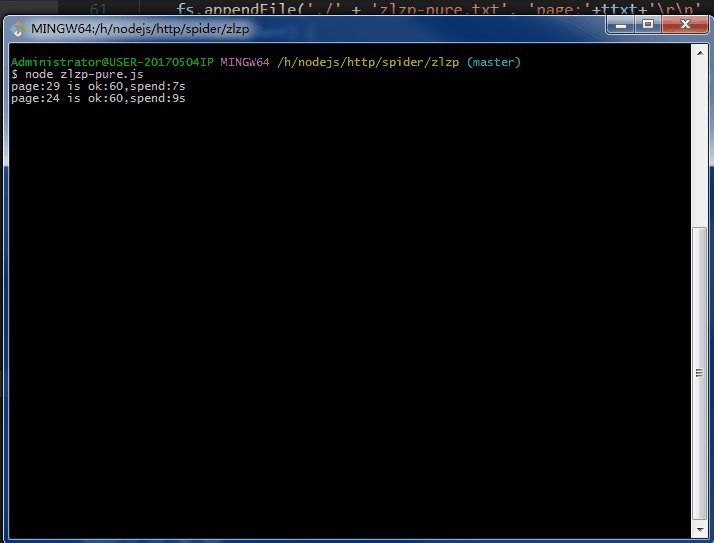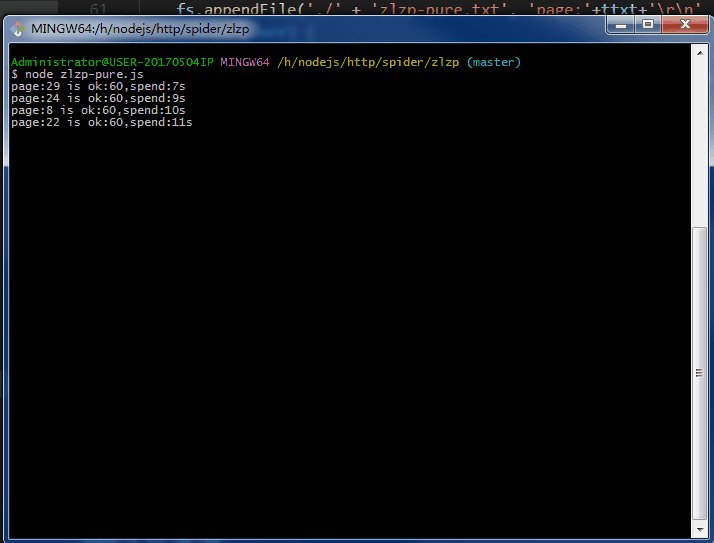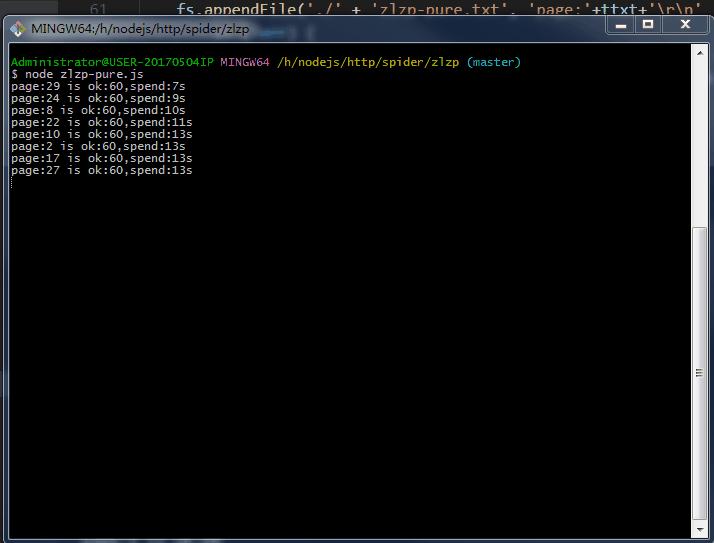
ok,正文开始,先列出用到的和require的东西:
- node.js,这个是必须的
- request,然发送网络请求更方便
- bluebird,让Promise更高效
- cheerio,像jQuery一样优雅的解析页面
- fs,读写本地文件
- 之前写的代理ip的爬取结果,代理池
由于自己的比较偏好数据方面,之前一直就想用python做一些爬虫的东西,奈何一直纠结2.7还是3.x(逃...
上周在看慕课网上的node教程,就跟着课程敲了一次爬虫,从慕课网上的课程开始入手,然后就开始了愉快的爬虫之路。
这两周的爬取路程如下:
慕课网所有课程含章节列表-->拉勾网招聘信息-->xiciIP的代理ip-->boss直聘招聘信息-->个人贴吧回帖记录-->最后就是这次准备讲的智联招聘的爬虫代码。
智联其实一共写了两次,有兴趣的可以在源码看看,第一版的是回调版,只能一次一页的爬取。现在讲的是promise版,能够很好的利用node的异步,快速爬取多个页面。
先贴出源码,在线地址可以在文首获取
"use strict";
var http = require('http')
var cheerio = require('cheerio')
var request = require('request')
var fs = require('fs')
var Promise = require('bluebird')//虽然原生已经支持,但bluebird效率更高
var iplist = require('../ip_http.json') //代理池
//发送请求,成功写入文件,失败换代理
var getHtml = function (url,ipac,ppp) {
return new Promise(function(resolve,reject){
if (ipac >= iplist.length){
console.log('page:'+ppp+'all died'); //代理用完,取消当前页面ppp的请求
reject(url,false);
}
let prox = { //设置代理
url: url,
proxy: 'http://' + iplist[ipac],
timeout: 5000,
headers: {
'Host': 'sou.zhaopin.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36'
}
};
request(prox, function (err, res, body) {
if (err) {
reject(url)//失败,回传当前请求的页面url
} else {
resolve(body, url)//成功回传html和url
}
})
})
}
//解析doc
function filterHtml(html,p,noww){
let res = [];//存放结果集
var $ = cheerio.load(html);
if($('title').text().indexOf('招聘') === -1) { //根据title判断是否被代理重定向
iplist.splice(noww[2],1); //删除假代理。
return lhlh(noww[0],noww[1],noww[2]+1);
}
$('.newlist').each(function(item){
res.push({
zwmc: $(this).find('.zwmc').find('div').text().replace(/s+/g,"").replace(/
/g,''),
gsmc: $(this).find('.gsmc').find('a').eq(0).text().replace(/s+/g,"").replace(/
/g,''),
zwyx: $(this).find('.zwyx').text().replace(/s+/g,"").replace(/
/g,''),
gzdd: $(this).find('.gzdd').text().replace(/s+/g,"").replace(/
/g,''),
gxsj: $(this).find('.gxsj').find('span').text().replace(/s+/g,"").replace(/
/g,'')
})
})
res.shift();//删除表头行
if(res.length < 60){
return lhlh(noww[0],noww[1],noww[2]+1);
}
return creatfile(res,p);
}
//写入本地
function creatfile(list,page) {
var ttxt = 'page:' + page + '
';//每页标题
list.forEach(function(el) { //遍历数据为文本
ttxt += el.zwmc + ','+ el.gsmc + ','+ el.zwyx + ','+ el.gzdd + ','+ el.gxsj + '
';
});
fs.appendFile('./' + 'zlzp-pure.txt', 'page:'+ttxt+'
' , 'utf-8', function (err) {
if (!err) {
let currTime = Math.round((Date.parse(new Date()) - startTime) / 1000);
console.log('page:' + page +' is ok:' +list.length + ',spend:' + currTime + 's' ); // page:1 is ok
}
})
}
//请求封装为promise
function lhlh(url,page,ipac){
getHtml(url,ipac,page).then((html,oldurl)=>{
let noww= [url,page,ipac]
filterHtml(html,page,noww);
})
.catch((url,type = true)=>{
if(type){
ipac += 1;
lhlh(url,page,ipac);
}
})
}
var target = 'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%e6%88%90%e9%83%bd&kw=web%e5%89%8d%e7%ab%af&isadv=0&sg=8cd66893b0d14261bde1e33b154456f2&p=';
let ipacc = 0;
var startTime = Date.parse(new Date());
for(let i=1; i<31; i++){
let ourl = target + i;
lhlh(ourl, i, 0);
}
现在说说本次爬虫的流程:
- 循环请求爬取的页面,这里通过target和循环变量i,拼装请求链接ourl;这里由于请求的是http协议链接,所以用的http的代理,如果是https,则切换为https代理池文件。
- 进入lhlh方法,这里是对实际发送网络请求的getHtnl方法做一个Promise的调用,也是通过递归该方法实现代理ip的切换。
- getHtml方法,首先是对代理池是否用完做一个判断,如果溢出则终止对当前页面的爬取,然后是配置request的option+代理的设置,然后return一个promise
- filterHtml方法,对请求回来的页面做解析,提取所需的数据
- createfile方法,实现数据的本地存储
接下来具体解析
1、怎么发送请求?
for(let i=1; i<31; i++){
let ourl = target + i;
lhlh(ourl, i, 0);
}
包括头部的require、生成url、使用循环发送请求,因为request是一个异步操作,所以这里需要将url和当前请求页面page
在调用lhlh方法的时候还传入了一个0,这是一个代理池的初始值。
2.lhlh方法做了什么?
lhlh函数体内主要是对getHtml方法返回的Promise做成功和失败的处理,逻辑上是:
成功-->调用filterHtml,并传入请求结果
失败-->根据type判断异常情况 ①切换代理,重新请求 ②代理用完,取消本页请求
另外,对传入进来的url、page、代理池下标做一个闭包,传入每次的请求中
3.主角——getHtml方法,返回Promise
在一开始做一个判断,代理池是否溢出,溢出就抛出reject,
生成请求option,主要配置了代理池和Headers,目的也是为了解决网站的反爬。
接下来就是把请求发送出去,发送请求意味着有两种结果:
成功-->返回response,进行下一步解析
失败-->返回当前请求的url
4.filterHtml对response解析
这里就需要结合页面结构进行代码的编写了,先看看我们要请求的页面长什么样子:
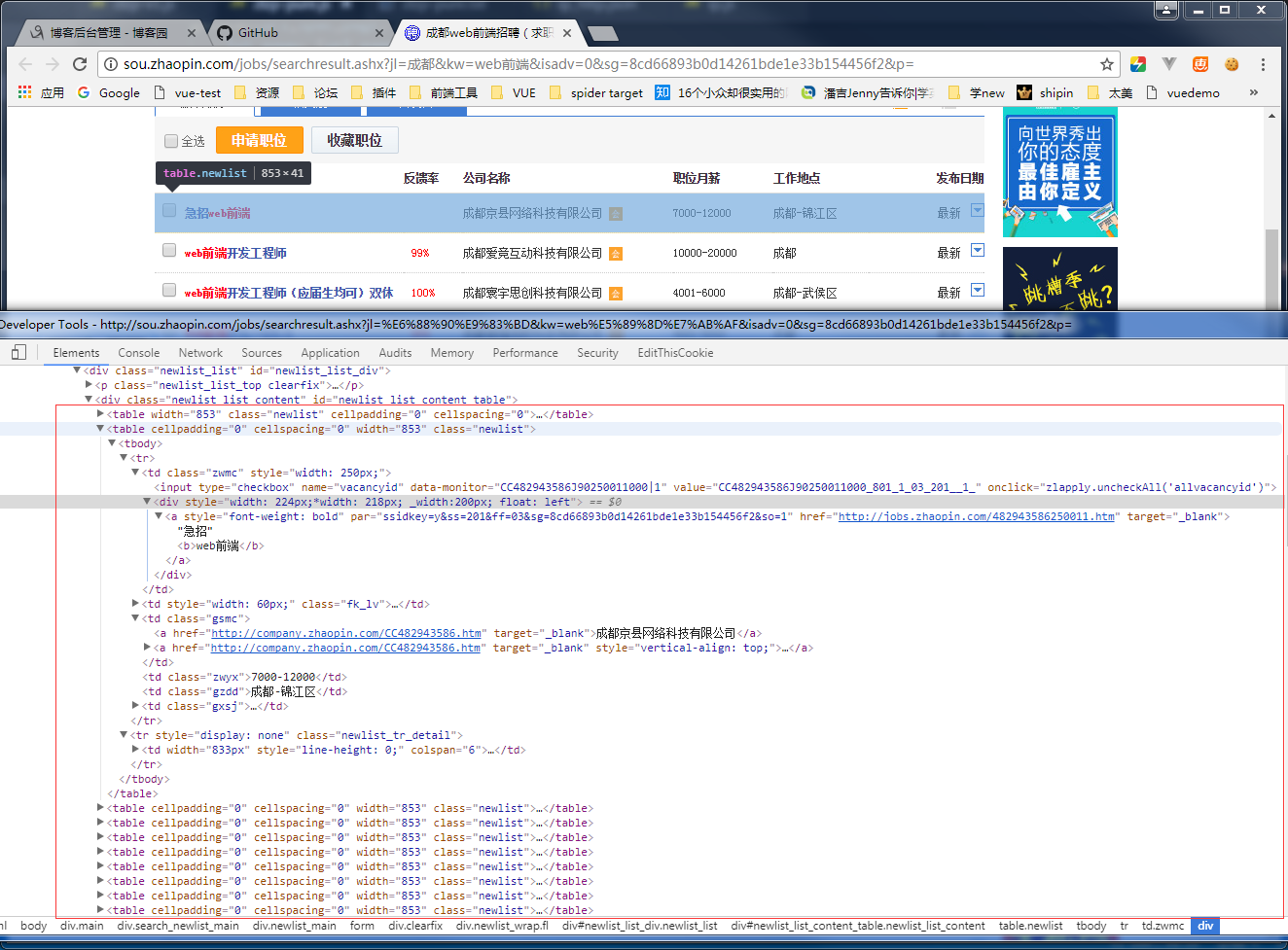
用chrome的开发工具可以很容易看到招聘数据是放在一个class=“newlist”的table中,再结合cheerio,能够很优雅的对页面中的dom进行提取
步骤就是遍历table取出数据,然后push到result中
ps:
①其实这里还能够提高代码质量和效率的,就是直接生成创建txt文件所需的文本,这样就少了对数据的一次遍历,但是为了易于理解过程,还是push到result中传出了。
②红框中的第一个table其实是放表头的,并没有实际数据,所以代码中用了result.shift()删除了第一个元素
5.本地保存爬回来的数据
对传入的参数也就是上一步的result进行遍历,生成创建txt文件所需的字符串。
通过fs.appendFile方法就可以创建本地文件了 ,格式为:fs.appendFile 具体的用法可以百度一下。
最后在生成txt文件后打印了当前页流程走完的提示信息和所消耗的时间
PS: ①.这里其实应该存入本地数据库or生成表格文件(将数据结构化),但是由于需要搭建数据库环境or引入新的模块,故生成的是txt文件。另在createflie中遍历生成ttxt时候,我在不同数据之间插入的分隔符“,”,这样可以方便的导入到表格or数据库中
②fs.appendFile之类的文件操作是异步的。从实际情况考虑,由于每次写入的内容不同和磁盘读写性能的影响,也注定fs的文件操作是一个异步过程。
惯例总结
promise的目的1:把异步需要回调的东西放在异步操作外面,让js不再面条化,比如:
function c(val){
//本函数功能需要b的返回值才能实现
} function b(){ 放一些异步操作,返回 Promise } function a(){ 调用异步方法b b().then(function(val:resolve的返回值){ 这时候就可以直接使用c(val) 使用原来的回调函数就必须把c方法放在async方法中执行,当回调过多的时候函数调用就会变成a(b(c(d(e(f(...)))))),层层嵌套 而使用Promise函数调用就可以扁平为a()->b()->c()...,特别是当理解了Promise的运行步骤后, }) }
promise缺点:性能上和回调函数比较会逊色一些,这也是本次爬虫在node.js v-7.10.0完美实现promise的情况下还引入bluebird的主要原因。
闭包:闭包实现了面向对象中的封装。
异步操作的时候通过闭包可以获取同一个变量,而不会改变其它线程在使用的变量,这也是js实现私有变量的 比如本次爬虫中每次filterHtml解析网页完成后的结果集res,如果放在外层,则会被正在运行的其它异步操作影响,导致传入creatfile的res被影响, 再比如每次爬取的page,如果取for循环里面的i,那最后得到的是i最后的值,所以需要将i传入方法,通过闭包实现每次输出到txt文件的page是当前爬取的page。 当异步函数A、B同时在运行时, 异步A 异步B 00:01 A=1 00:02 A=2 00:03 A===2 */
原创自:http://www.cnblogs.com/lonhon/p/7502893.html