啥是大数据?问啥要学大数据?

在我看来大数据就很多的数据,超级多,咱们日常生活中的数据会和历史一样,越来越多!!!
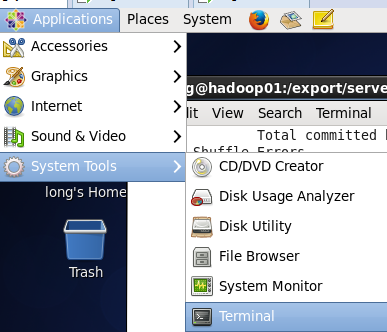
4.查看网段,从编辑-虚拟网络编辑器查看,改虚拟机网段,我的是192.168.189.128-254(这个你根据自己的虚拟机配置就行,不用和我一样,只要记住189.128这个段就行)
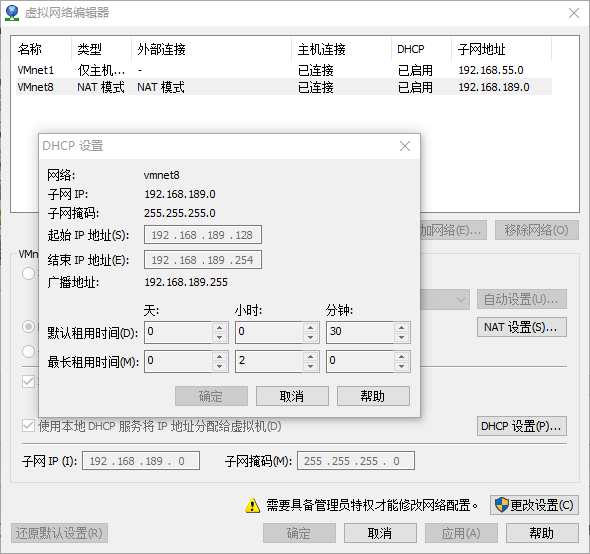
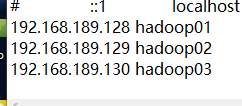
5.添加映射关系,输入:vim /etc/hosts
打开文件后下面添加 192.168.189.128 hadoop01 (红色部分就是你们上面知道的IP)(这里必须是hadoop01,为了方便后面直接映射不用敲IP)
7.重启虚拟机 输入:reboot (重启后输入 ping www.baidu.com 能通就说明没问题)
第二步 克隆第一台虚拟机,完成第二第三虚拟机的配置
1.首先把第一台虚拟机关闭,在右击虚拟机选项卡,管理-克隆 即可(克隆两台 一台hadoop02 一台hadoop03)
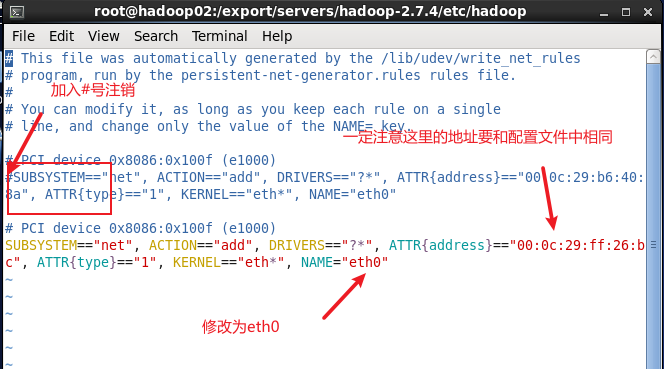
2.克隆完事后,操作和第一部基本相同唯一不同的地方是克隆完的虚拟机有两块网卡,我们把其中一个网卡注释就好(一定牢记!通过这里的物理地址一定要和配置文件中的物理地址相同) 输入:vi /etc/udev/rules.d/70-persistent-net.rules 在第一块网卡前加# 将第二块网卡改为eth0
3.当三台机器全部配置完之后,再次在hosts文件中加入映射达到能够通过名称互相访问的目的 输入:vim /etc/hosts (三台都要如此设置)(改完之后记得reboot重启)

第三步 使三台虚拟机能够通过SHELL免密登录
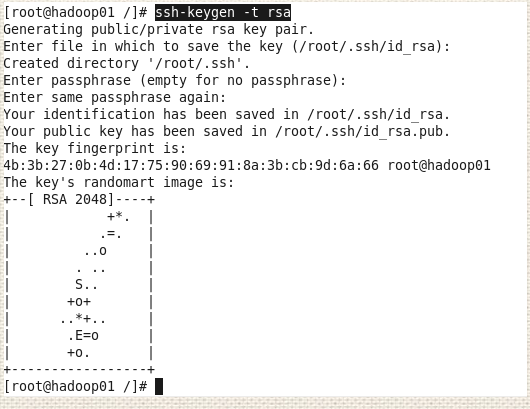

注:可能你不太理解这是怎么回事,我这样解释一下,免密登录是为了后面进行集群操作时方便,生成秘钥就像是生成一个钥匙,这个钥匙是公钥,公钥可以打开所有门,之后把这个钥匙配两把,一把放在hadoop02的那里,一把放在hadoop03的那里,这样hadoop01可以对hadoop02和hadoop03进行访问。
6.在第二台和第三台虚拟机上进行同样操作 是三台虚拟机能够进行免密互相访问。
第三步 安装JDK
1.下载软件Xshell,电脑上有了的不用下载,没有的可以下载这个 Xshell password:8w83
2.下载jdk包 jdk包 password:938z
3.上传jdk-8u162-linux-x64.tar.gz到Linux上
打开Xshell,新建会话

输入用户名密码后完成会话建立,将文件拖到文件夹/export/servers就行了
注意:如果错误或者失败,可能是文件夹权限不够导致的,去指定文件夹下输入 chmod 777 * 再次拖动即可
4.在指定文件夹下解压jar包 输入:tar -zxvf jdk-8u162-linux-x64.tar.gz -C /export/servers/
5.设置环境变量,在/etc/profile文件最后追加相关内容 输入:vi /etc/profile
追加: export JAVA_HOME=/export/servers/jdk1.8.0_162
export PATH=$PATH:$JAVA_HOME/bin

6.刷新环境变量 输入:source /etc/profile
7.测试是否成功 输入:java -version(如果显示出版本号即为成功)
8.将这个jar包给hadoop02和hadoop03分发过去 (分发比较省事,这样就不用去02和03上再配一遍了)
输入: scp -r /export/servers/jdk1.8.0_162/ hadoop02:/export/servers/
scp -r /export/servers/jdk1.8.0_162/ hadoop03:/export/servers/
第四步 Hadoop集群搭建
1.下载hadoop-2.7.4.tar.gz 安装包 hadoop-2.7.4.tar.gz 安装包 password:0tnt
2.将下载的hadoop-2.7.4.tar.gz 安装包上传到主节点hadoop01 的 /export/software目录下(步骤同上一步,用Xshell传就行)
3.将文件解压到/export/servers 目录 输入:tar -zxvf hadoop-2.7.4.tar.gz -C /export/servers/(注意在指定文件夹下解压,否则会出错)
4.配置Hadoop环境变量 输入:vi /etc/profile
在后面追加: export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
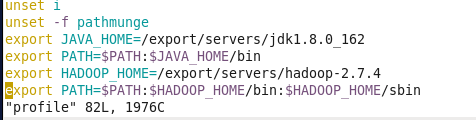
5.验证安装是否成功 输入:hadoop version (显示版本即为成功)
第五步 Hadoop集群搭建
在Hadoop下的etc文件夹中是所有的配置文件,接下来的操作我们都是在etc下进行、

1.配置Hadoop集群主节点hadoop01 修改hadoop-env.sh文件 输入:vim hadoop-env.sh
去掉注释。修改如下: export JAVA_HOME=/export/servers/jdk1.8.0_162

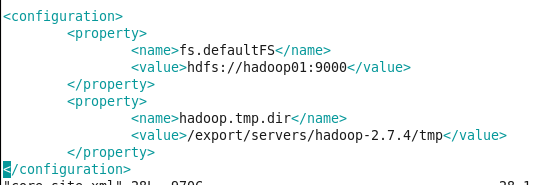
2.修改core-site.xml文件 输入:vim core-site.xml 在其中添加成下面形式
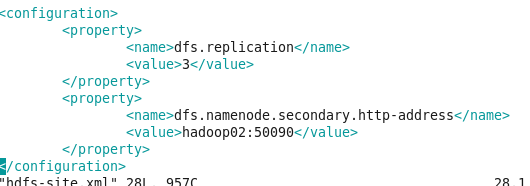
3.修改hdfs-site.xml文件 输入:vim hdfs-site.xml 在其中添加成下面形式
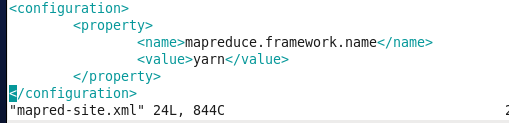
4.修改mapred-site.xml文件 因为没有这个文件,我们先copy一个 输入:mv mapred-site.xml.template mapred-site.xml
再次输入:vim mapred-site.xml 在其中添加成下面形式
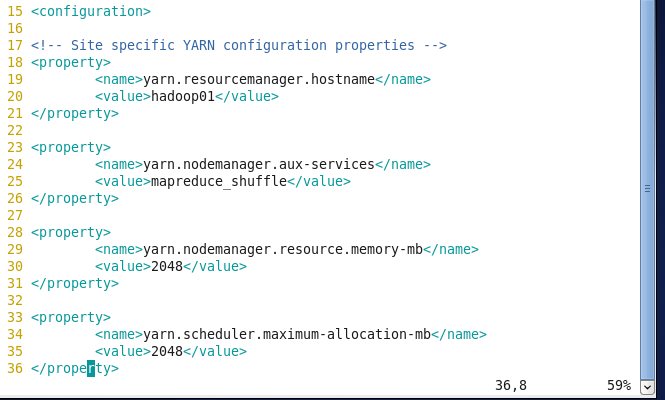
5.修改yarn-site.xml文件 输入: 在其中添加成下面形式

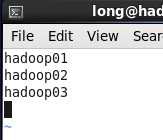
6.修改slaves文件。打开该配置文件,先删除里面的内容(默认localhost),然后配置如下内容。
7.主节点配置完毕,直接把配置好的分发给hadoop02 和 hadoop03 具体指令:
$ scp /etc/profile hadoop02:/etc/profile
$ scp /etc/profile hadoop03:/etc/profile
$ scp -r /export/servers/hadoop-2.7.4/ hadoop02:/export/servers/
$ scp -r /export/servers/hadoop-2.7.4/ hadoop03:/export/servers/
执行完成后,分别在hadoop02和hadoop03上执行指令source /etc/profile 使配置文件生效。
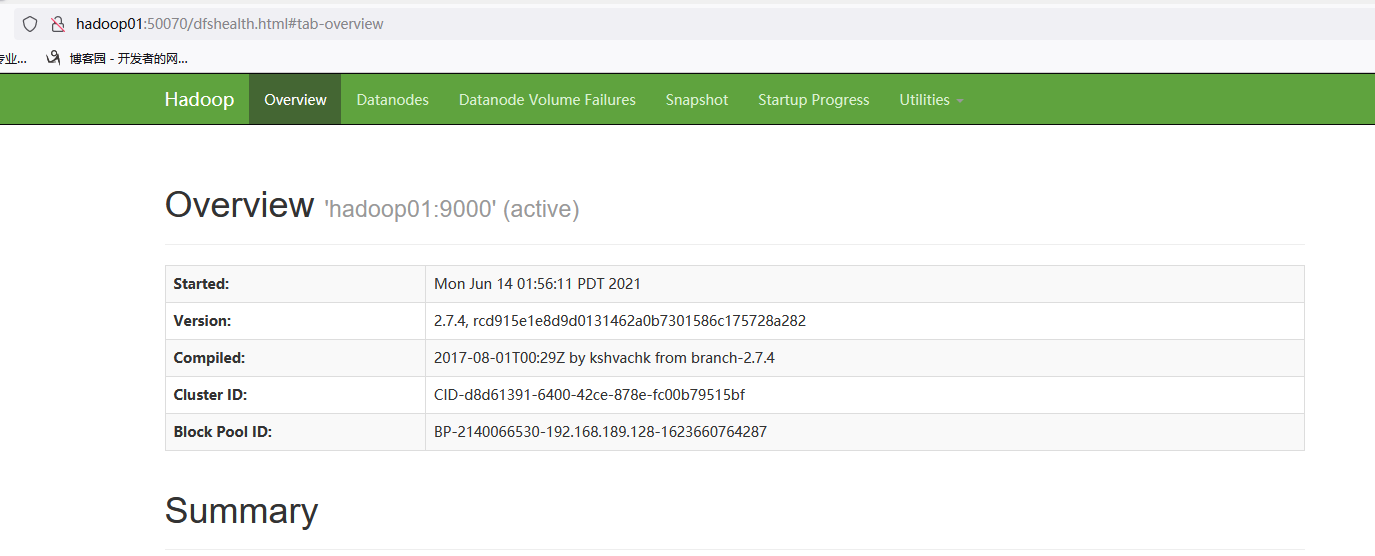
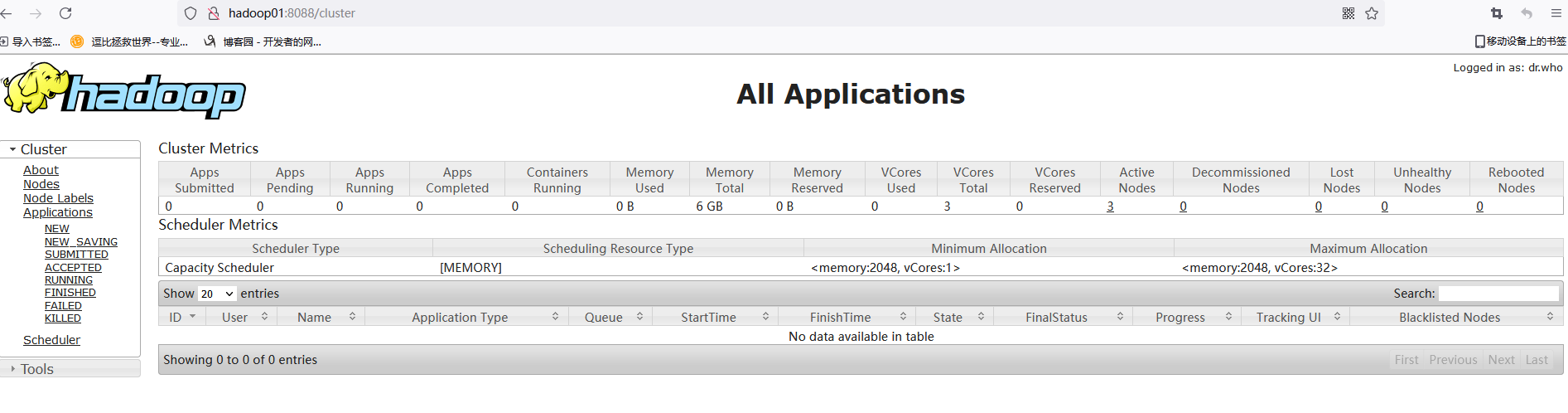
第六步 Hadoop集群测试
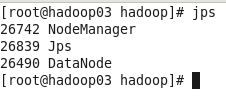
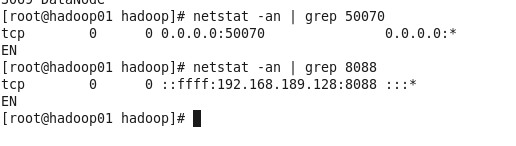
在主节点hadoop01上执行指令“start-yarn.sh”或“stop-yarn.sh”启动/关闭所有YARN服务进程;

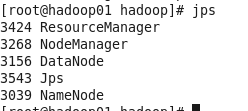
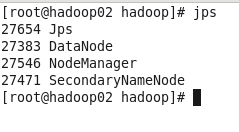




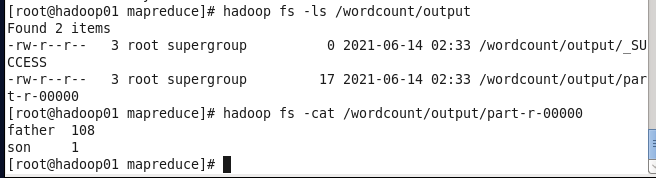
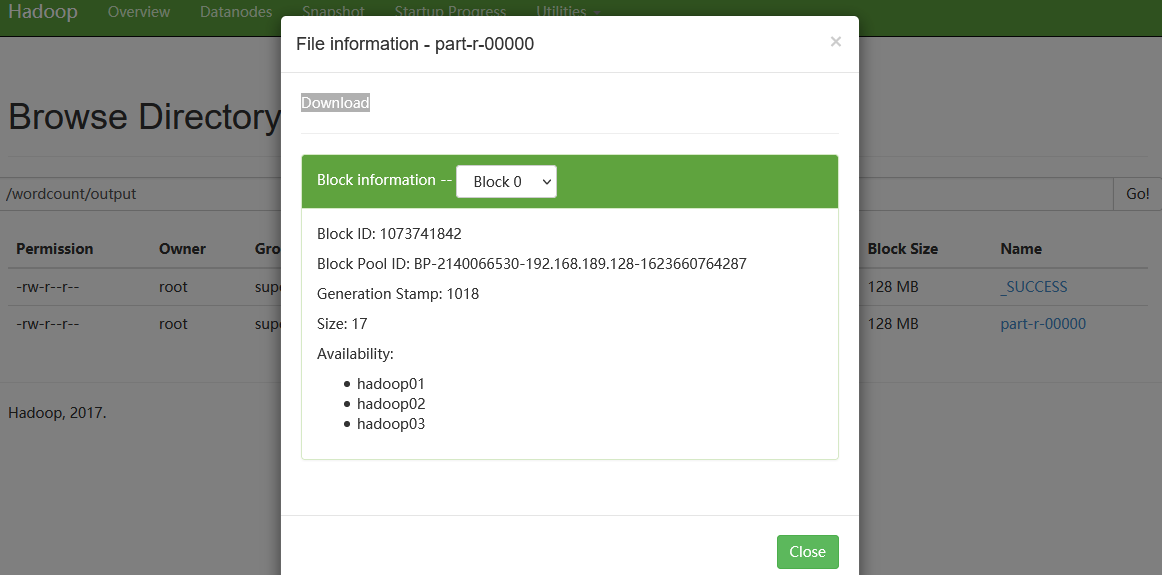
终于结束了,有啥子问题可以留言
