环境准备: bs4安装方法:https://blog.csdn.net/Bibabu135766/article/details/81662981 requests安装方法:https://blog.csdn.net/douguangyao/article/details/77922973 https://pypi.org/project/requests/#files 卸载pip:python -m pip uninstall pip 安装pip:https://pypi.python.org/pypi/pip#downloads
bs4用法介绍:Beautiful Soup和 lxml 一样, 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
https://www.cnblogs.com/amou/p/9184614.html
https://beautifulsoup.readthedocs.io/zh_CN/latest/
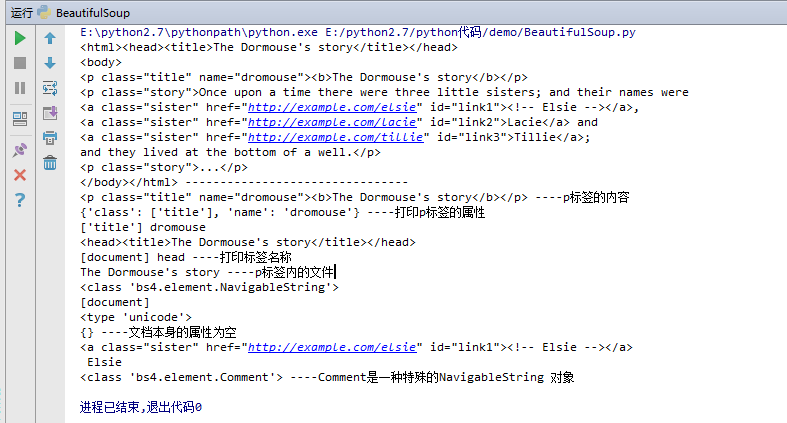
#!/usr/bin/env python # -*- coding:utf-8 -*- from bs4 import BeautifulSoup html = ''' <html><head><title>The Dormouse's story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> ''' #创建Beautiful Soup 对象 soup = BeautifulSoup(html,'lxml') print soup,"--------------------------------" # #格式化输出soup对象的内容 # print soup.prettify() #四大对象种类 Tag、NavigableString、BeautifulSoup、Comment #一、Tag通俗点讲就是 HTML 中的一个个标签 # print soup.html print soup.p,'----p标签的内容' print soup.p.attrs,'----打印p标签的属性' print soup.p['class'],soup.p['name'] print soup.head print soup.name,soup.head.name,'----打印标签名称' #二、NavigableString 要想获取标签内部的文字怎么办呢?很简单,用 .string 即可 print soup.p.string,'----p标签内的文字' print type(soup.p.string) #三、BeautifulSoup 对象表示的是一个文档的内容。大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性 print soup.name print type(soup.name) print soup.attrs,'----文档本身的属性为空' #四、Comment 对象是一个特殊类型的 NavigableString 对象,其输出的内容不包括注释符号。 print soup.a print soup.a.string print type(soup.a.string),'----Comment是一种特殊的NavigableString 对象'
打印结果如下:
BeautifulSoup4查找、正则使用:
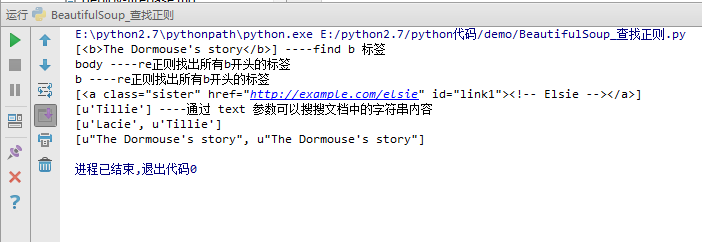
#!/usr/bin/env python # -*- coding:utf-8 -*- from bs4 import BeautifulSoup import resoup = BeautifulSoup(html,'lxml') #print soup,'------------html文档--------------'
print soup.find_all('b'),'----find b 标签' for tag in soup.find_all(re.compile('^b')): print tag.name,'----re正则找出所有b开头的标签' print soup.find_all(id='link1') print soup.find_all(text='Tillie'),'----通过 text 参数可以搜搜文档中的字符串内容' print soup.find_all(text=["Tillie",'Lacie']) print soup.find_all(text=re.compile('Dormouse'))
打印结果如下:
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
requests用法介绍:
http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
https://cuiqingcai.com/2556.html