@
目录
一、数据查看、转置
# 数据查看、转置
df = pd.DataFrame(np.random.rand(16).reshape(8,2)*100,
columns = ['a','b'])
print(df.head(2))# .head()查看头部数据
print(df.tail())# .tail()查看尾部数据
# 不输入参数,默认查看5条
# .T 转置
print(df.T)
二、添加与修改
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
# 新增列/行并赋值
df['e'] = 10
df.loc[4] = 20 #iloc不能用于增加
# 索引后直接修改值
df['e'] = 20
df[['a','c']] = 100
三、删除 del / drop()
df = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
# del语句 - 删除列
del df['a']
# drop()删除行,默认:inplace=False → 删除后生成新的数据,不改变原数据
print(df.drop(0)) # !!!这里的数字0是index的名字而不是序号
print(df.drop([1,2]))
# drop()删除列,需要加上axis = 1,默认:inplace=False → 删除后生成新的数据,不改变原数据
print(df.drop(['d'], axis = 1))
print(df)
四、基本运算,自动对齐
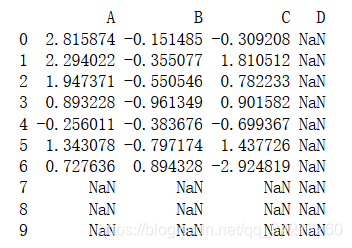
DataFrame对象之间进行运算时,数据自动按照列和索引(行标签)对齐。只要有一个DataFrame对象对应位置为NaN,怎运算完的对应位置也为NaN
df1 = pd.DataFrame(np.random.randn(10, 4), columns=['A', 'B', 'C', 'D'])
df2 = pd.DataFrame(np.random.randn(7, 3), columns=['A', 'B', 'C'])
print(df1 + df2)
五、排序
和Excel的排序规则是一致的
5.1 按值(列)排序 .sort_values
# 同样适用于Series
df1 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
columns = ['a','b','c','d'])
print(df1)
# 单列排序
# ascending参数:设置升序降序,默认升序
print(df1.sort_values(['a'], ascending = True)) # 升序
print(df1.sort_values(['a'], ascending = False)) # 降序
print('------')
# 多列排序,按列顺序排序,先排前面的再排后面的
df2 = pd.DataFrame({'a':[1,1,1,1,2,2,2,2],
'b':list(range(8)),
'c':list(range(8,0,-1))})
print(df2)
print(df2.sort_values(['a','c']))
# 注意默认inplace=False
5.2 按索引(行)排序 .sort_index
df1 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = [5,4,3,2],
columns = ['a','b','c','d'])
df2 = pd.DataFrame(np.random.rand(16).reshape(4,4)*100,
index = ['h','s','x','g'],
columns = ['a','b','c','d'])
print(df1)
print(df1.sort_index())
print(df2)
print(df2.sort_index())
打赏
码字不易,如果对您有帮助,就打赏一下吧O(∩_∩)O

