@
一、前言
深度残差网络(Deep residual network, ResNet)的提出是CNN图像史上的一件里程碑事件,让我们先看一下ResNet在ILSVRC和COCO 2015上的战绩:
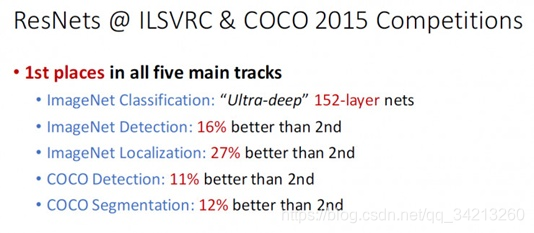
ResNet取得了5项第一,并又一次刷新了CNN模型在ImageNet上的历史,
ImageNet分类Top-5误差:
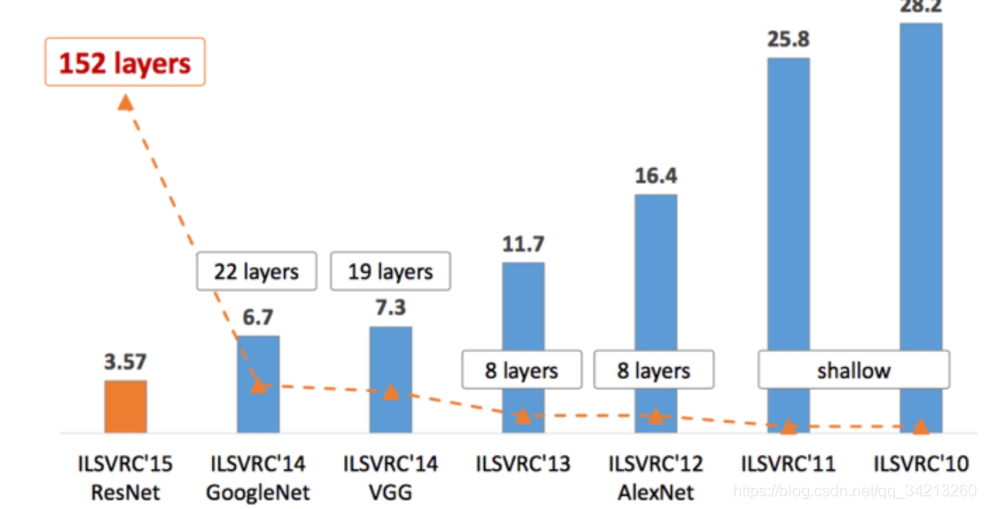
那么ResNet为什么会有如此优异的表现呢?其实ResNet是解决了深度CNN模型难训练的问题,从图2中可以看到14年的VGG才19层,而15年的ResNet多达152层,这在网络深度完全不是一个量级上,所以如果是第一眼看这个图的话,肯定会觉得ResNet是靠深度取胜。事实当然是这样,但是ResNet还有架构上的技巧,这才使得网络的深度发挥出作用,这个技巧就是残差学习(Residual learning)。
-
论文名称:Deep Residual Learning for Image Recognition
-
论文作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
-
论文地址:[1512.03385] Deep Residual Learning for Image Recognition
二、深度网络的退化问题
从经验来看,网络的深度对模型的性能至关重要,当增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时理论上可以取得更好的结果,
在深度学习中,网络层数增多一般会伴着下面几个问题
- 计算资源的消耗
- 模型容易过拟合
- 梯度消失/梯度爆炸问题的产生
- 问题1可以通过GPU集群来解决,对于一个企业资源并不是很大的问题;
- 问题2的过拟合通过采集海量数据,并配合Dropout正则化等方法也可以有效避免;
- 问题3通过Batch Normalization也可以避免。
貌似我们只要无脑的增加网络的层数,我们就能从此获益,但实验数据给了我们当头一棒。实验发现深度网络出现了退化问题(Degradation problem):网络深度增加时,网络准确度出现饱和,甚至出现下降。这个现象可以在下图中直观看出来:
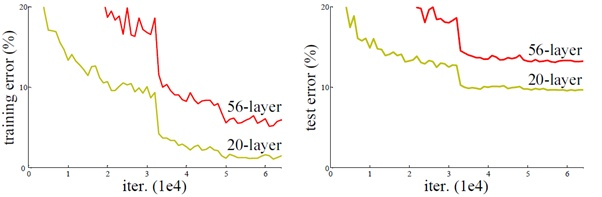 56层的网络比20层网络效果还要差。这不会是过拟合问题,因为56层网络的训练误差同样高。我们知道深层网络存在着梯度消失或者爆炸的问题,这使得深度学习模型很难训练。但是现在已经存在一些技术手段如BatchNorm来缓解这个问题。因此,出现深度网络的退化问题是非常令人诧异的。
56层的网络比20层网络效果还要差。这不会是过拟合问题,因为56层网络的训练误差同样高。我们知道深层网络存在着梯度消失或者爆炸的问题,这使得深度学习模型很难训练。但是现在已经存在一些技术手段如BatchNorm来缓解这个问题。因此,出现深度网络的退化问题是非常令人诧异的。
当网络退化时,浅层网络能够达到比深层网络更好的训练效果,这时如果我们把低层的特征传到高层,那么效果应该至少不比浅层的网络效果差,或者说如果一个VGG-100网络在第98层使用的是和VGG-16第14层一模一样的特征,那么VGG-100的效果应该会和VGG-16的效果相同。但是实验结果表明,VGG-100网络的训练和测试误差比VGG-16网络的更大。这说明A网络在学习恒等映射的时候出了问题,也就是传统的网络("plain" networks)很难去学习恒等映射。也就是说,我们不得不承认肯定是目前的训练方法有问题,才使得深层网络很难去找到一个好的参数。
所以,我们可以在VGG-100的98层和14层之间添加一条直接映射(Identity Mapping)来达到此效果。
从信息论的角度讲,由于DPI(数据处理不等式)的存在,在前向传输的过程中,随着层数的加深,Feature Map包含的图像信息会逐层减少,而ResNet的直接映射的加入,保证了 l+1层的网络一定比 l 层包含更多的图像信息。
基于这种使用直接映射来连接网络不同层直接的思想,残差网络应运而生。
三、残差学习
3.1 残差网络原理
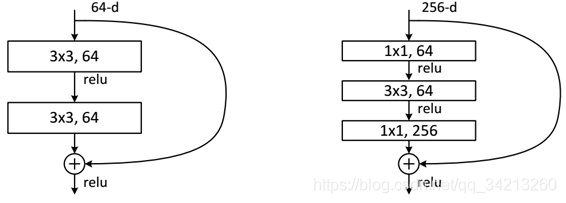
对于一个堆积层结构(几层堆积而成)当输入为x时其学习到的特征记为H (x),现在我们希望其可以学习到残差F(x)= H(x) - x,这样其实原始的学习特征是H(x)= F(x) + x。之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构如下图所示。这有点类似与电路中的“短路”,所以是一种短路连接(shortcut connection)。
- 改变前目标: 训练F(x) 逼近 H(x)
- 改变后目标:训练 F(x)逼近H(x) - x
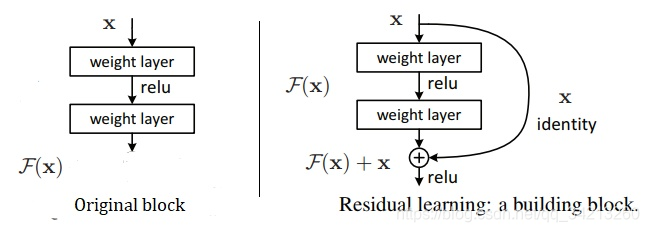
上图中,左边的original block需要调整其内部参数,使得输入的x经过卷积操作后最终输出的F(x)等于x,即实现了恒等映射F(x)=x,等号左边是block的输出,右边是block的输入。但是这种结构的卷积网络很难调整其参数完美地实现F(x)=x。再看右边的Res block。因为shortcut的引入,整个block的输出变成了F(x)+x,block的输入还是x。此时网络需要调整其内部参数使得F(x)+x=x,也就是直接令其内部的所有参数为0,使得F(x)=0,F(x)+x=x就变成了0+x = x,等号左边是block的输出,右边是block的输入。输出等于输入,即完美地完成了恒等映射。
3.2 ResNet结构为什么可以解决深度网络退化问题?
因为ResNet更加容易拟合恒等映射,原因如下:
ResNet的结构使得网络具有与学习恒等映射的能力,同时也具有学习其他映射的能力。因此ResNet的结构要优于传统的卷积网络(plain networks)结构。
3.3 残差单元
由于ResNet要求 F(x)与 x 的维度大小要一致才能够相加,因此在 F(x) 与 x 维度不相同时就需要对 x 的维度做调整。
ResNet使用两种残差单元,如下图所示。左图对应的是浅层网络,而右图对应的是深层网络。对于短路连接,当输入和输出维度一致时,可以直接将输入加到输出上。但是当维度不一致时(对应的是维度增加一倍),这就不能直接相加。有两种策略:
(A方式)采用zero-padding增加维度,此时一般要先做一个downsamp,可以采用strde=2的pooling,这样不会增加参数;
(B方式)采用新的映射(projection shortcut),一般采用1x1的卷积,这样会增加参数,也会增加计算量。
A方式采用0填充.,完全不存在任何的残差学习能力。
B方式的模型复杂度偏高
因此论文中采用折中的C方式
C方式在F(x)的维度与 x的维度相同时,直接用 F(x) 加上 x,在维度不同时,才采用1x1的卷积层对 x 的维度进行调整。
def identity_block(input_tensor, kernel_size, filters, stage, block):
"""The identity block is the block that has no conv layer at shortcut. A方式
# Arguments
input_tensor: input tensor
kernel_size: defualt 3, the kernel size of middle conv layer at main path
filters: list of integers, the filters of 3 conv layer at main path
stage: integer, current stage label, used for generating layer names
block: 'a','b'..., current block label, used for generating layer names
# Returns
Output tensor for the block.
"""
filters1, filters2, filters3 = filters
if K.image_data_format() == 'channels_last':
bn_axis = 3
else:
bn_axis = 1
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(filters1, (1, 1), name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = Conv2D(filters2, kernel_size,
padding='same', name=conv_name_base + '2b')(x)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = Conv2D(filters3, (1, 1), name=conv_name_base + '2c')(x)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2c')(x)
x = layers.add([x, input_tensor])
x = Activation('relu')(x)
return x
def conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2, 2)):
"""conv_block is the block that has a conv layer at shortcut
B方式
# Arguments
input_tensor: input tensor
kernel_size: defualt 3, the kernel size of middle conv layer at main path
filters: list of integers, the filterss of 3 conv layer at main path
stage: integer, current stage label, used for generating layer names
block: 'a','b'..., current block label, used for generating layer names
# Returns
Output tensor for the block.
Note that from stage 3, the first conv layer at main path is with strides=(2,2)
And the shortcut should have strides=(2,2) as well
"""
filters1, filters2, filters3 = filters
if K.image_data_format() == 'channels_last':
bn_axis = 3
else:
bn_axis = 1
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(filters1, (1, 1), strides=strides,
name=conv_name_base + '2a')(input_tensor)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2a')(x)
x = Activation('relu')(x)
x = Conv2D(filters2, kernel_size, padding='same',
name=conv_name_base + '2b')(x)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2b')(x)
x = Activation('relu')(x)
x = Conv2D(filters3, (1, 1), name=conv_name_base + '2c')(x)
x = BatchNormalization(axis=bn_axis, name=bn_name_base + '2c')(x)
shortcut = Conv2D(filters3, (1, 1), strides=strides,
name=conv_name_base + '1')(input_tensor)
shortcut = BatchNormalization(axis=bn_axis, name=bn_name_base + '1')(shortcut)
x = layers.add([x, shortcut])
x = Activation('relu')(x)
return x
3.4 ResNet的网络结构
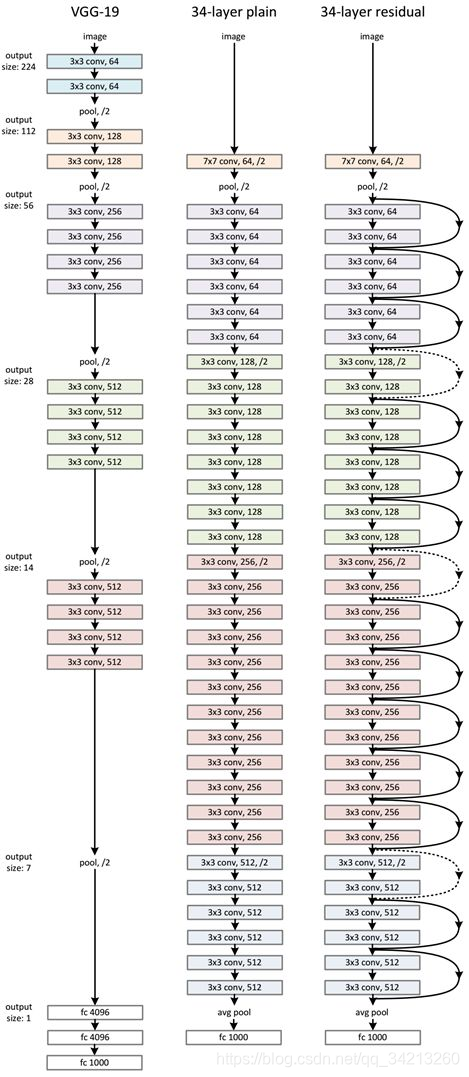
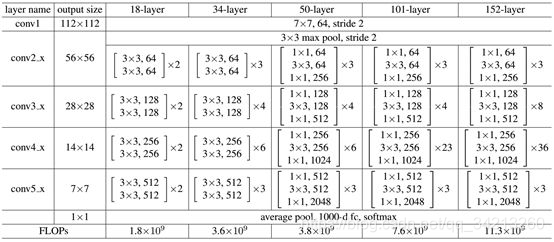
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如下图所示。变化主要体现在ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。从下图中可以看到,ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示feature map数量发生了改变。下图展示的34-layer的ResNet,还可以构建更深的网络如表1所示。从表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1,一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。
四、实验结果
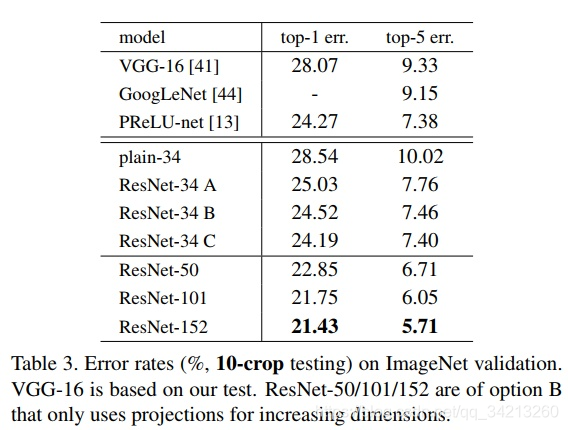
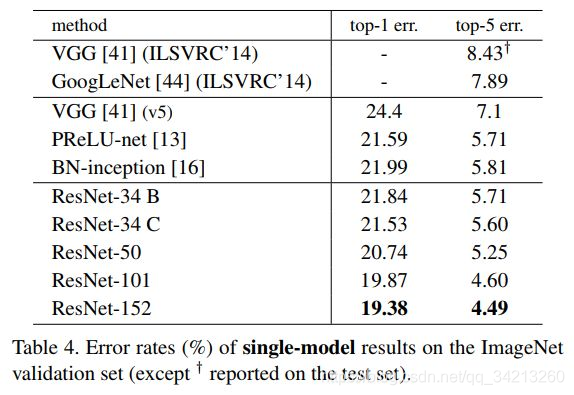
作者搭建了不同深度的ResNet模型进行了实验,结果如上图所示。ResNet在ImageNet上的错误率与网络的深度是线性关系,网络越深,错误率越低。说明在一定ResNet的网路结构解决之前所说的网络退化的问题。
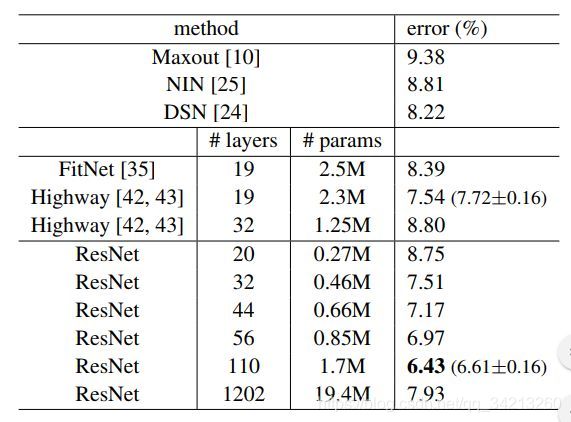
这是作者在CIFAR-10上的实验结果,这里使用的shortcut是A方式,可以看出来在相同深度下ResNet的参数量远远小于其他网络,这也使得我们在训练和预测模型的时候计算比较快。作者还尝试训练了1202层的ResNet,但是最终结果并没有110层的效果好,作者分析可能是因为过拟合的原因。作者还将ResNet用于Faster-RCNN中,获得了2015年COCO的detection的冠军。
ResNet-50 完整代码
https://download.csdn.net/download/qq_34213260/12457533
参考资料:
https://zhuanlan.zhihu.com/p/31852747
https://zhuanlan.zhihu.com/p/32085715
https://zhuanlan.zhihu.com/p/42706477