一、梯度消失
1.1 定义
神经⽹络靠输⼊端的⽹络层的系数逐渐不再随着训练⽽变化,或者
变化⾮常缓慢。随着⽹络层数增加,这个现象越发明显
1.2 梯度消亡(Gradient Vanishing)前提
- 使⽤基于梯度的训练⽅法(例如梯度下降法)
- 使⽤的激活函数具有输出值范围⼤⼤⼩于输⼊值的范围,例如
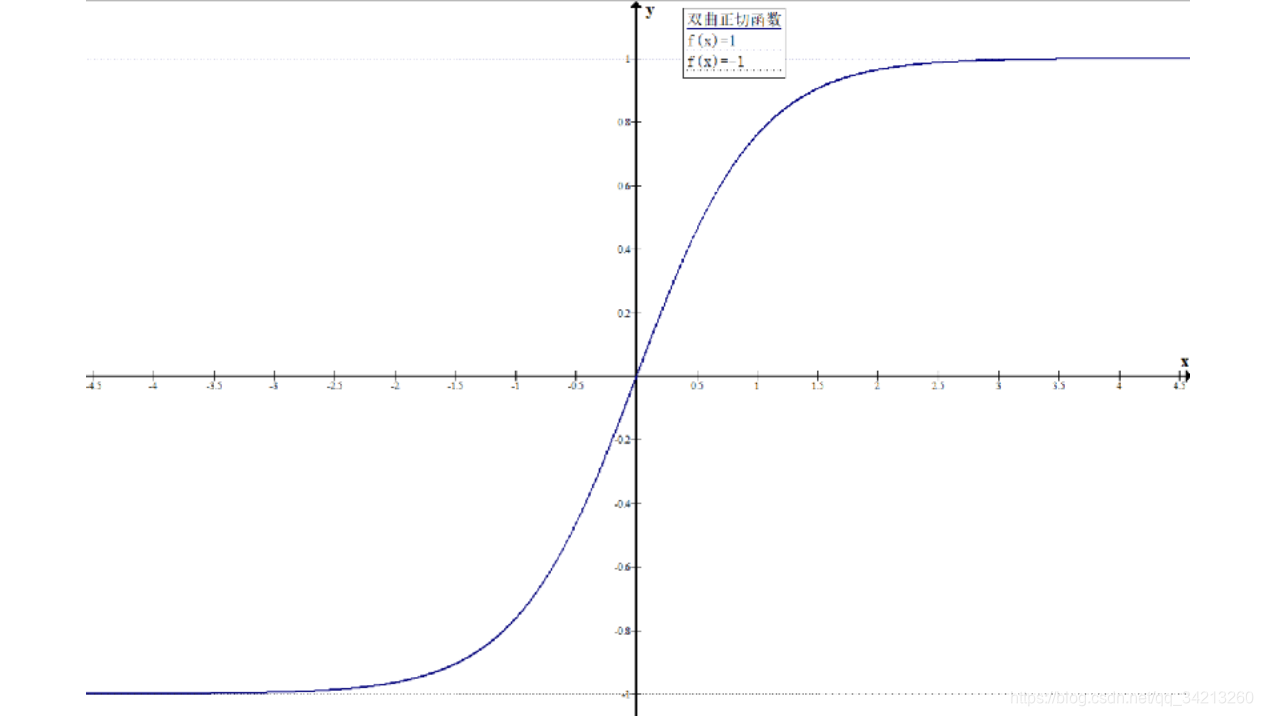
logistic(逻辑斯函数), tanh(双曲正切)
1.3 产生的原因
梯度下降法依靠理解系数的微⼩变化对输出的影响来学习⽹络的系数的值。如果⼀个系数的微⼩变化对⽹络的输出没有影响或者影响极⼩,那么就⽆法知晓如何优化这个系数,或者优化特别慢。造成训练的困难。
使用梯度下降法训练神经网络,如果激活函数具备将输出值的范围相对于输入的值大幅度压缩,那么就会出现梯度消亡。
例如,双曲正切函数(tanh) 将-∞到∞的输入压缩到-1到+1之间。除开在输入为-6,+6之间的值,其它输入值对应的梯度都非常小,接近0.
1.4 解决方案
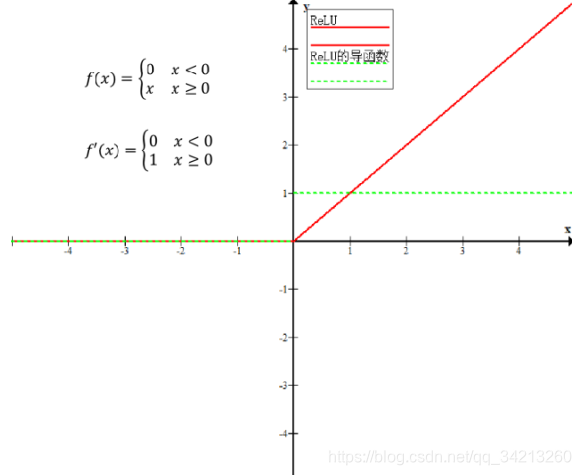
- 激活函数ReLu: f(x) = max(0, x)
输入大于0,梯度为1,否则0. - 激活函数LeakyReLu: f(x) = max(ax,x)
输入大于等于0,梯度为1,否则为a
采⽤不使⽤梯度的⽹络训练⽅法: https://link.springer.com/article/10.1007/s10898-012-9951-y(Derivativefree optimization: a review of algorithms and comparison of software implementations)
3.1.基于遗传、进化算法
https://www.ijcai.org/Proceedings/89-1/Papers/122.pdf
https://blog.coast.ai/lets-evolve-a-neural-network-with-a-genetic-algorithm-code-included-8809bece164
3.2.粒⼦群优化(Particle Swarm Optimization, PSO)
https://visualstudiomagazine.com/articles/2013/12/01/neural-network-training-using-particle-swarm
optimization.aspx
https://ieeexplore.ieee.org/document/1202255/?reload=true
二、梯度爆炸
当gradient<1时产生梯度消失,gradient>1产生梯度爆炸,定义、产生原因都类似。
2.1 解决方法
梯度剪切(Gradient Clipping):其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。
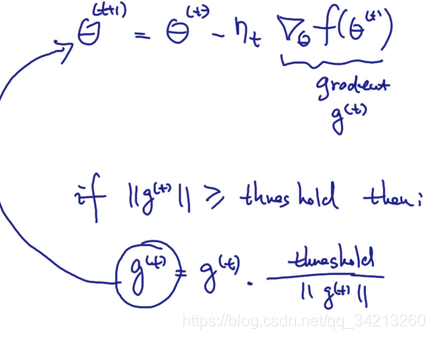
其他解决方法:https://blog.csdn.net/qq_25737169/article/details/78847691