1.pig运行模式
本地模式: pig -x local
直接访问本地磁盘
集群模式: pig 或者 pig -x mapreduce
2.pig latin 交互
帮助信息 help
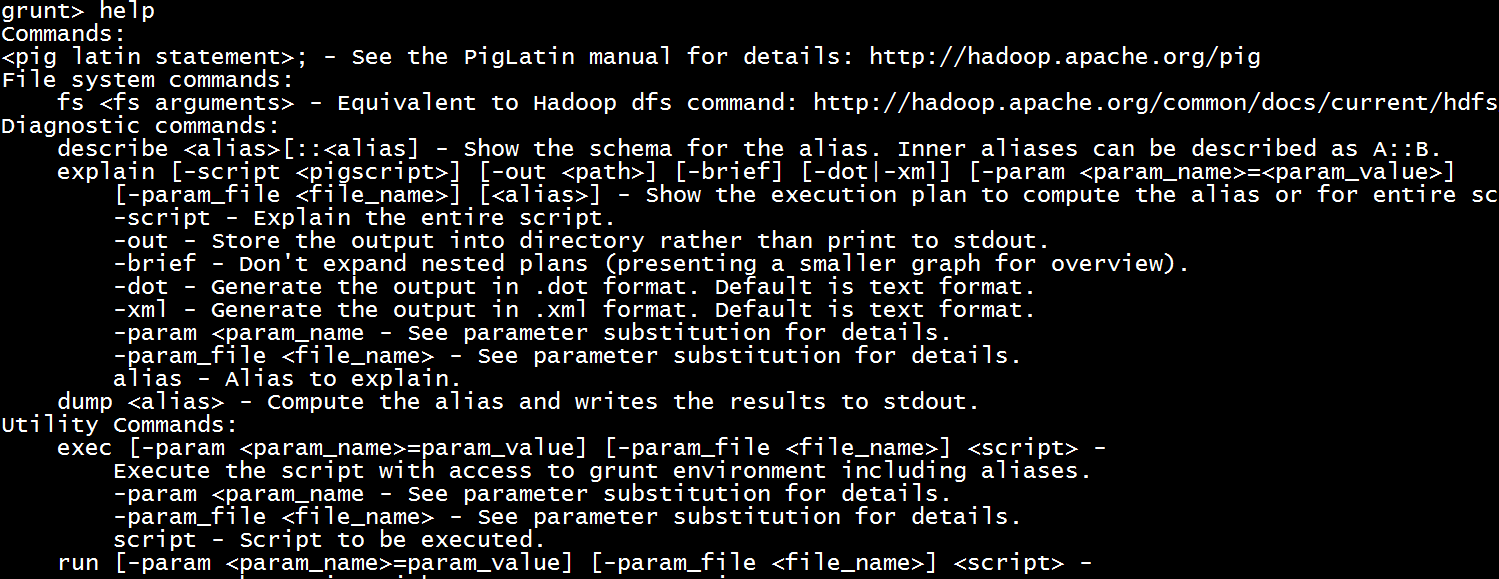
上传本地文件到hdfs中
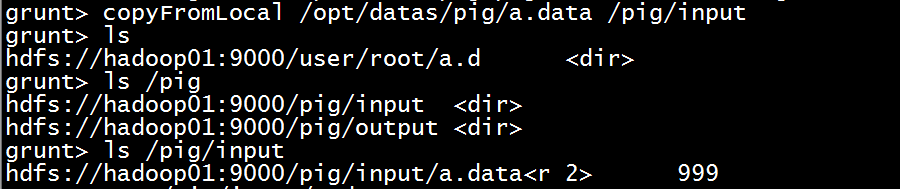
查看内容 cat
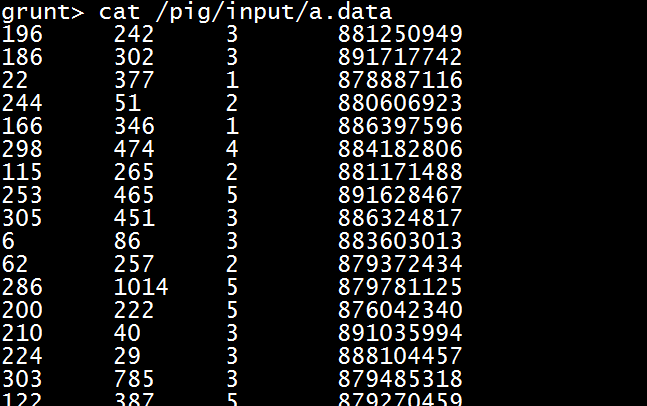
加载数据
grunt> A = load '/pig/input/a.data' using PigStorage(' '); --加载文件,并用冒号’ ‘将数据分离为多个字段
grunt> B = foreach A generate $0 as id; --将每一次迭代的第一个元祖数据作为id
grunt> dump B; 在命令行输出结果
执行成功,如下展示:
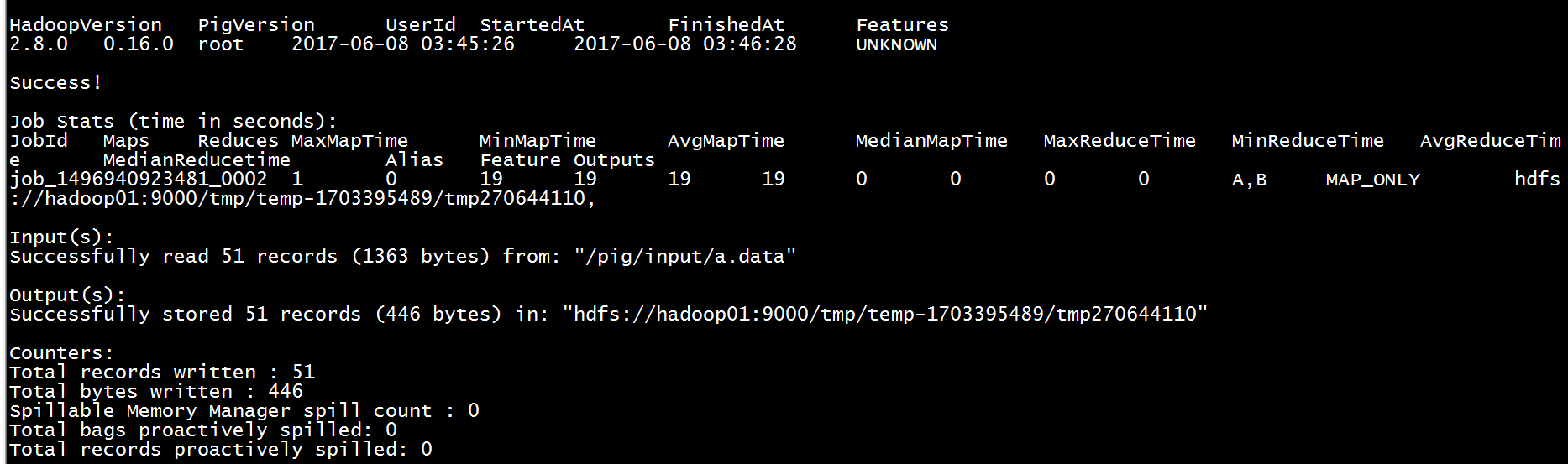
计算结果
3. 小试牛刀
1)、加载学生信息
student = load '/pig/input/student.data' using PigStorage(',') as (id:long,name:chararray,class:int,state:int);
2)过滤 符合条件的数据
filterStudent= filter student by state==1;
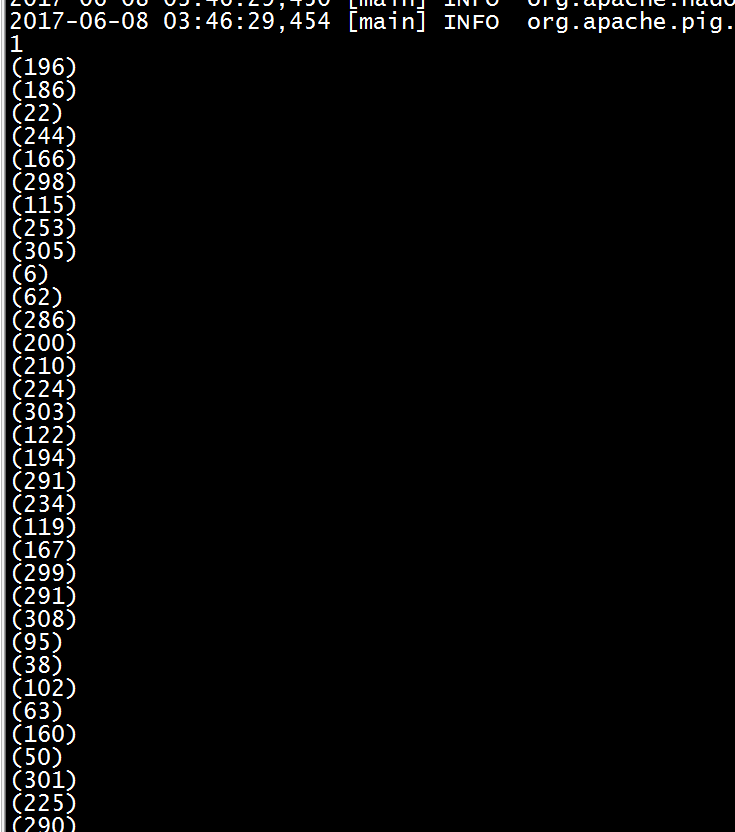
3)展示每个班的学生
groupStudentByClass= group student by class parallel 2;
dump groupStudentByClass;
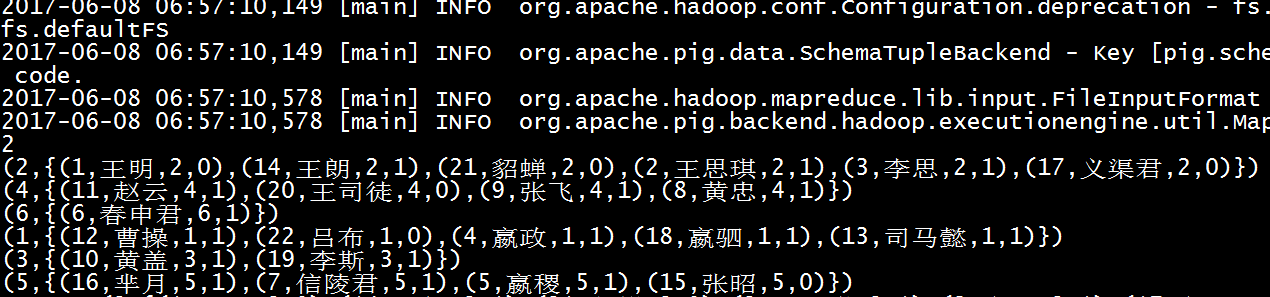
4)统计每个班的人数
groupclass= foreach groupStudentByClass generate $0 as sid,COUNT($1) as total;
dump groupclass;

5)join
studentTeacher = join student by class,teacher by clazz;
dump studentTeacher;
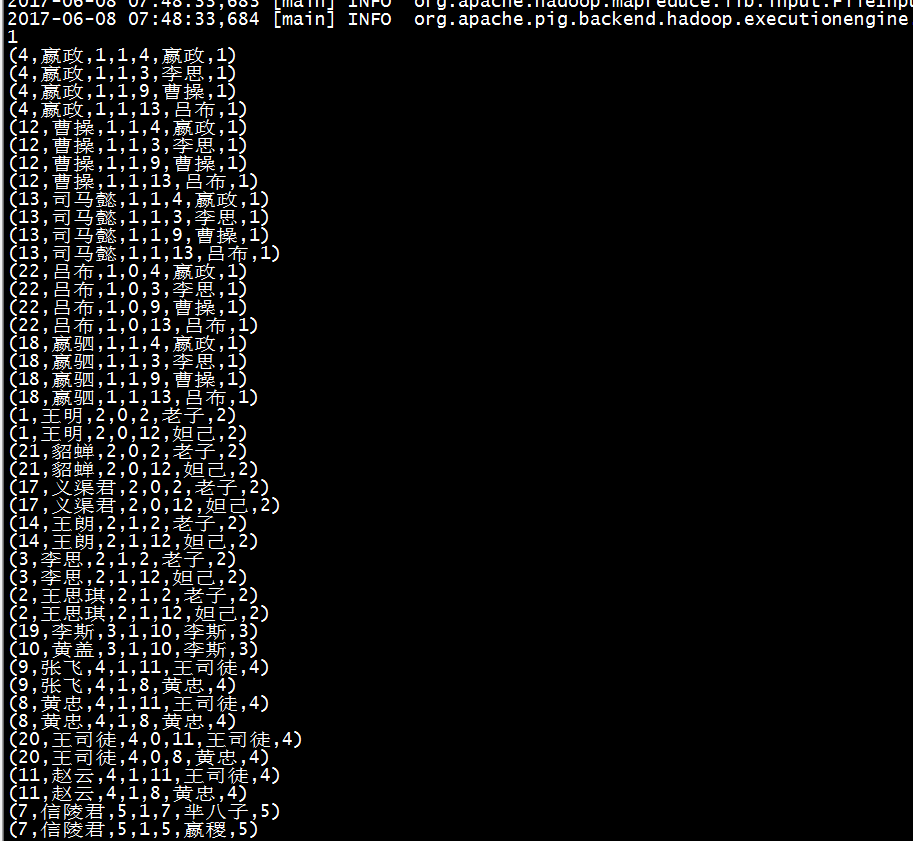
参考资料:
https://www.ibm.com/developerworks/cn/linux/l-apachepigdataquery/
http://pig.apache.org/docs/r0.16.0/start.html
<pig编程指南>