【VGG】Very deep convolutional networks for large-scale image recognition
https://arxiv.org/pdf/1409.1556.pdf
文章通过严格的变量控制, 探索了网络层数(深度)对卷积网络性能的影响:
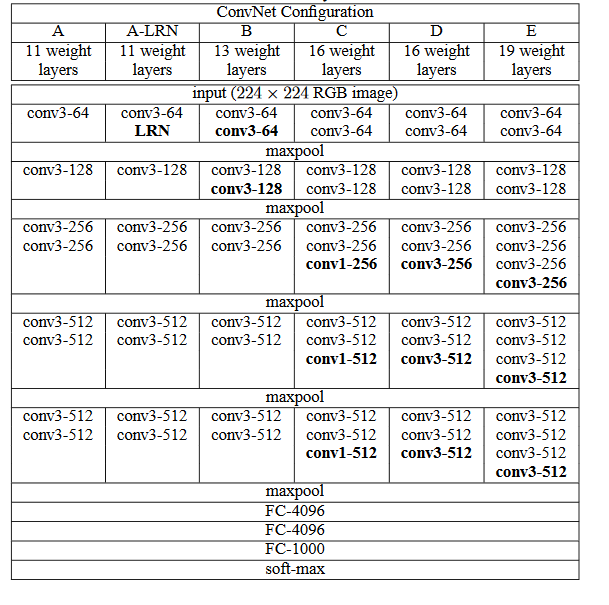
AlexNet在LeNet的基础上增加了3个卷积层。但AlexNet作者对它们的卷积窗口、输出通道数和构造顺序均做了大量的调整。虽然AlexNet指明了深度卷积神经网络可以取得出色的结果,但并没有提供简单的规则以指导后来的研究者如何设计新的网络
VGG提出了可以通过重复使用简单的基础块来构建深度模型的思路,并在网络结构设计层面给出了一些经验性的建议:
- 堆叠的小卷积核要胜过一个大的卷积核
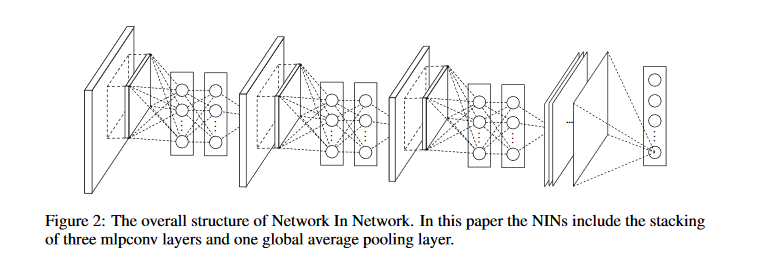
【NiN】Network In Network
https://arxiv.org/pdf/1312.4400.pdf
- 不带激活函数的卷积层只有处理线性可分数据的能力,哪怕堆叠后可以一定程度上拟合非线性数据,过程中也消耗了太多不必要的资源(因为它本身抽象能力很弱)
- 所以NiN提出,线性映射后要跟上非线性映射,这样每一层的抽象能力才更强,堆叠后整个网络的抽象效率才更高
- 同样,对于CNN来说,顶层的非线性映射要handle底层所有的线性映射结果,这样做负担太重
- 所以不如把非线性映射放到网络的每一层中,让抽象负担平均分配至每一层
- 文章把传统CNN中顶部的全连接层换成了全局池化层
- 因为全连接层的可解释性太差
- 也因为全连接层容易过拟合,且非常依赖dropout
- 由于NiN中每一层单元都有更强的拟合能力,所以让最后一层的特征图直接作为类别置信图是可行的
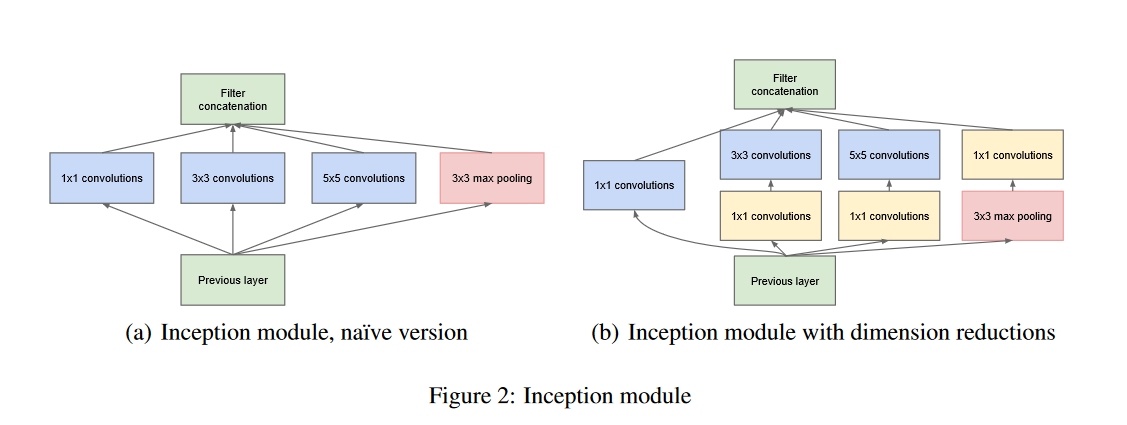
【GoogLeNet】Going deeper with convolutions
PS:这篇巨难......
https://arxiv.org/pdf/1409.4842.pdf
- 作者在这篇文章中关注了神经网络的计算和拟合效率,并指出不依赖算力和数据规模的算法性能提升是非常重要的。(GoogLeNet在参数量上比两年前ILSVRC14的冠军方案少了12倍,但准确率却显著提升)
- 文章中使用1×1的卷积层来控制网络的通道数(以降低模型的复杂度)
- GoogLeNet吸收了NiN中网络串联网络的思想,并在此基础上做了很大改进。GooLeNet的基础是Inception块,这是一个相当于有4条线路的子网络。它通过不同窗口形状的卷积层和最大池化层来并行抽取信息,并使用1×11×1卷积层减少通道数从而降低模型复杂度
- GoogLeNet将多个设计精细的Inception块和其他层串联起来。其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的
- GoogLeNet和它的后继者们一度是ImageNet上最高效的模型之一:在类似的测试精度下,它们的计算复杂度往往更低
这段内容看不太懂...
The fundamental way of solving both issues would be by ultimately moving from fully connectedto sparsely connected architectures, even inside the convolutions. Besides mimicking biologicalsystems, this would also have the advantage of firmer theoretical underpinnings due to the ground-breaking work of Arora et al. [2]. Their main result states that if the probability distribution ofthe data-set is representable by a large, very sparse deep neural network, then the optimal networktopology can be constructed layer by layer by analyzing the correlation statistics of the activationsof the last layer and clustering neurons with highly correlated outputs. Although the strict math-ematical proof requires very strong conditions, the fact that this statement resonates with the wellknown Hebbian principle – neurons that fire together, wire together – suggests that the underlyingidea is applicable even under less strict conditions, in practice.
这里提到的both issues指:“粗暴地增加网络规模所导致的算力和标注数据的成本上升”,[2]中的文献是“Sanjeev Arora, Aditya Bhaskara, Rong Ge, and Tengyu Ma. Provable bounds for learningsome deep representations.CoRR, abs/1310.6343, 2013”
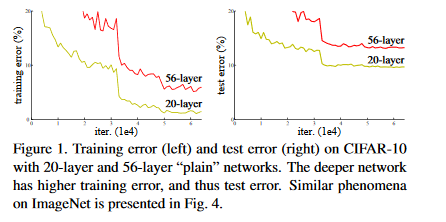
【ResNet】Deep Residual Learning for Image Recognition
https://arxiv.org/pdf/1512.03385.pdf
-
经验性地证明了,拟合残差可以显著降低深度网络的训练难度(从此,DNN开始进入成百上千层的时代...)
-
论文想解决的问题:深层网络的训练和测试误差都大于浅层网络,这意味着深层网络一定程度一直处于“欠拟合状态”
-
论文指出,我们可以假设深层网络的浅层参数和浅层网络一致,多余的层数全部为恒等映射,这意味着,深层网络的拟合能力应该不低于浅层网络。那么,上面提到的问题很有可能是深层网络未得到完全优化而引起的(或者说,在可接受的时间内无法训练到足够优化的程度)
-
论文从上述假设出发,设计了针对残差进行拟合的网络结构,在一定程度上改善了深度网络难以优化的问题
- 核心假设:残差比原函数值更容易优化
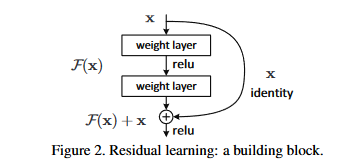
- 上图中weight layer的数目是可以灵活调整的
- 核心假设:残差比原函数值更容易优化
-
ResNet沿用了VGG全3×3卷积层的设计。残差块里首先有2个有相同输出通道数的3×3卷积层。每个卷积层后接一个批量归一化层和ReLU激活函数。然后我们将输入跳过这两个卷积运算后直接加在最后的ReLU激活函数前。这样的设计要求两个卷积层的输出与输入形状一样,从而可以相加。如果想改变通道数,就需要引入一个额外的1×1卷积层来将输入变换成需要的形状后再做相加运算
-
ResNet在2015年的ImageNet图像识别挑战赛夺魁,深刻地影响了后来的深度神经网络的设计