距离上一篇笔记竟然快要一个月了……希望这周能把cs229监督学习部分的知识搞定。
生成学习与判别学习
像逻辑回归,用hθ(x) = g(θTx) 直接地来建模 p(y|x; θ) ;或者像感知机,直接从输入空间映射到输出空间(0或1),它们都被称作判别学习(discriminative learning)。 与之相对的是生成学习(generative learning),先对 p(x|y) 与 p(y) 建模,然后通过贝叶斯法则导出后验条件概率分布 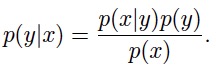
分母的计算规则为全概率公式:p(x) = p(x|y = 1)p(y = 1) + p(x|y =0)p(y = 0)。 这一节介绍的三个算法GDA、朴素贝叶斯、多项事件模型,都属于生成学习的范畴。
GDA (Gaussian discriminant analysis)
1.多元正态分布
因为GDA要通过多元正态分布来对p(x|y)进行建模,所以先介绍一下多元正态: 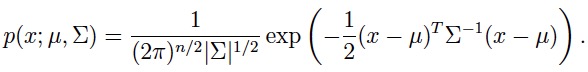
其中两个参数:μ为均值向量,Σ为协方差矩阵。 接下来从比较容易可视化的二元正态分布图像入手,了解参数变化对概率分布变化的影响: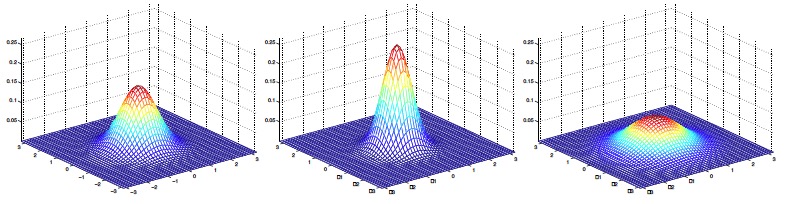

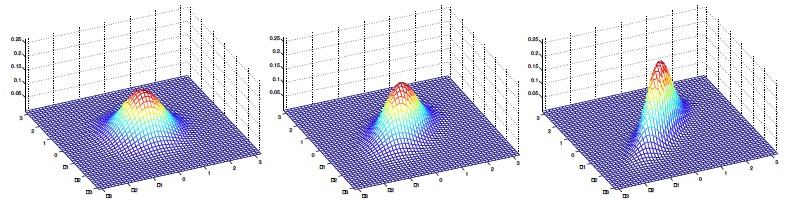
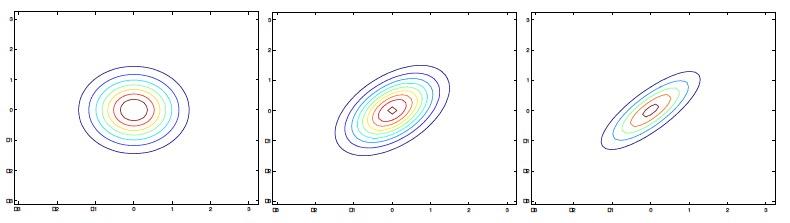

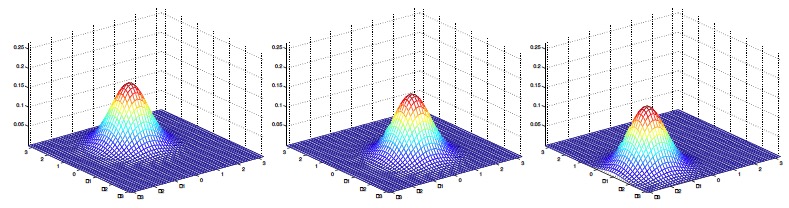
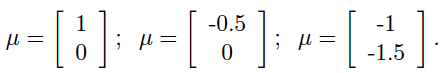
2.模型
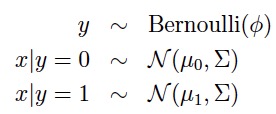
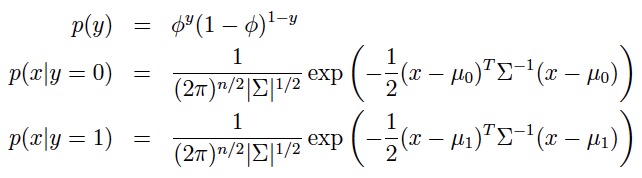
注:虽然在y分别为0与1的时候,有两个不同的均值向量,这个模型通常接受使用同一个协方差矩阵。
3.策略
极大化似然函数 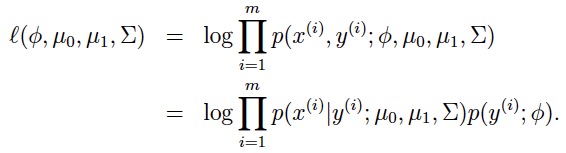
4.算法
极大化似然函数可以得到解析解: 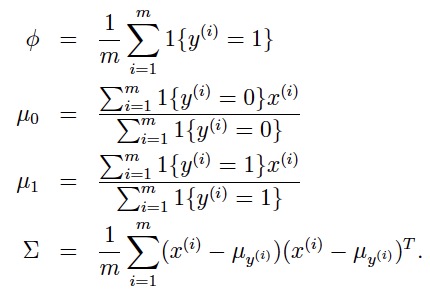
5.GDA与逻辑回归的联系与比较
如果我们把p(y=1 | x; Φ, μ0, μ1, Σ)当成x的函数,那么GDA的模型可以用逻辑回归的形式来表示: 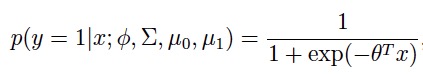
在这里,θ是Φ, μ0, μ1, Σ的一个函数。 更进一步,如果p(x|y)是一个多元正态分布(共享协方差矩阵Σ),那么p(y|x)将服从一个逻辑函数;但是反过来,如果p(y|x)是一个逻辑函数,那么p(x|y)不一定是一个多元正态分布。也就是说GDA与逻辑回归相比有更强的建模假设,如果这些假设是正确的,那么GDA将拟合出更好地模型,尤其是当p(x|y)确实是两个个共享协方差矩阵的多元正态分布时,那么GDA被成为asymptotically efficient(也就是当数据量很大时,没有算法能够比GDA更好),在这个背景下,即使数据量不大,我们任然会认为GDA的效果会优于逻辑回归。 但是,逻辑回归有更好地鲁棒性,不像GDA对建模的假设那么敏感,例如:如果 x|y=0 ~ Possion(λ0) x|y=1 ~ Possion(λ1),那么p(y|x)也将服从逻辑模型,但如果用GDA来建模的话,效果就会不理想。当数据确实不服从正态分布,并且数据量很大时,逻辑回归几乎总是优于GDA,因此在实践中,逻辑回归的使用要比GDA普遍。 接下来我们来看一个更为流行的生成学习算法:朴素贝叶斯
朴素贝叶斯 Naive Bayes
在GDA中,特征向量x都是连续型变量(对应于多元正态分布的随机变量),而朴素贝叶斯的特征向量x则均为离散型变量。
1.朴素贝叶斯(NB)假设
朴素贝叶斯模型常被用于文本分类中,比如垃圾邮件的甄别:从训练集中提取出的所有词去重之后得到一个词汇表(vaocabulary),每封邮件由一个特征向量表示(特征向量的长度与词汇表的长度相同),如果第i个词在邮件中出现则xi为1否则为0(p(xi|y)除了可以建模为贝努力分布,也可建模为多项分布)。最后,由输入的特征向量对邮件进行分类,判别是否为垃圾邮件。 现在对p(x|y)进行建模,假设我们的词汇表中有50000个词,如果用多项分布对x进行建模,那么将有 250000 种可能的结果,也就是会有 250000-1 个参数,这显然不太具有操作性。因此我们进行NB假设:xi条件独立于给定的y ==> p(x1|y) = p(x1|y, x2) 条件独立的典型例子:人的手臂长度与阅读能力条件独立于给定的年龄。(成年人相对于少年手更长,阅读能力也更强;但是当年龄一定时,手的长度与阅读能力就是相互独立的了) 这样,我们就可以大大削减参数的数量: 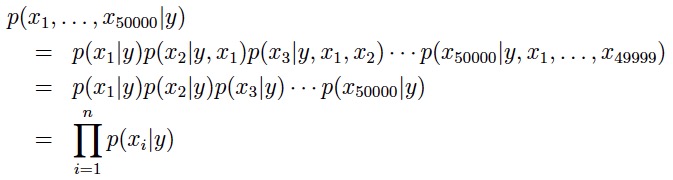
虽然这个假设的要求非常高,但是对于许多问题算法的结果还是足够好的。
2.模型
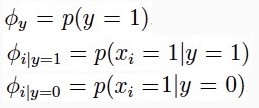
3.策略
极大化似然函数: 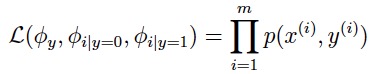
4.算法
极大化似然函数可以得到解析解: 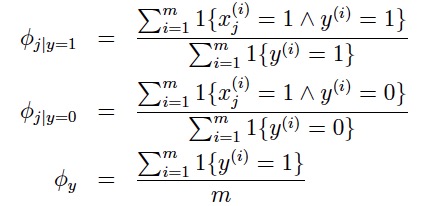
==> 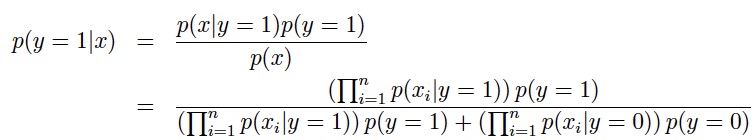
5.拉普拉斯平滑(Laplace smoothing)
将训练集中没出现过的情况的概率估计为0并不是一个好的想法,比如:垃圾邮件分类的问题中,当一封新的邮件中包含了训练集的词汇表中未曾出现过的新词,那么此时p(y=1|x) = p(y=0|x) = 0,将无法进行分类。 因此,我们有了拉普拉斯平滑。举例来说:多项分布的参数估计(m个训练样本,变量z的取值为{1,...,k}) 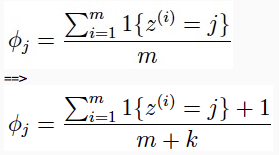
这样我们既保证了 
也使得未在训练集中出现的情况,不会被估计为0。 朴素贝叶斯的参数估计依据拉普拉斯平滑,可调整为: 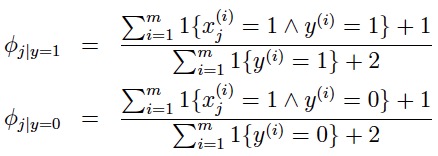
多项事件模型
专为文本分类而生。
1.模型
xi代表邮件中第i个词在词汇表中的索引(也就是xi在{1,...,|V|}中取值,|V|是词汇库的词汇量),n个词的邮件将由一个长度为n的向量代表,不同文章的向量长度将可能不相同。 在多项事件模型中,我们假设邮件是这样产生的:首先通过p(y)决定这是否是一封垃圾邮件,然后通过多项分布p(x|y)分别独立地决定每一个词。最终生成整个邮件的概率为 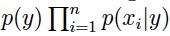
注:这里基于的假设是:每个词在一篇邮件中出现的概率,与其所在的位置无关。
2.策略
极大化似然函数: 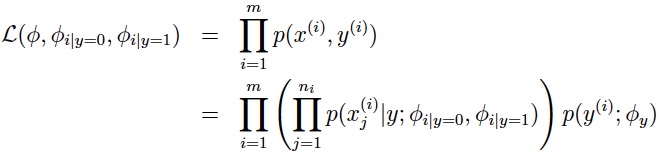
3.算法
极大化似然函数可以得到解析解: 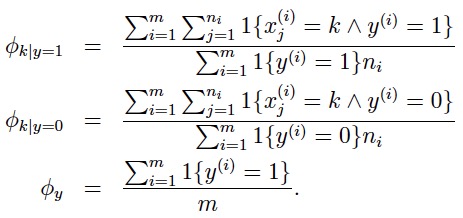
进行拉普拉斯平滑后得到: