本文主要分享一个在压测Nginx反向代理服务过程中碰到的连接异常断开问题,包括问题的定位与复现,最后由这个实际问题引申聊一下Nginx的连接管理。
本博客已迁移至CatBro's Blog,那是我自己搭建的个人博客,欢迎关注。
问题描述
问题是这样的,我们的Nginx服务是作为HTTP反向代理,前端是HTTPS,后端是HTTP。在一次压测过程中碰到了连接异常断开的问题,但是Nginx这边没有发现任何的错误日志(已经开了Info级别也没有)。因为是在客户那边进行的测试,而且是同事在对接的项目,我并不了解第一手的情况,包括测试方法、Nginx的配置等,唯一给到我这边的就是一个抓包,只有这个是确凿的信息,其余的就是一些零星的口头转述。同事多次尝试在公司复现这个问题但没有成功。
抓包的情况是这样的:
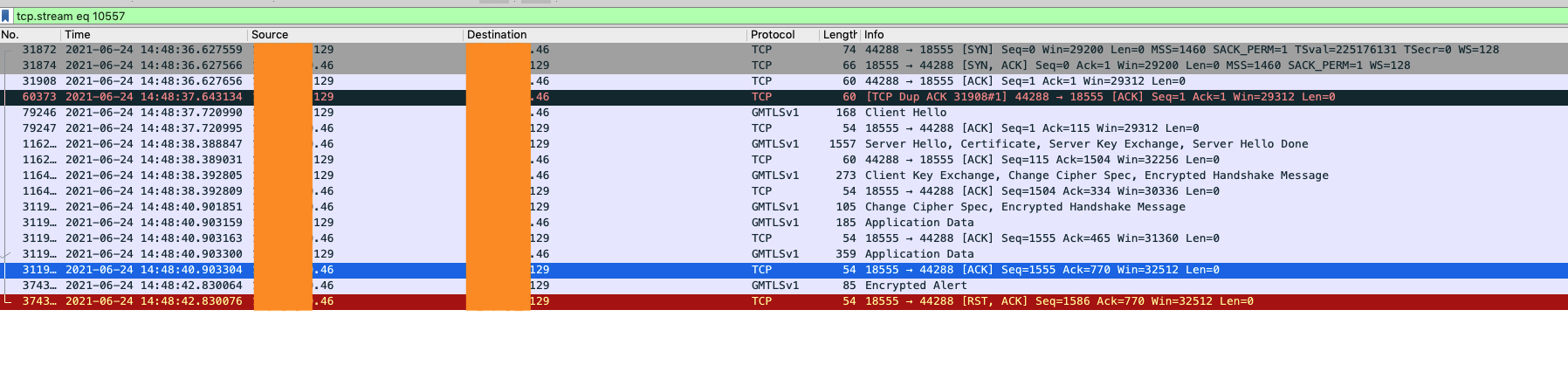
抓包文件很大,在一段很短的时间内出现很多连续的这种错误。上面的截图中是跟前端的交互,因为是压测的关系,短时间有大量的包,所以从抓包中无法确定对应的后端连接,不清楚后端连接是否已经建立,是否是后端出错了。
问题定位
我们首先分析下上图中抓包的情况,前面是一个GMVPN的握手,因为压测的关系,服务端回复ServerHello消息以及后面的ChangeCipherSpec消息都隔了一两秒的时间。握完手之后客户端发了两个应用数据包(对应HTTP请求头和请求体)。大概两秒之后,服务端发送了一个alert消息,然后紧接着发送了一个reset。
同事还观察到,抓包中从收到应用数据到连接断开的时间都是2s左右,所以猜测可能跟超时有关。reset的发送原因也是一个关键的线索,另外还有前面提到的Nginx日志(Info级别)中没有任何错误。我们就根据这几个线索来进行问题的定位,首先来分析reset的情况。
reset原因
有很多情况都会触发TCP的reset,其中大部分都是内核自身的行为。
-
端口没有监听
显然可以排除这种情况,我们的连接都已经开始处理了。
-
防火墙拦截
服务器并没有配置类似的防火墙策略,这种情况也排除。
-
向已经关闭的socket发送消息
socket可能是进程主动关闭,也可能是被动关闭,也就是进程崩了的情况。显然从抓包可以看出我们的进程并没有崩,况且进程崩了也会有内核日志。那如果是进程主动关闭socket的情况呢,我们从抓包中可以看到服务端是在发送了一个Encrypted Alert消息之后紧接着就发送了reset,其间并没有收到客户端的消息,所以也可以排除这种情况。
-
接收缓冲区还有数据未接收时关闭该socket
因为我们并不清楚后端连接的情况,所以抓包中的两个应用数据包是否已经被应用层接收是无法确定的。因此,这种情况是有可能的。
-
SO_LINGER
前面几种都是内核自发的行为,不需要用户参与。SO_LINGER是一个TCP选项,可以修改close()系统调用的行为。
- 默认不开的情况下,close调用会立即返回,发送队列一直保持到发送完成,连接通过正常的四次挥手进行关闭。
- 打开且时间设为0的情况下,直接丢弃发送缓冲区的数据,并发送RST给对方(不走4次挥手流程)。
- 打开且时间不为0的情况下,进程将阻塞直到1)所有数据发送完毕且收到对方确认,2)超时时间到。对于前者会正常关闭;对于后者,close将返回EWOULDBLOCK,然后跟第二种情况相同处理,即且丢弃发送缓冲区数据然后发送RST。这种情况socket必须是阻塞的,否则close会立即返回。
了解了SO_LINGER的情况,一看Nginx代码,确实是用到了这个选项,不过只有当连接超时并且打开了reset_timeout_connection配置项时才会去设置。而这个选项默认是关闭的,且我们也没有显式地设置过,所以这种情况也排除了。
if (r->connection->timedout) { clcf = ngx_http_get_module_loc_conf(r, ngx_http_core_module); if (clcf->reset_timedout_connection) { linger.l_onoff = 1; linger.l_linger = 0; if (setsockopt(r->connection->fd, SOL_SOCKET, SO_LINGER, (const void *) &linger, sizeof(struct linger)) == -1) { ngx_log_error(NGX_LOG_ALERT, log, ngx_socket_errno, "setsockopt(SO_LINGER) failed"); } } }
至此可以得出结论,reset的原因大概率就是因为接收缓冲区还有数据的时候关闭了连接。至于连接为什么被关闭,则还需要进一步定位。
连接关闭原因
接着前面的结论我们进一步排查,SSL握手显然是完成了,因为客户端已经发送了应用数据消息,所以在接收缓冲区中数据应该就是Application Data。至于请求头是否已经被读取目前还不好判断。不过从抓包可以看出,服务端是直接关闭的连接,并没有给客户端发送响应,所以可以确认服务端还没有走到应用层处理的环节,要么是还没有接收请求头、要么是还没处理完毕,否则肯定会有应用层的响应。于是问题的范围就缩小到了SSL握手完成之后、请求头处理完毕之前。
是不是之前提到的超时原因呢?不过同事又指出超时时间已经设置了很大(分钟级别),那会不会遗漏了某些超时呢。但是好像没有两秒这么短的超时时间,Nginx默认的超时基本都是60s级别的。于是开始寻找可能存在的超时,发现SSL阶段并没有单独的超时,在请求头读完之前就只有一个超时时间就是client_header_timeout,但是显然这个超时不是2s。我们合理假设是现场配置错了,但我在确认代码后发现如果是超时也是会有INFO级别日志,接收到请求前和接收到请求后都是如此。
所以超时这条路走不通了,大概率不是由于超时导致的连接关闭。没有办法只能继续看源码分析,看看从SSL握手完成到HTTP请求头处理完成之前,Nginx到底干了些什么。在详细看了这部分代码之后,一个在不同handler中多次出现的函数ngx_reusable_connection引起了我的注意。这个函数用于修改连接的reusable标记,并且ngx_cycle维护了一个resuable连接的队列,那么这个队列是干啥的呢?进一步探究发现,ngx_get_connection在获取新连接的时候,如果空闲的连接不足,会尝试重用部分reusable的连接(一次最多32个)。而nginx连接在完成SSL握手之后、接收到HTTP请求之前就是处于reusable状态的。我们再次打开抓包文件一数,发现连续关闭的连接正好是31/32个左右,于是我们已经有八九成的把握就是因为这个原因导致的连接断开,而且正好这种情况下我们使用版本的Nginx是没有日志的(高版本加了WARN级别日志)。
复现问题
为了进一步证明就是这个原因导致的连接断开,我尝试构造场景复现问题,这个问题的关键在于worker进程的总连接数不足,但是只建立前端连接又是够的,有很多连接停留在SSL握手完成又没有开始处理HTTP请求头的阶段。当其他连接的请求尝试建立后端连接时,就会把这些reusable连接踢掉。所以worker最大连接数需要大于前端连接数、小于前端连接数的两倍。
因为我是用自己虚拟机简单测试,客户端用wrk设置了100个连接,nginx只配了1个worker,最大连接数是120(具体数值可能有点出入,因为已经过去有段时间了记得不太清楚了)。一测试成功复现了这个问题,抓包截图如下:
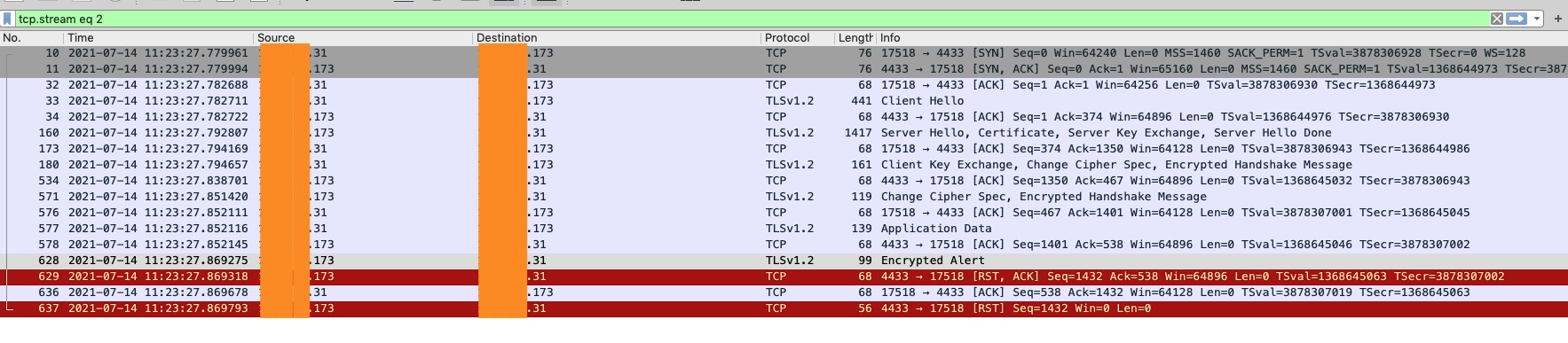
这是跟踪的其中一个流,可以看到也是在SSL握手完成之后,收到了客户端发送的应用数据,然后发送了Alert以及RST。顺带提一下,这里后面还多了一个RST,这是因为连接关闭之后收到了客户端的一个ACK。
再看下一个截图,可以观察到,在这两个reusable连接被踢掉之后,立马就往后端新建了两个连接。

至此,问题的原因基本已经确认。直接原因就是因为worker连接数不足。
总结回顾
问题原因已经定位到,再回过头看现场的测试配置。其实按照所有worker的连接总数来算,连接是够的,而单个worker则是不够的。但是因为其他几个配置的间接作用导致了连接集中在了单个worker中。首先,因为系统版本较低不支持reuseport,只能依赖nginx自身进行进程间的连接分配。其次又配置了multi_accept,所以只要有已经就绪的TCP连接,worker进程就一直进行accept,造成单个worker进程的接收了大部分连接。这几个因素结合在一起造成了最终的问题。归根结底,还是因为测试人员对Nginx配置理解不够深入导致的。
连接生命周期
在讨论前面的问题时我们也看到了,Nginx中的连接是有几个不同的状态的,我们分成连接建立时和连接关闭时两部分来看连接的生命周期。
连接建立
下面是连接建立时一个大致的调用关系图,实际情况要比着复杂的多。任何一处都可能超时或出错提前终止连接,碰到NGX_EAGAIN则可能多次调用同一个handler。
ngx_event_accept
|-- accept
|-- ngx_get_connection
+-- ngx_http_init_connection
|-- ngx_reusable_connection(1)
+-- ngx_http_ssl_handshake
|-- NGX_EAGAIN: ngx_reusable_connection(1)
|-- ngx_ssl_create_connection
|-- ngx_reusable_connection(0)
|-- ngx_ssl_handshake
+-- ngx_http_ssl_handshake_handler
|-- ngx_reusable_connection(1)
+-- ngx_http_wait_request_handler
|-- ngx_reusable_connection(0)
|-- ngx_http_create_request
+-- ngx_http_process_request_line
|-- ngx_http_read_request_header
|-- ngx_http_parse_request_line
+-- ngx_http_process_request_headers
|-- ngx_http_read_request_header
|-- ngx_http_parse_header_line
|-- ngx_http_process_request_header
+-- ngx_http_process_request
|-- Switch stat from reading to writing
+-- ngx_http_handler
|-- HTTP to HTTPS? certificate verify fail?
+-- ngx_http_core_run_phases
+-- ngx_http_proxy_handler
+-- ngx_http_read_client_request_body
首先,nginx是从accept才开始接手连接的处理,在此之前则完全是内核的行为。不过在初始化阶段可以通过设置一些socket选项来改变其行为,大家比较熟知的有比如SO_REUSEPORT,TCP_DEFER_ACCEPT。前者允许多个socket绑定到在相同的地址端口对上,由内核在多个进程的socket间进行连接接收的负载均衡,后者则可以推迟连接就绪的时间,只有当收到客户端发来的应用数据时才可以accept。
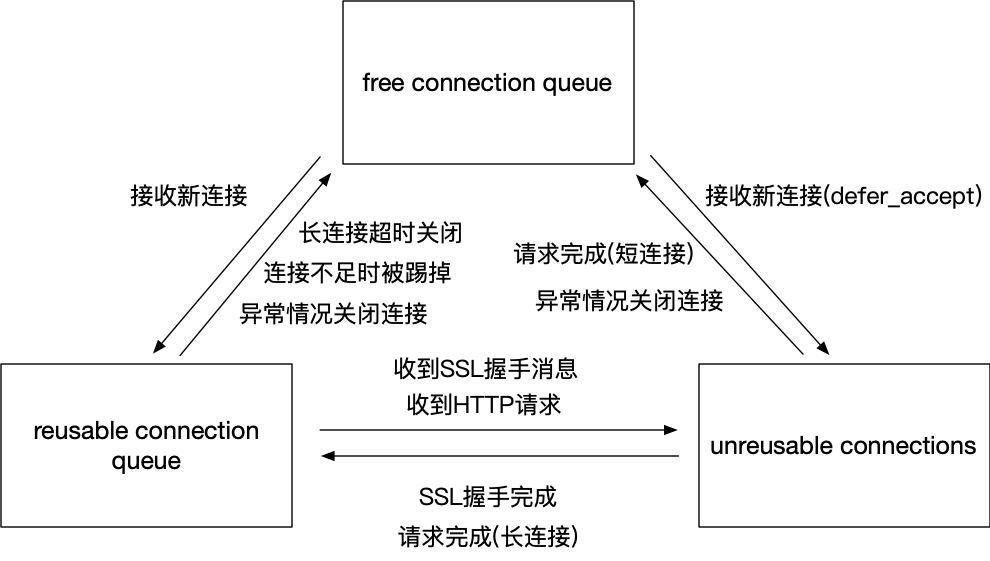
accept之后nginx会从空闲的连接中获取一个,这个动作在ngx_get_connection中完成,然后进入HTTP初始化流程。我们这里主要关注连接状态的变化情况,它是通过ngx_resuable_connection函数进行修改。最初连接是处于free状态的,进入ngx_http_ssl_handshake完成一些基本的初始化之后,连接设置定时器开始准备接收消息,此时的超时时间是post_accept_timeout,也就是配置项中的client_header_timeout,同步地连接进入reusable状态。等到接收到SSL握手消息之后,会创建SSL连接,同步地nginx连接进入unreusable状态。后续会进入握手流程,等到握手完成之后,连接又变成了reusable状态,开始等待接收HTTP请求,此时的超时时间仍然是post_accept_timeout。直到接收到HTTP请求,连接就此进入unreusable状态。一直到请求结束为止,状态都不再变化。
连接关闭
接下来再来看下请求结束时的情况,如果是短连接的情况会进入ngx_http_close_request流程,释放请求之后会关闭连接,连接变为free状态被放入空闲队列中。如果是长连接的情况则会进入ngx_http_set_keepalive流程,此时请求被释放,但是连接进入reusable状态,此时定时器的超时时间就是keepalive_timeout了。如果在超时时间内收到了新的请求,那么连接又变为unreusable状态,进入请求的处理流程;如果直到超时都没有收到新请求,则会调用ngx_http_close_connection关闭连接,连接变为free状态被放入空闲队列中。
值得注意的是,连接变成reusable状态时,肯定是处于等待什么消息的状态,同步地会有一个定时器存在。
ngx_http_finalize_request
+-- ngx_http_finalize_connection
|-- ngx_http_set_keepalive
| |-- ngx_http_free_request
| |-- ngx_reusable_connection(1)
| +-- ngx_http_keepalive_handler
| |-- ngx_http_close_connection
| |-- ngx_reusable_connection(0)
| |-- ngx_http_create_request
| +-- ngx_http_process_request_line
+-- ngx_http_close_request
|-- ngx_http_free_request
+-- ngx_http_close_connection
|-- ngx_ssl_shutdown
+-- ngx_close_connection
|-- ngx_reusable_connection(0)
|-- ngx_free_connection
+-- ngx_close_socket
为了更清晰地表示连接状态的转移情况,我们用一张图来描述:
连接超时
在连接的各个阶段都会伴随着超时的存在,只要不是进程正在处理当前连接,总会有某个定时器管着当前连接。以HTTP阶段为例,主要有以下这些超时:
- client_header_timeout (60s): 在这个时间内,这个请求头必须接收完。
- client_body_timeout (60s):读请求头的超时时间,只是限制两次连续操作之间的间隔
- send_timeout (60s):发送响应给客户端的超时时间,同样只是限制两次连续操作之间的间隔
- proxy_connect_timeout (60s):与后端服务器建立连接的超时
- proxy_send_timeout (60s):发送请求给代理服务器的超时,只是限制两次连续操作之间的间隔
- proxy_read_timeout (60s):从代理服务器读响应的超时,只是限制两次连续操作之间的间隔
- keepalive_timeout (75s):长连接保持打开的时间。
- resolver_timeout (5s): 域名解析的超时时间
连接的超时控制,当然是为了防止“坏”的连接一直占用系统资源。但是我们注意到,并不是所有超时都是限制总体的时间,很多超时都只是限制两次连续操作之间的间隔。所以一个恶意的连接,其实还是可以做到长时间占用一个连接的。比如客户端发送请求体时,每次只发一个字节,但是赶在服务端超时之前发送第二个字节。对于这种情况,貌似没有太好的避免办法。不过我们可以通过限速等其他手段,限制恶意方占用的连接个数,一定程度缓解了这个问题。