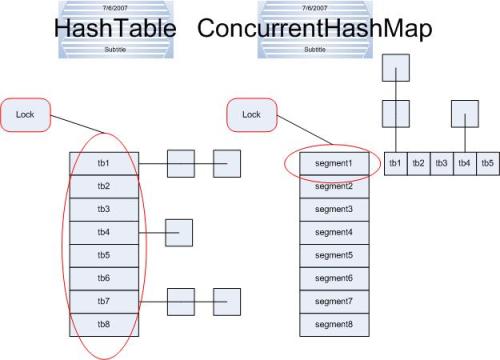
HashMap中未进行同步考虑,而Hashtable在每个方法上加上了synchronized,锁住了整个Hash表,一个时刻只能有一个线程操作,其他的线程则只能等待,在并发的环境下,这样的操作导致Hashtable的效率低下。
Collections的静态方法synchronizedMap(HashMap hm)返回的是一个SynchronizedMap对象,SynchronizedMap也是对原HashMap中的方法加上synchronized,锁的粒度应该减小。
ConcurrentHashMap的get读操作中基本没有用到锁,可以看下面的代码:
V get(Object key, int hash) { if (count != 0) { // read-volatile HashEntry<K,V> e = getFirst(hash); while (e != null) { if (e.hash == hash && key.equals(e.key)) { V v = e.value; if (v != null) return v; return readValueUnderLock(e); // recheck } e = e.next; } } return null; }
当读到的value是null时,处理是return readValueUnderLock(e);,因为整个的操作未加锁,上面的if (v != null)为false时,可能同时有其他线程修改了value的值,这里有进行一次同步的取值,如下:
V readValueUnderLock(HashEntry<K,V> e) { lock(); try { return e.value; } finally { unlock(); } }
size读操作为了确保读的数据是准确的也进行了部分的加锁操作。
写后读或者读后写都会造成数据的不一致,即使用线程安全类,应该做好对象的加锁。
ConcurrentHashMap的写操作锁住了Segment
public V put(K key, V value) { if (value == null) throw new NullPointerException(); int hash = hash(key.hashCode()); return segmentFor(hash).put(key, hash, value, false); }
下面是针对Segment的写操作:
V put(K key, int hash, V value, boolean onlyIfAbsent) { lock(); try { int c = count; if (c++ > threshold) // ensure capacity rehash(); HashEntry<K,V>[] tab = table; int index = hash & (tab.length - 1); HashEntry<K,V> first = tab[index]; HashEntry<K,V> e = first; while (e != null && (e.hash != hash || !key.equals(e.key))) e = e.next; V oldValue; if (e != null) { oldValue = e.value; if (!onlyIfAbsent) e.value = value; } else { oldValue = null; ++modCount; tab[index] = new HashEntry<K,V>(key, hash, first, value); count = c; // write-volatile } return oldValue; } finally { unlock(); } }
CopyOnWriteArrayList应用于读多写少的场景,对读操作不加锁,对写操作,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,并通过volatile 保证其可见性,当然写操作的锁是必不可少的了。
CopyOnWriteArrayList应用于读多写少的场景,在有较多写操作的情况下,CopyOnWriteArrayList性能不佳,而且如果容器容量较大的话容易造成溢出,应该使用Vector。使用ReadWriteLock是另外一种思路。
下面是的CopyOnWriteArrayList的set操作:
public E set(int index, E element) { final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); E oldValue = get(elements, index); if (oldValue != element) { int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len); newElements[index] = element; setArray(newElements); } else { // Not quite a no-op; ensures volatile write semantics setArray(elements); } return oldValue; } finally { lock.unlock(); } }
Arrays.copyOf创建一个新的数组,在新数组上做了修改后将新数组的引用赋给原对象。
private transient volatile Object[] array; final void setArray(Object[] a) { array = a; }
set方法中的
else { // Not quite a no-op; ensures volatile write semantics setArray(elements); }
元素都没有发生变化,为什么还要重新做一次赋值操作呢。
为了保持“volatile”的语义,任何一个读操作都应该是一个写操作的结果,也就是说线程的读操作看到的数据一定是某个线程写操作的结果。这里即使不设置也没有问题,仅仅是为了一个语义上的补充。
LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
注意,此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
LinkedHashMap中的Entry是这样的,维护了before Entry和after Entry。
static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }