使用poi写excel,数据量超过几万时可能会内存溢出。可以参考下面的2篇文章来解决。
https://blog.csdn.net/daiyutage/article/details/53010491?utm_source=blogxgwz9
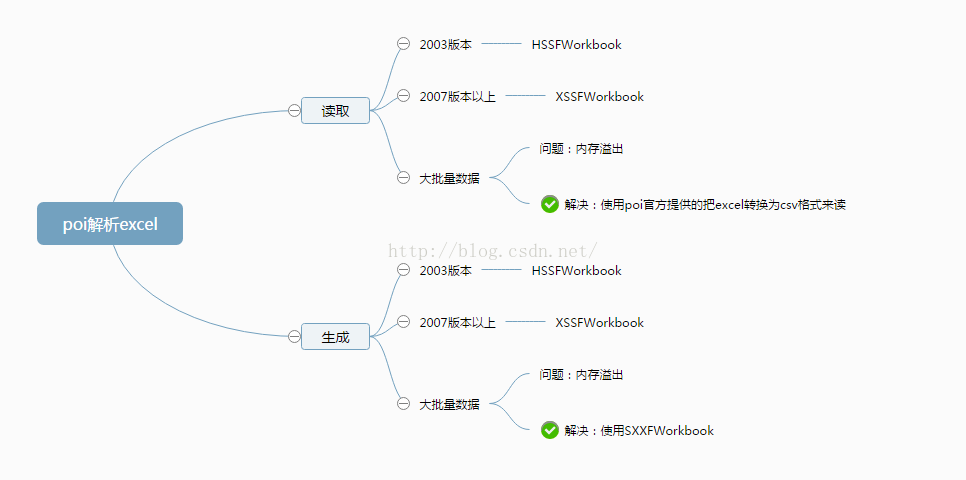
poi官网给了一种大批量数据写入的方法。
使用SXXFWorkbook 类进行大批量写入操作解决了这个问题。
import junit.framework.Assert; import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet; import org.apache.poi.ss.usermodel.Workbook; import org.apache.poi.ss.util.CellReference; import org.apache.poi.xssf.streaming.SXSSFWorkbook; public static void main(String[] args) throws Throwable { SXSSFWorkbook wb = new SXSSFWorkbook(100); // keep 100 rows in memory, exceeding rows will be flushed to disk Sheet sh = wb.createSheet(); for(int rownum = 0; rownum < 1000; rownum++){ Row row = sh.createRow(rownum); for(int cellnum = 0; cellnum < 10; cellnum++){ Cell cell = row.createCell(cellnum); String address = new CellReference(cell).formatAsString(); cell.setCellValue(address); } } // Rows with rownum < 900 are flushed and not accessible for(int rownum = 0; rownum < 900; rownum++){ Assert.assertNull(sh.getRow(rownum)); } // ther last 100 rows are still in memory for(int rownum = 900; rownum < 1000; rownum++){ Assert.assertNotNull(sh.getRow(rownum)); } FileOutputStream out = new FileOutputStream("/temp/sxssf.xlsx"); wb.write(out); out.close(); // dispose of temporary files backing this workbook on disk wb.dispose(); }
通过设置SXXFWorkbook的构造参数,可以设置每次在内存中保持的行数,当达到这个值的时候,那么会把这些数据flush到磁盘上,这样就不会出现内存不够的情况。
https://www.cnblogs.com/swordfall/p/8298386.html
1. Excel2003与Excel2007
两个版本的最大行数和列数不同,2003版最大行数是65536行,最大列数是256列,2007版及以后的版本最大行数是1048576行,最大列数是16384列。
excel2003是以二进制的方式存储,这种格式不易被其他软件读取使用;而excel2007采用了基于XML的ooxml开放文档标准,ooxml使用XML和ZIP技术结合进行文件存储,XML是一个基于文本的格式,而且ZIP容器支持内容的压缩,所以其一大优势是可以大大减小文件的尺寸。
2. 大批量数据读写

2.1 大批量数据写入
对于大数据的Xlsx文件的写入,POI3.8提供了SXSSFSXSSFWorkbook类,采用缓存方式进行大批量写文件。
详情可以查看poi官网示例:http://poi.apache.org/spreadsheet/how-to.html#sxssf 或 http://blog.csdn.net/daiyutage/article/details/53010491
2.2 大批量数据读取
POI读取Excel有两种模式,一种是用户模式,一种是SAX事件驱动模式,将xlsx格式的文档转换成CSV格式后进行读取。用户模式API接口丰富,使用POI的API可以很容易读取Excel,但用户模式消耗的内存很大,当遇到很大sheet、大数据网格,假空行、公式等问题时,很容易导致内存溢出。POI官方推荐解决内存溢出的方式使用CVS格式解析,即SAX事件驱动模式。下面主要是讲解如何读取大批量数据:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>POIExcel</groupId> <artifactId>POIExcel</artifactId> <packaging>war</packaging> <version>1.0-SNAPSHOT</version> <name>POIExcel Maven Webapp</name> <url>http://maven.apache.org</url> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>3.17</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.17</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml-schemas</artifactId> <version>3.17</version> </dependency> <dependency> <groupId>com.syncthemall</groupId> <artifactId>boilerpipe</artifactId> <version>1.2.1</version> </dependency> <dependency> <groupId>xerces</groupId> <artifactId>xercesImpl</artifactId> <version>2.11.0</version> </dependency> <dependency> <groupId>xml-apis</groupId> <artifactId>xml-apis</artifactId> <version>1.4.01</version> </dependency> <dependency> <groupId>org.apache.xmlbeans</groupId> <artifactId>xmlbeans</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>sax</groupId> <artifactId>sax</artifactId> <version>2.0.1</version> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.7</version> </dependency> </dependencies> <build> <finalName>POIExcel</finalName> </build> </project>
2.2.2 POI以SAX解析excel2007文件
解决思路:通过继承DefaultHandler类,重写process(),startElement(),characters(),endElement()这四个方法。process()方式主要是遍历所有的sheet,并依次调用startElement()、characters()方法、endElement()这三个方法。startElement()用于设定单元格的数字类型(如日期、数字、字符串等等)。characters()用于获取该单元格对应的索引值或是内容值(如果单元格类型是字符串、INLINESTR、数字、日期则获取的是索引值;其他如布尔值、错误、公式则获取的是内容值)。endElement()根据startElement()的单元格数字类型和characters()的索引值或内容值,最终得出单元格的内容值,并打印出来。
1 package org.poi; 2 3 import org.apache.poi.openxml4j.opc.OPCPackage; 4 import org.apache.poi.ss.usermodel.BuiltinFormats; 5 import org.apache.poi.ss.usermodel.DataFormatter; 6 import org.apache.poi.xssf.eventusermodel.XSSFReader; 7 import org.apache.poi.xssf.model.SharedStringsTable; 8 import org.apache.poi.xssf.model.StylesTable; 9 import org.apache.poi.xssf.usermodel.XSSFCellStyle; 10 import org.apache.poi.xssf.usermodel.XSSFRichTextString; 11 import org.xml.sax.Attributes; 12 import org.xml.sax.InputSource; 13 import org.xml.sax.SAXException; 14 import org.xml.sax.XMLReader; 15 import org.xml.sax.helpers.DefaultHandler; 16 import org.xml.sax.helpers.XMLReaderFactory; 17 18 import java.io.InputStream; 19 import java.util.ArrayList; 20 import java.util.List; 21 22 /** 23 * @author y 24 * @create 2018-01-18 14:28 25 * @desc POI读取excel有两种模式,一种是用户模式,一种是事件驱动模式 26 * 采用SAX事件驱动模式解决XLSX文件,可以有效解决用户模式内存溢出的问题, 27 * 该模式是POI官方推荐的读取大数据的模式, 28 * 在用户模式下,数据量较大,Sheet较多,或者是有很多无用的空行的情况下,容易出现内存溢出 29 * <p> 30 * 用于解决.xlsx2007版本大数据量问题 31 **/ 32 public class ExcelXlsxReader extends DefaultHandler { 33 34 /** 35 * 单元格中的数据可能的数据类型 36 */ 37 enum CellDataType { 38 BOOL, ERROR, FORMULA, INLINESTR, SSTINDEX, NUMBER, DATE, NULL 39 } 40 41 /** 42 * 共享字符串表 43 */ 44 private SharedStringsTable sst; 45 46 /** 47 * 上一次的索引值 48 */ 49 private String lastIndex; 50 51 /** 52 * 文件的绝对路径 53 */ 54 private String filePath = ""; 55 56 /** 57 * 工作表索引 58 */ 59 private int sheetIndex = 0; 60 61 /** 62 * sheet名 63 */ 64 private String sheetName = ""; 65 66 /** 67 * 总行数 68 */ 69 private int totalRows=0; 70 71 /** 72 * 一行内cell集合 73 */ 74 private List<String> cellList = new ArrayList<String>(); 75 76 /** 77 * 判断整行是否为空行的标记 78 */ 79 private boolean flag = false; 80 81 /** 82 * 当前行 83 */ 84 private int curRow = 1; 85 86 /** 87 * 当前列 88 */ 89 private int curCol = 0; 90 91 /** 92 * T元素标识 93 */ 94 private boolean isTElement; 95 96 /** 97 * 判断上一单元格是否为文本空单元格 98 */ 99 private boolean startElementFlag = true; 100 private boolean endElementFlag = false; 101 private boolean charactersFlag = false; 102 103 /** 104 * 异常信息,如果为空则表示没有异常 105 */ 106 private String exceptionMessage; 107 108 /** 109 * 单元格数据类型,默认为字符串类型 110 */ 111 private CellDataType nextDataType = CellDataType.SSTINDEX; 112 113 private final DataFormatter formatter = new DataFormatter(); 114 115 /** 116 * 单元格日期格式的索引 117 */ 118 private short formatIndex; 119 120 /** 121 * 日期格式字符串 122 */ 123 private String formatString; 124 125 //定义前一个元素和当前元素的位置,用来计算其中空的单元格数量,如A6和A8等 126 private String prePreRef = "A", preRef = null, ref = null; 127 128 //定义该文档一行最大的单元格数,用来补全一行最后可能缺失的单元格 129 private String maxRef = null; 130 131 /** 132 * 单元格 133 */ 134 private StylesTable stylesTable; 135 136 /** 137 * 遍历工作簿中所有的电子表格 138 * 并缓存在mySheetList中 139 * 140 * @param filename 141 * @throws Exception 142 */ 143 public int process(String filename) throws Exception { 144 filePath = filename; 145 OPCPackage pkg = OPCPackage.open(filename); 146 XSSFReader xssfReader = new XSSFReader(pkg); 147 stylesTable = xssfReader.getStylesTable(); 148 SharedStringsTable sst = xssfReader.getSharedStringsTable(); 149 XMLReader parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser"); 150 this.sst = sst; 151 parser.setContentHandler(this); 152 XSSFReader.SheetIterator sheets = (XSSFReader.SheetIterator) xssfReader.getSheetsData(); 153 while (sheets.hasNext()) { //遍历sheet 154 curRow = 1; //标记初始行为第一行 155 sheetIndex++; 156 InputStream sheet = sheets.next(); //sheets.next()和sheets.getSheetName()不能换位置,否则sheetName报错 157 sheetName = sheets.getSheetName(); 158 InputSource sheetSource = new InputSource(sheet); 159 parser.parse(sheetSource); //解析excel的每条记录,在这个过程中startElement()、characters()、endElement()这三个函数会依次执行 160 sheet.close(); 161 } 162 return totalRows; //返回该excel文件的总行数,不包括首列和空行 163 } 164 165 /** 166 * 第一个执行 167 * 168 * @param uri 169 * @param localName 170 * @param name 171 * @param attributes 172 * @throws SAXException 173 */ 174 @Override 175 public void startElement(String uri, String localName, String name, Attributes attributes) throws SAXException { 176 //c => 单元格 177 if ("c".equals(name)) { 178 179 //前一个单元格的位置 180 if (preRef == null) { 181 preRef = attributes.getValue("r"); 182 183 } else { 184 //中部文本空单元格标识 ‘endElementFlag’ 判断前一次是否为文本空字符串,true则表明不是文本空字符串,false表明是文本空字符串跳过把空字符串的位置赋予preRef 185 if (endElementFlag){ 186 preRef = ref; 187 } 188 } 189 190 //当前单元格的位置 191 ref = attributes.getValue("r"); 192 //首部文本空单元格标识 ‘startElementFlag’ 判断前一次,即首部是否为文本空字符串,true则表明不是文本空字符串,false表明是文本空字符串, 且已知当前格,即第二格带“B”标志,则ref赋予preRef 193 if (!startElementFlag && !flag){ //上一个单元格为文本空单元格,执行下面的,使ref=preRef;flag为true表明该单元格之前有数据值,即该单元格不是首部空单元格,则跳过 194 // 这里只有上一个单元格为文本空单元格,且之前的几个单元格都没有值才会执行 195 preRef = ref; 196 } 197 198 //设定单元格类型 199 this.setNextDataType(attributes); 200 endElementFlag = false; 201 charactersFlag = false; 202 startElementFlag = false; 203 } 204 205 //当元素为t时 206 if ("t".equals(name)) { 207 isTElement = true; 208 } else { 209 isTElement = false; 210 } 211 212 //置空 213 lastIndex = ""; 214 } 215 216 217 218 /** 219 * 第二个执行 220 * 得到单元格对应的索引值或是内容值 221 * 如果单元格类型是字符串、INLINESTR、数字、日期,lastIndex则是索引值 222 * 如果单元格类型是布尔值、错误、公式,lastIndex则是内容值 223 * @param ch 224 * @param start 225 * @param length 226 * @throws SAXException 227 */ 228 @Override 229 public void characters(char[] ch, int start, int length) throws SAXException { 230 startElementFlag = true; 231 charactersFlag = true; 232 lastIndex += new String(ch, start, length); 233 } 234 235 /** 236 * 第三个执行 237 * 238 * @param uri 239 * @param localName 240 * @param name 241 * @throws SAXException 242 */ 243 @Override 244 public void endElement(String uri, String localName, String name) throws SAXException { 245 //t元素也包含字符串 246 if (isTElement) {//这个程序没经过 247 //将单元格内容加入rowlist中,在这之前先去掉字符串前后的空白符 248 String value = lastIndex.trim(); 249 cellList.add(curCol, value); 250 endElementFlag = true; 251 curCol++; 252 isTElement = false; 253 //如果里面某个单元格含有值,则标识该行不为空行 254 if (value != null && !"".equals(value)) { 255 flag = true; 256 } 257 } else if ("v".equals(name)) { 258 //v => 单元格的值,如果单元格是字符串,则v标签的值为该字符串在SST中的索引 259 String value = this.getDataValue(lastIndex.trim(), "");//根据索引值获取对应的单元格值 260 261 //补全单元格之间的空单元格 262 if (!ref.equals(preRef)) { 263 int len = countNullCell(ref, preRef); 264 for (int i = 0; i < len; i++) { 265 cellList.add(curCol, ""); 266 curCol++; 267 } 268 } else if (ref.equals(preRef) && !ref.startWith("A")){ //ref等于preRef,且以B或者C...开头,表明首部为空格271 int len = countNullCell(ref, "A"); 272 for (int i = 0; i <= len; i++) { 273 cellList.add(curCol, ""); 274 curCol++; 275 } 276 } 277 cellList.add(curCol, value); 278 curCol++; 279 endElementFlag = true; 280 //如果里面某个单元格含有值,则标识该行不为空行 281 if (value != null && !"".equals(value)) { 282 flag = true; 283 } 284 } else { 285 //如果标签名称为row,这说明已到行尾,调用optRows()方法 286 if ("row".equals(name)) { 287 //默认第一行为表头,以该行单元格数目为最大数目 288 if (curRow == 1) { 289 maxRef = ref; 290 } 291 //补全一行尾部可能缺失的单元格 292 if (maxRef != null) { 293 int len = -1; 294 //前一单元格,true则不是文本空字符串,false则是文本空字符串 295 if (charactersFlag){ 296 len = countNullCell(maxRef, ref); 297 }else { 298 len = countNullCell(maxRef, preRef); 299 } 300 for (int i = 0; i <= len; i++) { 301 cellList.add(curCol, ""); 302 curCol++; 303 } 304 } 305 306 if (flag&&curRow!=1){ //该行不为空行且该行不是第一行,则发送(第一行为列名,不需要) 307 ExcelReaderUtil.sendRows(filePath, sheetName, sheetIndex, curRow, cellList); 308 totalRows++; 309 } 310 311 cellList.clear(); 312 curRow++; 313 curCol = 0; 314 preRef = null; 315 prePreRef = null; 316 ref = null; 317 flag=false; 318 } 319 } 320 } 321 322 /** 323 * 处理数据类型 324 * 325 * @param attributes 326 */ 327 public void setNextDataType(Attributes attributes) { 328 nextDataType = CellDataType.NUMBER; //cellType为空,则表示该单元格类型为数字 329 formatIndex = -1; 330 formatString = null; 331 String cellType = attributes.getValue("t"); //单元格类型 332 String cellStyleStr = attributes.getValue("s"); // 333 String columnData = attributes.getValue("r"); //获取单元格的位置,如A1,B1 334 335 if ("b".equals(cellType)) { //处理布尔值 336 nextDataType = CellDataType.BOOL; 337 } else if ("e".equals(cellType)) { //处理错误 338 nextDataType = CellDataType.ERROR; 339 } else if ("inlineStr".equals(cellType)) { 340 nextDataType = CellDataType.INLINESTR; 341 } else if ("s".equals(cellType)) { //处理字符串 342 nextDataType = CellDataType.SSTINDEX; 343 } else if ("str".equals(cellType)) { 344 nextDataType = CellDataType.FORMULA; 345 } 346 347 if (cellStyleStr != null) { //处理日期 348 int styleIndex = Integer.parseInt(cellStyleStr); 349 XSSFCellStyle style = stylesTable.getStyleAt(styleIndex); 350 formatIndex = style.getDataFormat(); 351 formatString = style.getDataFormatString(); 352 if (formatString.contains("m/d/yyyy") || formatString.contains("yyyy/mm/dd")|| formatString.contains("yyyy/m/d") ) { 353 nextDataType = CellDataType.DATE; 354 formatString = "yyyy-MM-dd hh:mm:ss"; 355 } 356 357 if (formatString == null) { 358 nextDataType = CellDataType.NULL; 359 formatString = BuiltinFormats.getBuiltinFormat(formatIndex); 360 } 361 } 362 } 363 364 /** 365 * 对解析出来的数据进行类型处理 366 * @param value 单元格的值, 367 * value代表解析:BOOL的为0或1, ERROR的为内容值,FORMULA的为内容值,INLINESTR的为索引值需转换为内容值, 368 * SSTINDEX的为索引值需转换为内容值, NUMBER为内容值,DATE为内容值 369 * @param thisStr 一个空字符串 370 * @return 371 */ 372 @SuppressWarnings("deprecation") 373 public String getDataValue(String value, String thisStr) { 374 switch (nextDataType) { 375 // 这几个的顺序不能随便交换,交换了很可能会导致数据错误 376 case BOOL: //布尔值 377 char first = value.charAt(0); 378 thisStr = first == '0' ? "FALSE" : "TRUE"; 379 break; 380 case ERROR: //错误 381 thisStr = ""ERROR:" + value.toString() + '"'; 382 break; 383 case FORMULA: //公式 384 thisStr = '"' + value.toString() + '"'; 385 break; 386 case INLINESTR: 387 XSSFRichTextString rtsi = new XSSFRichTextString(value.toString()); 388 thisStr = rtsi.toString(); 389 rtsi = null; 390 break; 391 case SSTINDEX: //字符串 392 String sstIndex = value.toString(); 393 try { 394 int idx = Integer.parseInt(sstIndex); 395 XSSFRichTextString rtss = new XSSFRichTextString(sst.getEntryAt(idx));//根据idx索引值获取内容值 396 thisStr = rtss.toString(); 397 System.out.println(thisStr); 398 //有些字符串是文本格式的,但内容却是日期 399 400 rtss = null; 401 } catch (NumberFormatException ex) { 402 thisStr = value.toString(); 403 } 404 break; 405 case NUMBER: //数字 406 if (formatString != null) { 407 thisStr = formatter.formatRawCellContents(Double.parseDouble(value), formatIndex, formatString).trim(); 408 } else { 409 thisStr = value; 410 } 411 thisStr = thisStr.replace("_", "").trim(); 412 break; 413 case DATE: //日期 414 thisStr = formatter.formatRawCellContents(Double.parseDouble(value), formatIndex, formatString); 415 // 对日期字符串作特殊处理,去掉T 416 thisStr = thisStr.replace("T", " "); 417 break; 418 default: 419 thisStr = " "; 420 break; 421 } 422 return thisStr; 423 } 424 425 public int countNullCell(String ref, String preRef) { 426 //excel2007最大行数是1048576,最大列数是16384,最后一列列名是XFD 427 String xfd = ref.replaceAll("\d+", ""); 428 String xfd_1 = preRef.replaceAll("\d+", ""); 429 430 xfd = fillChar(xfd, 3, '@', true); 431 xfd_1 = fillChar(xfd_1, 3, '@', true); 432 433 char[] letter = xfd.toCharArray(); 434 char[] letter_1 = xfd_1.toCharArray(); 435 int res = (letter[0] - letter_1[0]) * 26 * 26 + (letter[1] - letter_1[1]) * 26 + (letter[2] - letter_1[2]); 436 return res - 1; 437 } 438 439 public String fillChar(String str, int len, char let, boolean isPre) { 440 int len_1 = str.length(); 441 if (len_1 < len) { 442 if (isPre) { 443 for (int i = 0; i < (len - len_1); i++) { 444 str = let + str; 445 } 446 } else { 447 for (int i = 0; i < (len - len_1); i++) { 448 str = str + let; 449 } 450 } 451 } 452 return str; 453 } 454 455 /** 456 * @return the exceptionMessage 457 */ 458 public String getExceptionMessage() { 459 return exceptionMessage; 460 } 461 }
2.2.3 POI通过继承HSSFListener类来解决Excel2003文件
解决思路:重写process(),processRecord()两个方法,其中processRecord是核心方法,用于处理sheetName和各种单元格数字类型。
package org.poi; import org.apache.poi.hssf.eventusermodel.*; import org.apache.poi.hssf.eventusermodel.dummyrecord.LastCellOfRowDummyRecord; import org.apache.poi.hssf.eventusermodel.dummyrecord.MissingCellDummyRecord; import org.apache.poi.hssf.model.HSSFFormulaParser; import org.apache.poi.hssf.record.*; import org.apache.poi.hssf.usermodel.HSSFDataFormatter; import org.apache.poi.hssf.usermodel.HSSFWorkbook; import org.apache.poi.poifs.filesystem.POIFSFileSystem; import java.io.FileInputStream; import java.util.ArrayList; import java.util.List; /** * @author y * @create 2018-01-19 14:18 * @desc 用于解决.xls2003版本大数据量问题 **/ public class ExcelXlsReader implements HSSFListener { private int minColums = -1; private POIFSFileSystem fs; /** * 总行数 */ private int totalRows=0; /** * 上一行row的序号 */ private int lastRowNumber; /** * 上一单元格的序号 */ private int lastColumnNumber; /** * 是否输出formula,还是它对应的值 */ private boolean outputFormulaValues = true; /** * 用于转换formulas */ private EventWorkbookBuilder.SheetRecordCollectingListener workbookBuildingListener; //excel2003工作簿 private HSSFWorkbook stubWorkbook; private SSTRecord sstRecord; private FormatTrackingHSSFListener formatListener; private final HSSFDataFormatter formatter = new HSSFDataFormatter(); /** * 文件的绝对路径 */ private String filePath = ""; //表索引 private int sheetIndex = 0; private BoundSheetRecord[] orderedBSRs; @SuppressWarnings("unchecked") private ArrayList boundSheetRecords = new ArrayList(); private int nextRow; private int nextColumn; private boolean outputNextStringRecord; //当前行 private int curRow = 0; //存储一行记录所有单元格的容器 private List<String> cellList = new ArrayList<String>(); /** * 判断整行是否为空行的标记 */ private boolean flag = false; @SuppressWarnings("unused") private String sheetName; /** * 遍历excel下所有的sheet * * @param fileName * @throws Exception */ public int process(String fileName) throws Exception { filePath = fileName; this.fs = new POIFSFileSystem(new FileInputStream(fileName)); MissingRecordAwareHSSFListener listener = new MissingRecordAwareHSSFListener(this); formatListener = new FormatTrackingHSSFListener(listener); HSSFEventFactory factory = new HSSFEventFactory(); HSSFRequest request = new HSSFRequest(); if (outputFormulaValues) { request.addListenerForAllRecords(formatListener); } else { workbookBuildingListener = new EventWorkbookBuilder.SheetRecordCollectingListener(formatListener); request.addListenerForAllRecords(workbookBuildingListener); } factory.processWorkbookEvents(request, fs); return totalRows; //返回该excel文件的总行数,不包括首列和空行 } /** * HSSFListener 监听方法,处理Record * 处理每个单元格 * @param record */ @SuppressWarnings("unchecked") public void processRecord(Record record) { int thisRow = -1; int thisColumn = -1; String thisStr = null; String value = null; switch (record.getSid()) { case BoundSheetRecord.sid: boundSheetRecords.add(record); break; case BOFRecord.sid: //开始处理每个sheet BOFRecord br = (BOFRecord) record; if (br.getType() == BOFRecord.TYPE_WORKSHEET) { //如果有需要,则建立子工作簿 if (workbookBuildingListener != null && stubWorkbook == null) { stubWorkbook = workbookBuildingListener.getStubHSSFWorkbook(); } if (orderedBSRs == null) { orderedBSRs = BoundSheetRecord.orderByBofPosition(boundSheetRecords); } sheetName = orderedBSRs[sheetIndex].getSheetname(); sheetIndex++; } break; case SSTRecord.sid: sstRecord = (SSTRecord) record; break; case BlankRecord.sid: //单元格为空白 BlankRecord brec = (BlankRecord) record; thisRow = brec.getRow(); thisColumn = brec.getColumn(); thisStr = ""; cellList.add(thisColumn, thisStr); break; case BoolErrRecord.sid: //单元格为布尔类型 BoolErrRecord berec = (BoolErrRecord) record; thisRow = berec.getRow(); thisColumn = berec.getColumn(); thisStr = berec.getBooleanValue() + ""; cellList.add(thisColumn, thisStr); checkRowIsNull(thisStr); //如果里面某个单元格含有值,则标识该行不为空行 break; case FormulaRecord.sid://单元格为公式类型 FormulaRecord frec = (FormulaRecord) record; thisRow = frec.getRow(); thisColumn = frec.getColumn(); if (outputFormulaValues) { if (Double.isNaN(frec.getValue())) { outputNextStringRecord = true; nextRow = frec.getRow(); nextColumn = frec.getColumn(); } else { thisStr = '"' + HSSFFormulaParser.toFormulaString(stubWorkbook, frec.getParsedExpression()) + '"'; } } else { thisStr = '"' + HSSFFormulaParser.toFormulaString(stubWorkbook, frec.getParsedExpression()) + '"'; } cellList.add(thisColumn, thisStr); checkRowIsNull(thisStr); //如果里面某个单元格含有值,则标识该行不为空行 break; case StringRecord.sid: //单元格中公式的字符串 if (outputNextStringRecord) { StringRecord srec = (StringRecord) record; thisStr = srec.getString(); thisRow = nextRow; thisColumn = nextColumn; outputNextStringRecord = false; } break; case LabelRecord.sid: LabelRecord lrec = (LabelRecord) record; curRow = thisRow = lrec.getRow(); thisColumn = lrec.getColumn(); value = lrec.getValue().trim(); value = value.equals("") ? "" : value; cellList.add(thisColumn, value); checkRowIsNull(value); //如果里面某个单元格含有值,则标识该行不为空行 break; case LabelSSTRecord.sid: //单元格为字符串类型 LabelSSTRecord lsrec = (LabelSSTRecord) record; curRow = thisRow = lsrec.getRow(); thisColumn = lsrec.getColumn(); if (sstRecord == null) { cellList.add(thisColumn, ""); } else { value = sstRecord.getString(lsrec.getSSTIndex()).toString().trim(); value = value.equals("") ? "" : value; cellList.add(thisColumn, value); checkRowIsNull(value); //如果里面某个单元格含有值,则标识该行不为空行 } break; case NumberRecord.sid: //单元格为数字类型 NumberRecord numrec = (NumberRecord) record; curRow = thisRow = numrec.getRow(); thisColumn = numrec.getColumn(); //第一种方式 //value = formatListener.formatNumberDateCell(numrec).trim();//这个被写死,采用的m/d/yy h:mm格式,不符合要求 //第二种方式,参照formatNumberDateCell里面的实现方法编写 Double valueDouble=((NumberRecord)numrec).getValue(); String formatString=formatListener.getFormatString(numrec); if (formatString.contains("m/d/yy")){ formatString="yyyy-MM-dd hh:mm:ss"; } int formatIndex=formatListener.getFormatIndex(numrec); value=formatter.formatRawCellContents(valueDouble, formatIndex, formatString).trim(); value = value.equals("") ? "" : value; //向容器加入列值 cellList.add(thisColumn, value); checkRowIsNull(value); //如果里面某个单元格含有值,则标识该行不为空行 break; default: break; } //遇到新行的操作 if (thisRow != -1 && thisRow != lastRowNumber) { lastColumnNumber = -1; } //空值的操作 if (record instanceof MissingCellDummyRecord) { MissingCellDummyRecord mc = (MissingCellDummyRecord) record; curRow = thisRow = mc.getRow(); thisColumn = mc.getColumn(); cellList.add(thisColumn, ""); } //更新行和列的值 if (thisRow > -1) lastRowNumber = thisRow; if (thisColumn > -1) lastColumnNumber = thisColumn; //行结束时的操作 if (record instanceof LastCellOfRowDummyRecord) { if (minColums > 0) { //列值重新置空 if (lastColumnNumber == -1) { lastColumnNumber = 0; } } lastColumnNumber = -1; if (flag&&curRow!=0) { //该行不为空行且该行不是第一行,发送(第一行为列名,不需要) ExcelReaderUtil.sendRows(filePath, sheetName, sheetIndex, curRow + 1, cellList); //每行结束时,调用sendRows()方法 totalRows++; } //清空容器 cellList.clear(); flag=false; } } /** * 如果里面某个单元格含有值,则标识该行不为空行 * @param value */ public void checkRowIsNull(String value){ if (value != null && !"".equals(value)) { flag = true; } } }
2.2.4 辅助类ExcelReaderUtil
调用ExcelXlsReader类和ExcelXlsxReader类对excel2003和excel2007两个版本进行大批量数据读取:
package org.poi; import java.util.List; /** * @author y * @create 2018-01-19 0:13 * @desc **/ public class ExcelReaderUtil { //excel2003扩展名 public static final String EXCEL03_EXTENSION = ".xls"; //excel2007扩展名 public static final String EXCEL07_EXTENSION = ".xlsx"; /** * 每获取一条记录,即打印 * 在flume里每获取一条记录即发送,而不必缓存起来,可以大大减少内存的消耗,这里主要是针对flume读取大数据量excel来说的 * @param sheetName * @param sheetIndex * @param curRow * @param cellList */ public static void sendRows(String filePath, String sheetName, int sheetIndex, int curRow, List<String> cellList) { StringBuffer oneLineSb = new StringBuffer(); oneLineSb.append(filePath); oneLineSb.append("--"); oneLineSb.append("sheet" + sheetIndex); oneLineSb.append("::" + sheetName);//加上sheet名 oneLineSb.append("--"); oneLineSb.append("row" + curRow); oneLineSb.append("::"); for (String cell : cellList) { oneLineSb.append(cell.trim()); oneLineSb.append("|"); } String oneLine = oneLineSb.toString(); if (oneLine.endsWith("|")) { oneLine = oneLine.substring(0, oneLine.lastIndexOf("|")); }// 去除最后一个分隔符 System.out.println(oneLine); } public static void readExcel(String fileName) throws Exception { int totalRows =0; if (fileName.endsWith(EXCEL03_EXTENSION)) { //处理excel2003文件 ExcelXlsReader excelXls=new ExcelXlsReader(); totalRows =excelXls.process(fileName); } else if (fileName.endsWith(EXCEL07_EXTENSION)) {//处理excel2007文件 ExcelXlsxReader excelXlsxReader = new ExcelXlsxReader(); totalRows = excelXlsxReader.process(fileName); } else { throw new Exception("文件格式错误,fileName的扩展名只能是xls或xlsx。"); } System.out.println("发送的总行数:" + totalRows); } public static void main(String[] args) throws Exception { String path="C:\Users\y****\Desktop\TestSample\H_20171226_***_*****_0430.xlsx"; ExcelReaderUtil.readExcel(path); } }
github地址:
https://github.com/SwordfallYeung/POIExcel