Levels of Abstraction
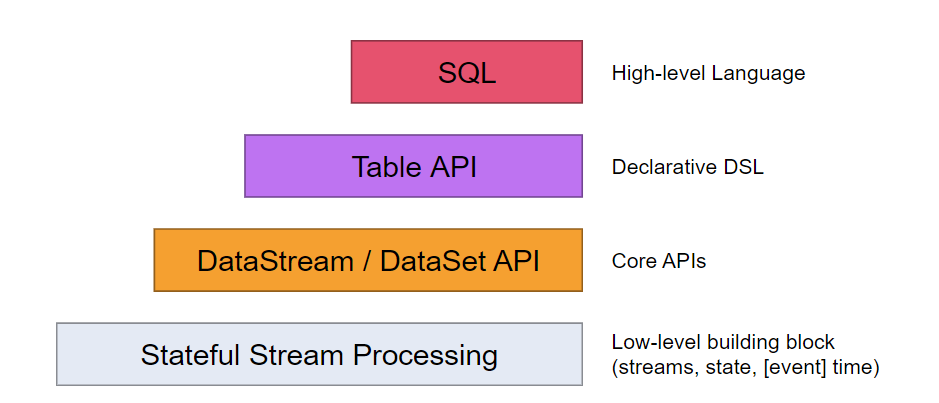
flink 提供了不同层次的API来进行 流处理 或者批处理
- 最低层次的抽象 提供了有状态的流 通过 Process Function 嵌入到 DataStream API 当中去,它允许用户自由的处理events,并且使用state,另外用户可以注册event time and processing time回调函数,它允许程序实现复杂的业务逻辑。
- 更高层次的是DataStream API (bounded/unbounded streams) and the DataSet API (bounded data sets),这些API提供了一些常规的操作如transformations, joins, aggregations, windows, state。
- Table API 是一种以表为中心的DSL,提供了如select, project, join, group-by, aggregate的操作,它是一种更简洁的API。
- 最高层次的是SQL。
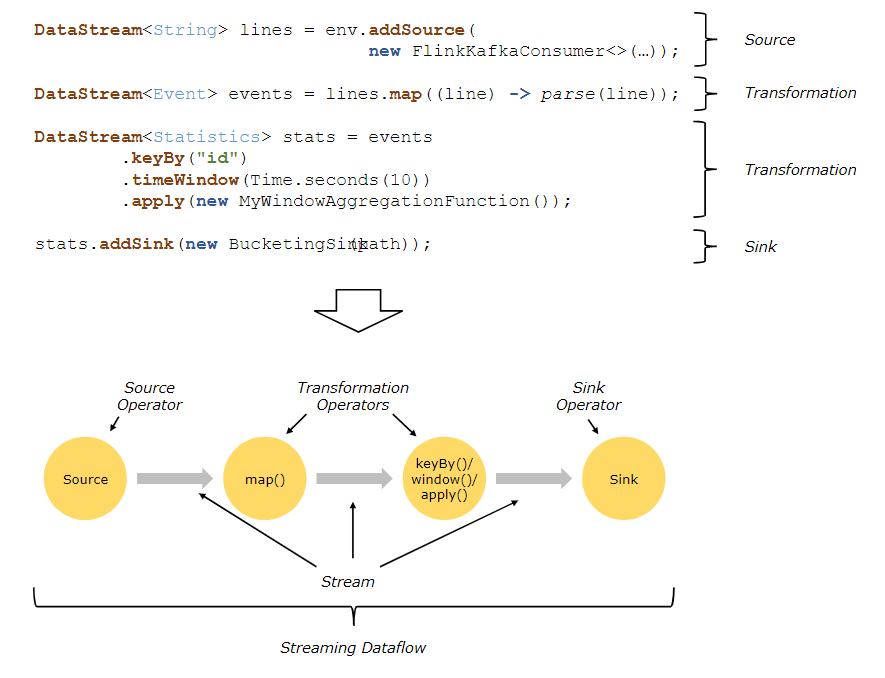
Programs and Dataflows
Parallel Dataflows
flink天生就是并行分布式的,一个stream会有多个stream partitions。一个operator会有多个operator subtasks,operator subtasks彼此独立,它们可能在不同的机器 容器 再或者 线程当中分别执行。
operator subtasks的数量取决于并行度,
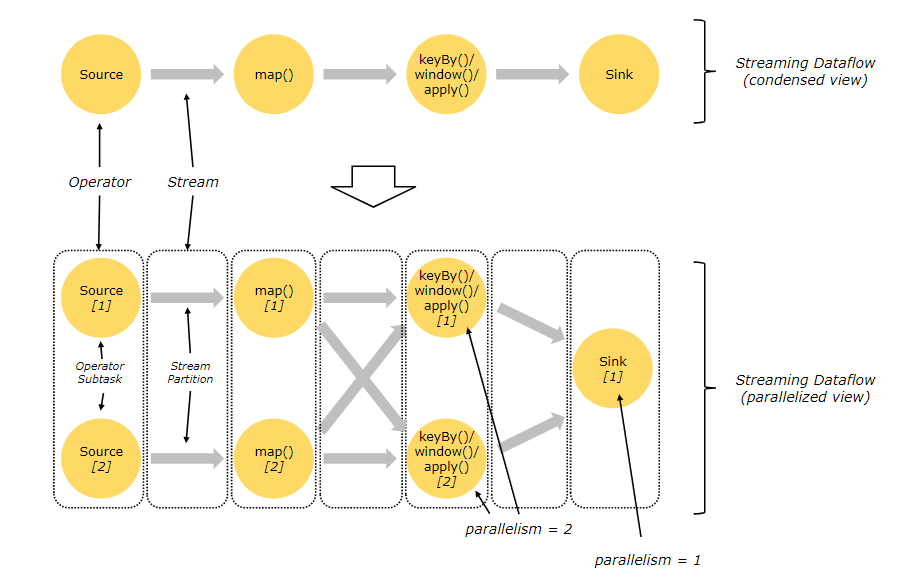
流在两个operators间有one-to-one (or forwarding) pattern, or in a redistributing pattern两种模式
- one-to-one: map
- redistributing: pattern keyby sink
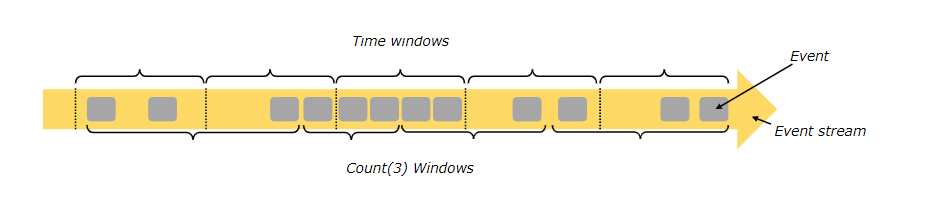
Windows
在无边界流上执行count操作是不可能的,但是count over the last 5 minutes”, or “sum of the last 100 elements”确是可以的。
windows可以是time driven (example: every 30 seconds) or data driven (example: every 100 elements)的
Time
当提到时间,我们指的可能是不同的时间种类
Event Time:事件被创建的时间
Ingestion time:在源头进入flink数据流的时间
Processing Time:事件被执行的时间

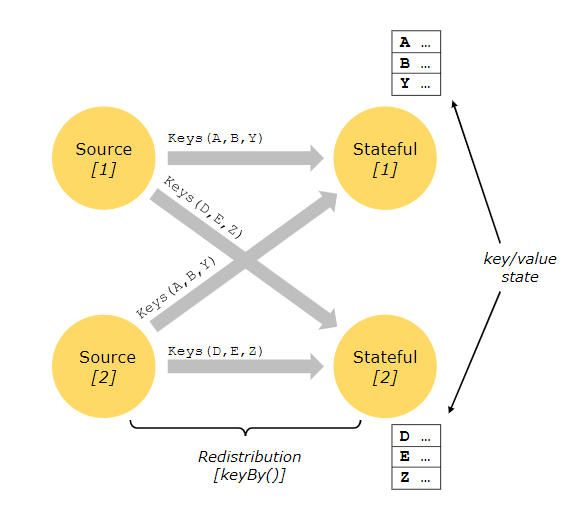
Stateful Operations
虽然数据流中的许多操作只是一次查看一个单独的事件(例如event parser),但有些操作会记住多个事件之间的信息(例如window operators)。这些操作称为有状态的。
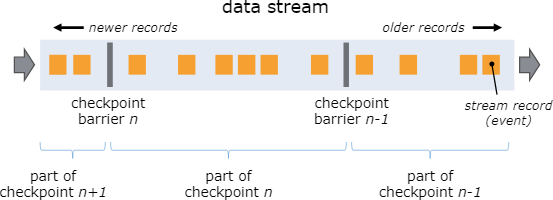
Checkpoints for Fault Tolerance
flink通过stream replay and checkpointing保证容错性