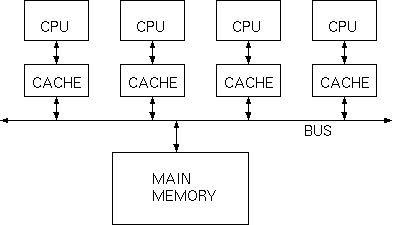
计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中会涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。
因此在CPU里面就有了高速缓存(Cache)的概念。当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。这一过程在单线程运行是没有问题的,但是在多线程中运行就会有问题了。在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存(对单核CPU来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。这时CPU缓存中的值可能和缓存中的值不一样,这就是著名的缓存一致性问题 。

1. 通过在总线加LOCK#锁的方式
在早期的CPU当中,是通过在总线上加LOCK#锁的形式来解决缓存不一致的问题。因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加LOCK#锁的话,也就是说阻塞了其他CPU对其他部件访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。在总线上发出了LCOK#锁的信号,那么只有等待这段代码完全执行完毕之后,其他CPU才能从其内存读取变量,然后进行相应的操作。这样就解决了缓存不一致的问题

2. 通过缓存一致性协议MESI
缓存一致性协议:
最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。