首先回顾一下MongoDB的基本操作:
数据库,集合,文档
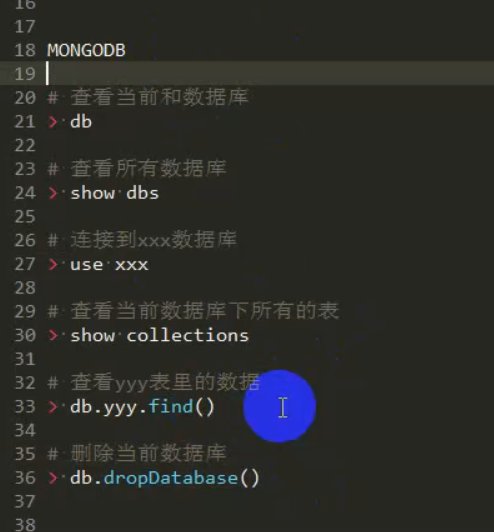
db,show dbs,use 数据库名,drop 数据库
db.集合名.insert({})
db.集合名.update({条件},{$set:{}},{multi:true})
db.集合名.remove({条件})
db集合名.find({条件},{投影}).limit().skip().sort().count().distinct()
数据库 增加 修改 删除 查询
mysql insert update delete select
redis set set del get
mongodb insert update remove find,aggregate
string
hash
list
set
zset
增加
mysql:insert into 表名(列) values(值)
mongo:db.集合名.insert({})
修改:
mysql:update 表名 set 列=值 where 条件
mongo:db.集合名.update({条件},{值$set},{是否修改多条})
删除:
mysql:delete from 表名 where ....
mongo:db.集合名.remove({条件},{是否删除多条})
查询:
db.stu.find({},{})
比较运算符,逻辑运算符,$where
limit(),skip(),sort(),count(),distinct()
首先使用xpath提取出要爬取的信息:我们这个项目需要爬取的信息有:标题,信息,评分,简介
第一页链接:https://movie.douban.com/top250
第二页链接:https://movie.douban.com/top250?start=25&filter=
第三页链接:https://movie.douban.com/top250?start=50&filter=
规律:https://movie.douban.com/top250?start=d+&filter=
标题://a/span[@class="title"][1]
信息://div[@class="bd"]/p[1]/text()
评分://div[@class="star"]/span[2]/text()
简介://span[@class="inq"]/text()
然后使用sscrapy startproject douban 创建项目
sscrapy genspider dopuban movie.douban.com
然后依次编写下面的文件:
 items.pydoubanmovie.pysettings.pypipelines.py
items.pydoubanmovie.pysettings.pypipelines.py