
面向对象编程
- 面向过程:根据业务逻辑从上到下写代码
- 面向对象:将数据与函数绑定到一起,进行封装,这样能够更快速的开发程序,减少了重复代码的重写过程
面向对象编程(Object Oriented Programming-OOP) 是一种解决软件复用的设计和编程方法。 这种方法把软件系统中相近相似的操作逻辑和操作 应用数据、状态,以类的型式描述出来,以对象实例的形式在软件系统中复用,以达到提高软件开发效率的作用。
面向对象技术简介
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量, 用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 实例变量:定义在方法中的变量,只作用于当前实例的类。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 方法:类中定义的函数。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
类和对象
面向对象编程的2个非常重要的概念:类和对象
对象是面向对象编程的核心,在使用对象的过程中,为了将具有共同特征和行为的一组对象抽象定义,提出了另外一个新的概念——类
类就相当于制造飞机时的图纸,用它来进行创建的飞机就相当于对象
1. 类
类是抽象的,在使用的时候通常会找到这个类的一个具体的存在,使用这个具体的存在。一个类可以找到多个对象
2. 对象
某一个具体事物的存在 ,在现实世界中可以是看得见摸得着的。
可以是直接使用的3. 类和对象之间的关系
类就是创建对象的模板
5. 类的构成
类(Class) 由3个部分构成
- 类的名称:类名
- 类的属性:一组数据
- 类的方法:允许对进行操作的方法 (行为)
<1> 举例:
1)人类设计,只关心3样东西:
- 事物名称(类名):人(Person)
- 属性:身高(height)、年龄(age)
- 方法(行为/功能):跑(run)、打架(fight)
6. 类的抽象
拥有相同(或者类似)属性和行为的对象都可以抽像出一个类
方法:一般名词都是类(名词提炼法)
定义类
定义一个类,格式如下:
class 类名:
方法列表
demo:定义一个Car类
# 定义类
class Car:
# 方法
def getCarInfo(self):
print('车轮子个数:%d, 颜色%s'%(self.wheelNum, self.color))
def move(self):
print("车正在移动...")
说明:
- 定义类时有2种:新式类和经典类,上面的Car为经典类,如果是Car(object)则为新式类
- 类名 的命名规则按照"大驼峰"
创建对象
python中,可以根据已经定义的类去创建出一个个对象
创建对象的格式为:
对象名 = 类名()
总结:
- BMW = Car(),这样就产生了一个Car的实例对象,此时也可以通过实例对象BMW来访问属性或者方法
- 第一次使用BMW.color = '黑色'表示给BMW这个对象添加属性,如果后面再次出现BMW.color = xxx表示对属性进行修改
- BMW是一个对象,它拥有属性(数据)和方法(函数)
- 当创建一个对象时,就是用一个模子,来制造一个实物
Python 面向对象
Python从设计之初就已经是一门面向对象的语言,正因为如此,在Python中创建一个类和对象是很容易的。本章节我们将详细介绍Python的面向对象编程。
如果你以前没有接触过面向对象的编程语言,那你可能需要先了解一些面向对象语言的一些基本特征,在头脑里头形成一个基本的面向对象的概念,这样有助于你更容易的学习Python的面向对象编程。
接下来我们先来简单的了解下面向对象的一些基本特征。
面向对象技术简介
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量, 用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 实例变量:定义在方法中的变量,只作用于当前实例的类。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 方法:类中定义的函数。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
创建类
使用 class 语句来创建一个新类,class 之后为类的名称并以冒号结尾:
class ClassName:
'类的帮助信息' #类文档字符串
class_suite #类体
类的帮助信息可以通过ClassName.__doc__查看。
class_suite 由类成员,方法,数据属性组成。
实例
以下是一个简单的 Python 类的例子:
实例
-
empCount 变量是一个类变量,它的值将在这个类的所有实例之间共享。你可以在内部类或外部类使用 Employee.empCount 访问。
-
第一种方法__init__()方法是一种特殊的方法,被称为类的构造函数或初始化方法,当创建了这个类的实例时就会调用该方法
-
self 代表类的实例,self 在定义类的方法时是必须有的,虽然在调用时不必传入相应的参数。
self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
以上实例执行结果为:
<__main__.Test instance at 0x10d066878>
__main__.Test
从执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。
self 不是 python 关键字,我们把他换成 runoob 也是可以正常执行的:
实例
以上实例执行结果为:
<__main__.Test instance at 0x10d066878>
__main__.Test
创建实例对象
实例化类其他编程语言中一般用关键字 new,但是在 Python 中并没有这个关键字,类的实例化类似函数调用方式。
以下使用类的名称 Employee 来实例化,并通过 __init__ 方法接收参数。
"创建 Employee 类的第一个对象"
emp1 = Employee("Zara", 2000)
"创建 Employee 类的第二个对象"
emp2 = Employee("Manni", 5000)
访问属性
您可以使用点号 . 来访问对象的属性。使用如下类的名称访问类变量:
emp1.displayEmployee()
emp2.displayEmployee()
print "Total Employee %d" % Employee.empCount
完整实例:
实例
执行以上代码输出结果如下:
Name : Zara ,Salary: 2000
Name : Manni ,Salary: 5000
Total Employee 2
你可以添加,删除,修改类的属性,如下所示:
emp1.age = 7 # 添加一个 'age' 属性
emp1.age = 8 # 修改 'age' 属性
del emp1.age # 删除 'age' 属性
你也可以使用以下函数的方式来访问属性:
- getattr(obj, name[, default]) : 访问对象的属性。
- hasattr(obj,name) : 检查是否存在一个属性。
- setattr(obj,name,value) : 设置一个属性。如果属性不存在,会创建一个新属性。
- delattr(obj, name) : 删除属性。
Python内置类属性
- __dict__ : 类的属性(包含一个字典,由类的数据属性组成)
- __doc__ :类的文档字符串
- __name__: 类名
- __module__: 类定义所在的模块(类的全名是'__main__.className',如果类位于一个导入模块mymod中,那么className.__module__ 等于 mymod)
- __bases__ : 类的所有父类构成元素(包含了一个由所有父类组成的元组)
Python内置类属性调用实例如下:
实例
执行以上代码输出结果如下:
Employee.__doc__: 所有员工的基类
Employee.__name__: Employee
Employee.__module__: __main__
Employee.__bases__: ()
Employee.__dict__: {'__module__': '__main__', 'displayCount': <function displayCount at 0x10a939c80>, 'empCount': 0, 'displayEmployee': <function displayEmployee at 0x10a93caa0>, '__doc__': 'xe6x89x80xe6x9cx89xe5x91x98xe5xb7xa5xe7x9ax84xe5x9fxbaxe7xb1xbb', '__init__': <function __init__ at 0x10a939578>}
python对象销毁(垃圾回收)
Python 使用了引用计数这一简单技术来跟踪和回收垃圾。
在 Python 内部记录着所有使用中的对象各有多少引用。一个内部跟踪变量,称为一个引用计数器。
当对象被创建时, 就创建了一个引用计数, 当这个对象不再需要时, 也就是说, 这个对象的引用计数变为0 时, 它被垃圾回收。但是回收不是"立即"的, 由解释器在适当的时机,将垃圾对象占用的内存空间回收。
a = 40 # 创建对象 <40>
b = a # 增加引用, <40> 的计数
c = [b] # 增加引用. <40> 的计数
del a # 减少引用 <40> 的计数
b = 100 # 减少引用 <40> 的计数
c[0] = -1 # 减少引用 <40> 的计数
垃圾回收机制不仅针对引用计数为0的对象,同样也可以处理循环引用的情况。循环引用指的是,两个对象相互引用,但是没有其他变量引用他们。这种情况下,仅使用引用计数是不够的。Python 的垃圾收集器实际上是一个引用计数器和一个循环垃圾收集器。作为引用计数的补充, 垃圾收集器也会留心被分配的总量很大(及未通过引用计数销毁的那些)的对象。 在这种情况下, 解释器会暂停下来, 试图清理所有未引用的循环。
实例
析构函数 __del__ ,__del__在对象销毁的时候被调用,当对象不再被使用时,__del__方法运行:
实例
以上实例运行结果如下:
3083401324 3083401324 3083401324
Point 销毁
注意:通常你需要在单独的文件中定义一个类,
面向对象三大特性
面向对象的三大特性是指:封装、继承和多态。
一、封装
封装,顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容。
所以,在使用面向对象的封装特性时,需要:
- 将内容封装到某处
- 从某处调用被封装的内容
第一步:将内容封装到某处

每个对象中都有 name 和 age 属性,在内存里类似于下图来保存。

第二步:从某处调用被封装的内容
调用被封装的内容时,有两种情况:
- 通过对象直接调用
- 通过self间接调用
1、通过对象直接调用被封装的内容
上图展示了对象 obj1 和 obj2 在内存中保存的方式,根据保存格式可以如此调用被封装的内容:对象.属性名
2、通过self间接调用被封装的内容
执行类中的方法时,需要通过self间接调用被封装的内容
class Foo:
def __init__(self, name, age): self.name = name self.age = age def detail(self): print self.name print self.age obj1 = Foo('wupeiqi', 18)obj1.detail() # Python默认会将obj1传给self参数,即:obj1.detail(obj1),所以,此时方法内部的 self = obj1,即:self.name 是 wupeiqi ;self.age 是 18 obj2 = Foo('alex', 73)obj2.detail() # Python默认会将obj2传给self参数,即:obj1.detail(obj2),所以,此时方法内部的 self = obj2,即:self.name 是 alex ; self.age 是 78二、继承
继承,面向对象中的继承和现实生活中的继承相同,即:子可以继承父的内容。
于面向对象的继承来说,其实就是将多个类共有的方法提取到父类中,子类仅需继承父类而不必一一实现每个方法。
注:除了子类和父类的称谓,你可能看到过 派生类 和 基类 ,他们与子类和父类只是叫法不同而已。

类的继承
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。
通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
继承语法
class 派生类名(基类名)
...
在python中继承中的一些特点:
- 1、如果在子类中需要父类的构造方法就需要显示的调用父类的构造方法,或者不重写父类的构造方法。详细说明可查看:python 子类继承父类构造函数说明。
- 2、在调用基类的方法时,需要加上基类的类名前缀,且需要带上 self 参数变量。区别在于类中调用普通函数时并不需要带上 self 参数
- 3、Python 总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。
如果在继承元组中列了一个以上的类,那么它就被称作"多重继承" 。
语法:
派生类的声明,与他们的父类类似,继承的基类列表跟在类名之后,如下所示:
class SubClassName (ParentClass1[, ParentClass2, ...]):
...
实例
以上代码执行结果如下:
调用子类构造方法
调用子类方法
调用父类方法
父类属性 : 200
你可以继承多个类
class A: # 定义类 A
.....
class B: # 定义类 B
.....
class C(A, B): # 继承类 A 和 B
.....
你可以使用issubclass()或者isinstance()方法来检测。
- issubclass() - 布尔函数判断一个类是另一个类的子类或者子孙类,语法:issubclass(sub,sup)
- isinstance(obj, Class) 布尔函数如果obj是Class类的实例对象或者是一个Class子类的实例对象则返回true。
方法重写
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法:
实例:
实例
执行以上代码输出结果如下:
调用子类方法
基础重载方法
下表列出了一些通用的功能,你可以在自己的类重写:
| 序号 | 方法, 描述 & 简单的调用 |
|---|---|
| 1 | __init__ ( self [,args...] ) 构造函数 简单的调用方法: obj = className(args) |
| 2 | __del__( self ) 析构方法, 删除一个对象 简单的调用方法 : del obj |
| 3 | __repr__( self ) 转化为供解释器读取的形式 简单的调用方法 : repr(obj) |
| 4 | __str__( self ) 用于将值转化为适于人阅读的形式 简单的调用方法 : str(obj) |
| 5 | __cmp__ ( self, x ) 对象比较 简单的调用方法 : cmp(obj, x) |
单继承
- 子类在继承的时候,在定义类时,小括号()中为父类的名字
- 父类的属性、方法,会被继承给子类
-
注意点
-
- 私有的属性,不能通过对象直接访问,但是可以通过方法访问
- 私有的方法,不能通过对象直接访问
- 私有的属性、方法,不会被子类继承,也不能被访问
- 一般情况下,私有的属性、方法都是不对外公布的,往往用来做内部的事情,起到安全的作用
多继承
所谓多继承,即子类有多个父类,并且具有它们的特征
说明
- python中是可以多继承的
- 父类中的方法、属性,子类会继承
Python的类如果继承了多个类,那么其寻找方法的方式有两种,分别是:深度优先和广度优先

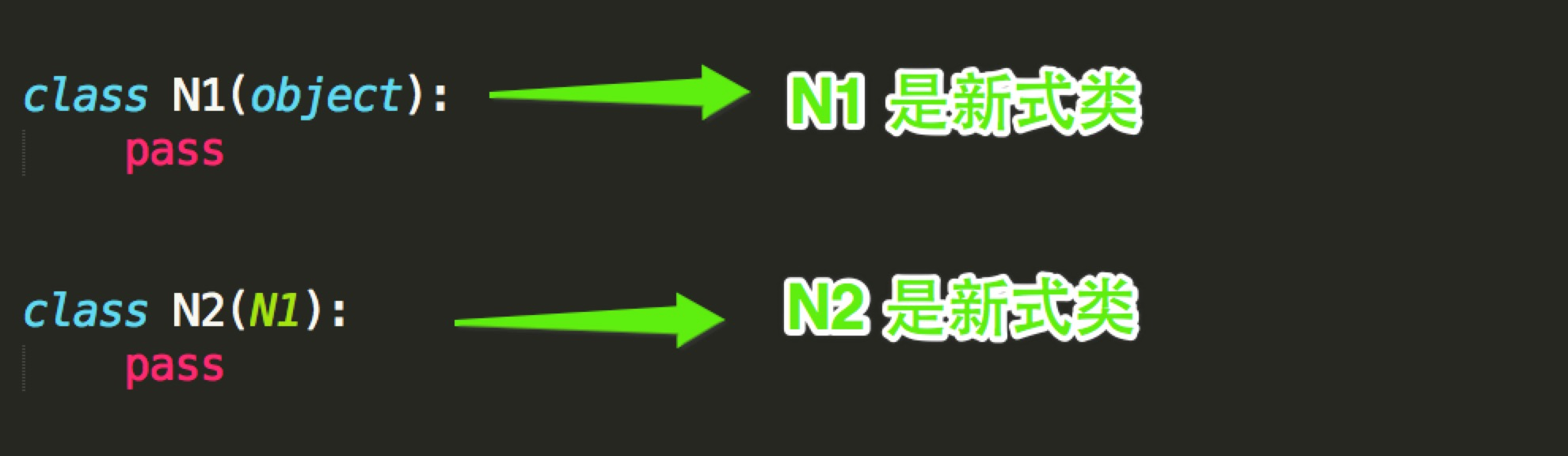
如果 当前类或者父类继承了object类,那么该类便是新式类,否则便是经典类。

注意点
- 想一想:
如果在上面的多继承例子中,如果父类A和父类B中,有一个同名的方法,那么通过子类去调用的时候,调用哪个?
#coding=utf-8
class base(object):
def test(self):
print('----base test----')
class A(base):
def test(self):
print('----A test----')
# 定义一个父类
class B(base):
def test(self):
print('----B test----')
# 定义一个子类,继承自A、B
class C(A,B):
pass
obj_C = C()
obj_C.test()
print(C.__mro__) #可以查看C类的对象搜索方法时的先后顺序
重写父类方法与调用父类方法
1. 重写父类方法
所谓重写,就是子类中,有一个和父类相同名字的方法,在子类中的方法会覆盖掉父类中同名的方法
2. 调用父类的方法
#coding=utf-8
class Cat(object):
def __init__(self,name):
self.name = name
self.color = 'yellow'
class Bosi(Cat):
def __init__(self,name):
# 调用父类的__init__方法1(python2)
#Cat.__init__(self,name)
# 调用父类的__init__方法2
#super(Bosi,self).__init__(name)
# 调用父类的__init__方法3
super().__init__(name)
def getName(self):
return self.name
bosi = Bosi('xiaohua')
print(bosi.name)
print(bosi.color)
三:多态
多态的概念是应用于Java和C#这一类强类型语言中,而Python崇尚“鸭子类型”。
所谓多态:定义时的类型和运行时的类型不一样,此时就成为多态
(1)什么是多态性(注意:多态与多态性是两种概念)
多态性是指具有不同功能的函数可以使用相同的函数名,这样就可以用一个函数名调用不同内容的函数。在面向对象方法中一般是这样表述多态性:向不同的对象发送同一条消息,不同的对象在接收时会产生不同的行为(即方法)。也就是说,每个对象可以用自己的方式去响应共同的消息。所谓消息,就是调用函数,不同的行为就是指不同的实现,即执行不同的函数。
为什么要用多态性(多态性的好处)
(1)增加了程序的灵活性
以不变应万变,不论对象千变万化,使用者都是同一种形式去调用,如func(animal)
(2)增加了程序额可扩展性
通过继承animal类创建了一个新的类,使用者无需更改自己的代码,还是用func(animal)去调用
注:
多态:同一种事物的多种形态,动物分为人类,猪类(在定义角度) 多态性:一种调用方式,不同的执行效果(多态性)
类属性、实例属性
类属性和实例属性
在前面的例子中我们接触到的就是实例属性(对象属性),顾名思义,类属性就是类对象所拥有的属性,它被所有类对象的实例对象所共有,在内存中只存在一个副本,这个和C++中类的静态成员变量有点类似。对于公有的类属性,在类外可以通过类对象和实例对象访问
类属性
class People(object):
name = 'Tom' #公有的类属性
__age = 12 #私有的类属性
p = People()
print(p.name) #正确
print(People.name) #正确
print(p.__age) #错误,不能在类外通过实例对象访问私有的类属性
print(People.__age) #错误,不能在类外通过类对象访问私有的类属性
通过实例(对象)去修改类属性
class People(object):
country = 'china' #类属性
print(People.country)
p = People()
print(p.country)
p.country = 'japan'
print(p.country) #实例属性会屏蔽掉同名的类属性
print(People.country)
del p.country #删除实例属性
print(p.country)
总结
- 如果需要在类外修改
类属性,必须通过类对象去引用然后进行修改。如果通过实例对象去引用,会产生一个同名的实例属性,这种方式修改的是实例属性,不会影响到类属性,并且之后如果通过实例对象去引用该名称的属性,实例属性会强制屏蔽掉类属性,即引用的是实例属性,除非删除了该实例属性。
以上就是本节对于面向对象初级知识的介绍,总结如下:
- 面向对象是一种编程方式,此编程方式的实现是基于对 类 和 对象 的使用
- 类 是一个模板,模板中包装了多个“函数”供使用
- 对象,根据模板创建的实例(即:对象),实例用于调用被包装在类中的函数
- 面向对象三大特性:封装、继承和多态
类的成员
类的成员可以分为三大类:字段、方法和属性

注:所有成员中,只有普通字段的内容保存对象中,即:根据此类创建了多少对象,在内存中就有多少个普通字段。而其他的成员,则都是保存在类中,即:无论对象的多少,在内存中只创建一份。
一、字段
字段包括:普通字段和静态字段,他们在定义和使用中有所区别,而最本质的区别是内存中保存的位置不同,
- 普通字段属于对象
- 静态字段属于类

由上图可是:
- 静态字段在内存中只保存一份
- 普通字段在每个对象中都要保存一份
应用场景: 通过类创建对象时,如果每个对象都具有相同的字段,那么就使用静态字段
二、方法
方法包括:普通方法、静态方法和类方法,三种方法在内存中都归属于类,区别在于调用方式不同。
- 普通方法:由对象调用;至少一个self参数;执行普通方法时,自动将调用该方法的对象赋值给self;
- 类方法:由类调用; 至少一个cls参数;执行类方法时,自动将调用该方法的类复制给cls;
- 静态方法:由类调用;无默认参数;
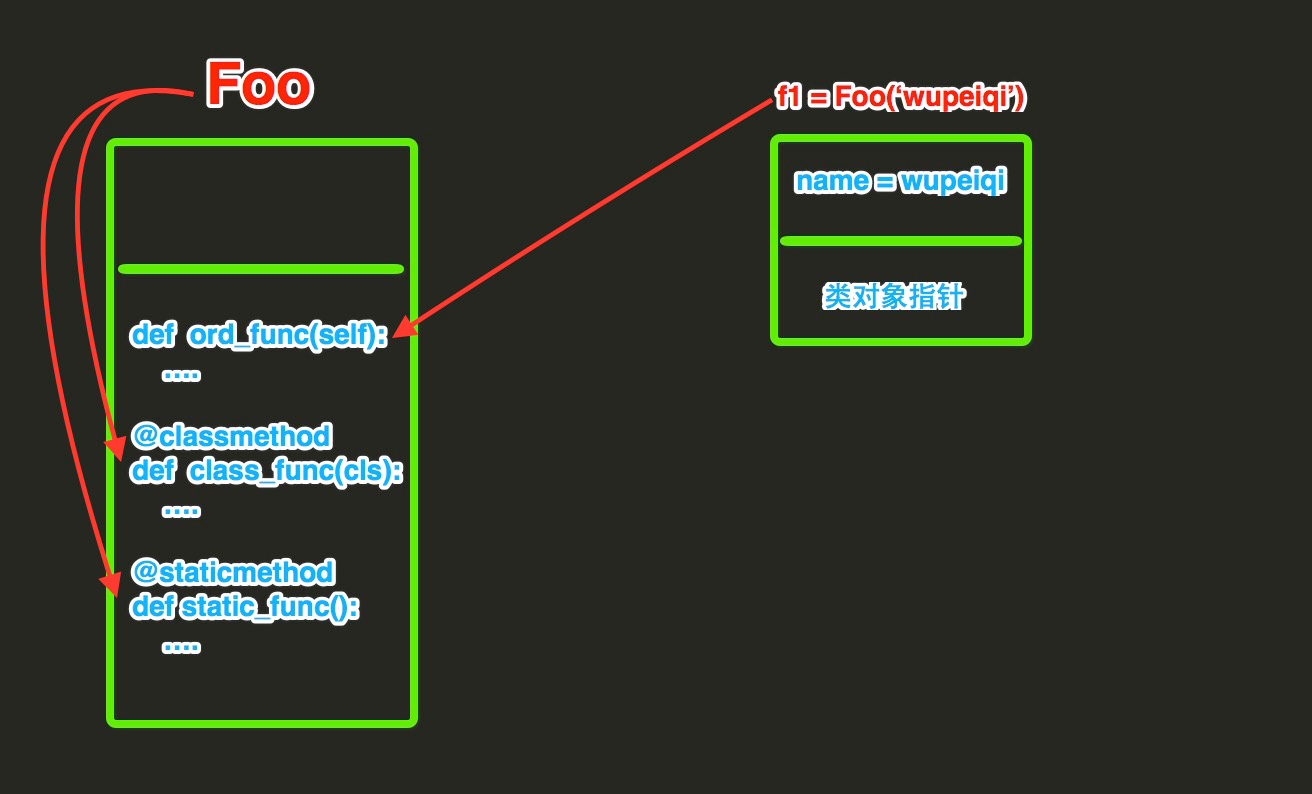
相同点:对于所有的方法而言,均属于类(非对象)中,所以,在内存中也只保存一份。
不同点:方法调用者不同、调用方法时自动传入的参数不同。
三、属性
如果你已经了解Python类中的方法,那么属性就非常简单了,因为Python中的属性其实是普通方法的变种。
对于属性,有以下三个知识点:
- 属性的基本使用
- 属性的两种定义方式

由属性的定义和调用要注意一下几点:
- 定义时,在普通方法的基础上添加 @property 装饰器;
- 定义时,属性仅有一个self参数
- 调用时,无需括号
方法:foo_obj.func()
属性:foo_obj.prop
注意:属性存在意义是:访问属性时可以制造出和访问字段完全相同的假象
属性由方法变种而来,如果Python中没有属性,方法完全可以代替其功能。
实例:对于主机列表页面,每次请求不可能把数据库中的所有内容都显示到页面上,而是通过分页的功能局部显示,所以在向数据库中请求数据时就要显示的指定获取从第m条到第n条的所有数据(即:limit m,n),这个分页的功能包括:
- 根据用户请求的当前页和总数据条数计算出 m 和 n
- 根据m 和 n 去数据库中请求数据
从上述可见,Python的属性的功能是:属性内部进行一系列的逻辑计算,最终将计算结果返回。
2、属性的两种定义方式
属性的定义有两种方式:
- 装饰器 即:在方法上应用装饰器
- 静态字段 即:在类中定义值为property对象的静态字段
装饰器方式:在类的普通方法上应用@property装饰器
装饰器
假设我们要增强 now() 函数的功能,比如,在函数调用前后自动打印日 志,但又不希望修改 now() 函数的定义,这种在代码运行期间动态增加功能的方 式,称之为“装饰器”(Decorator)。

python当中如果出现两个重名的函数:之后定义的会取代之前定义的函数,之前定义的函数就没意义了,所以引出了装饰器.
4. 装饰器(decorator)功能
1. 引⼊⽇志 2. 函数执⾏时间统计 3. 执⾏函数前预备处理 4. 执⾏函数后清理功能 5. 权限校验等场景 6. 缓存
python-----装饰器原理剖析
只要函数应用装饰器,那么函数就被重新定义为:装饰器的内存函数
@:装饰器的特有符号 @timer ===》test = timer(test)
eg:
红色框和绿色框是等价关系

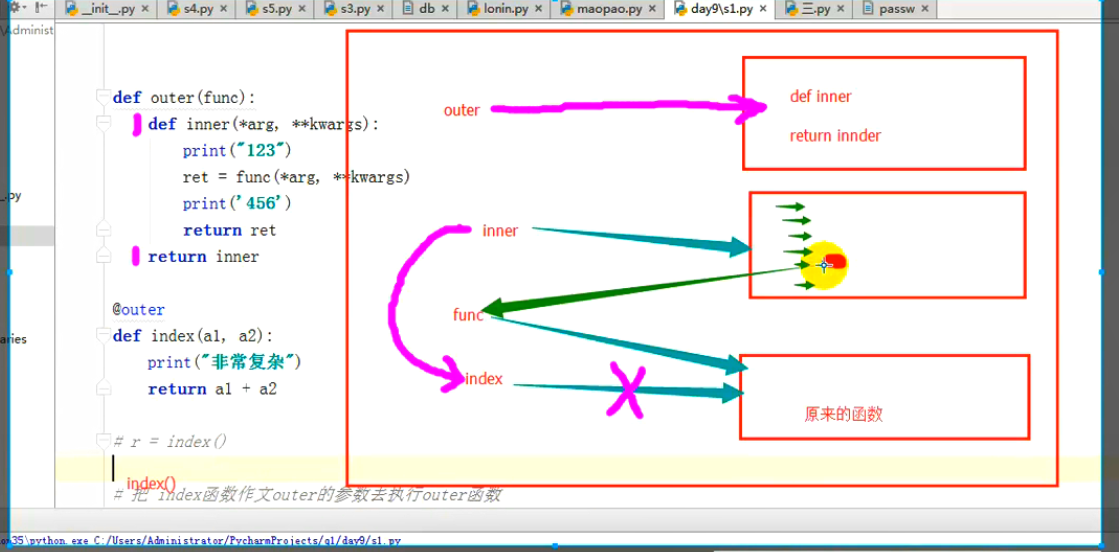
def outer(func): #1
def inner(*arg,**kwargs): #2 #*arg,**kwargs其他人传入元组,字典或者多个参数都可以接受
print("123") #3
ret = func(*arg,**kwargs) #4
print("356") #5
return ret #6
return inner #7
#func = 原来的函数,
@outer # @outer===》等效于index = outer(index) #8
def index(a1,a2): #9
print("好难啊") #10
return a1 +a2 #11
#解释器从上到下执行,首先创建inner,里面包括def inner,return inner但是并未执行
#解释器从上到下执行,创建index,里面包括def index,但是并未执行
#1,执行@之后的函数此处为outer函数,并且将其下面的函数名当做参数传递进去,此处为index,把index当做参数传入#1 然后执行,此时传入的时候同时创建func,func=原来的函数(index)
#2,将outer的返回值重新赋值给index
#3,新的函数等于inner
装饰器先 装饰里面的 ,在装饰外面的


生成器
1. 什么是⽣成器 : 在Python中,这种⼀边循环⼀边计算 的机制,称为⽣成器:generator。
2. 创建⽣成器⽅法1
要创建⼀个⽣成器,有很多种⽅法。第⼀种⽅法很简单,只要把⼀个列表⽣ 成式的 [ ] 改成 ( ),,可以通过 next() 函数获得⽣成器的下⼀ 个返回值:
3. 创建⽣成器⽅法2
把 print b 改为 yield b 就可以了:
这就是定义generator的另一种方法。如果一个函数定义中包含 yield 关键字,那 么这个函数就不再是一个普通函数,而是一个generator:
最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到 return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调 用 next() 的时候执行,遇到 yield 语句返回,再次执行时从上次返回 的 yield 语句处继续执行。
小结
generator是非常强大的工具,在Python中,可以简单地把列表生成式改成 generator,也可以通过函数实现复杂逻辑的generator。
要理解generator的工作原理,它是在 for 循环的过程中不断计算出下一个元素, 并在适当的条件结束 for 循环。对于函数改成的generator来说,遇到return语句 或者执行到函数体最后一行语句,就是结束generator的指令, for 循环随之结 束。
协程
高级模块
元类
1. 类也是对象
在⼤多数编程语⾔中,类就是⼀组⽤来描述如何⽣成⼀个对象的代码段。在 Python中这⼀点仍然成⽴:
>>> class ObjectCreator(object):
… pass
…
>>> my_object = ObjectCreator()
>>> print my_object
<__main__.ObjectCreator object at 0x8974f2c>
但是,Python中的类还远不⽌如此。类同样也是⼀种对象。是的,没错,就是对象。只要你使⽤关键字class,Python解释器在执⾏的时候就会创建⼀个对象。下⾯的代码段:
>>> class ObjectCreator(object):
… pass
…
将在内存中创建⼀个对象,名字就是ObjectCreator。这个对象(类对象 ObjectCreator)拥有创建对象(实例对象)的能⼒。但是,它的本质仍然是
⼀个对象,于是乎你可以对它做如下的操作:
- 你可以将它赋值给⼀个变量
- 你可以拷⻉它
- 你可以为它增加属性
- 你可以将它作为函数参数进⾏传递
下⾯是示例:
|
>>> print ObjectCreator # 你可以打印⼀个类,因为它其实也是⼀个对象 <class '__main__.ObjectCreator'> >>> def echo(o): … print o … >>> echo(ObjectCreator) # 你可以将类做为参数传给函数 <class '__main__.ObjectCreator'> >>> print hasattr(ObjectCreator, 'new_attribute') Fasle >>> ObjectCreator.new_attribute = 'foo' # 你可以为类增加属性 >>> print hasattr(ObjectCreator, 'new_attribute') True >>> print ObjectCreator.new_attribute foo >>> ObjectCreatorMirror = ObjectCreator # 你可以将类赋值给⼀个变量 >>> print ObjectCreatorMirror() <__main__.ObjectCreator object at 0x8997b4c> |
2. 动态地创建类
因为类也是对象,你可以在运⾏时动态的创建它们,就像其他任何对象⼀样。⾸先,你可以在函数中创建类,使⽤class关键字即可。
>>> def choose_class(name):
… if name == 'foo':
… class Foo(object):
… pass
… return Foo # 返回的是类,不是类的实例
… else:
… class Bar(object):
… pass
… return Bar
|
… >>> MyClass = choose_class('foo') >>> print MyClass # 函数返回的是类,不是类的实例 <class '__main__'.Foo> >>> print MyClass() # 你可以通过这个类创建类实例,也就是对象 <__main__.Foo object at 0x89c6d4c> |
但这还不够动态,因为你仍然需要⾃⼰编写整个类的代码。由于类也是对
象,所以它们必须是通过什么东⻄来⽣成的才对。当你使⽤class关键字时,
Python解释器⾃动创建这个对象。但就和Python中的⼤多数事情⼀样,
Python仍然提供给你⼿动处理的⽅法。
还记得内建函数type吗?这个古⽼但强⼤的函数能够让你知道⼀个对象的类型是什么,就像这样:
>>> print type(1) #数值的类型
<type 'int'>
>>> print type("1") #字符串的类型
<type 'str'>
>>> print type(ObjectCreator()) #实例对象的类型
<class '__main__.ObjectCreator'>
>>> print type(ObjectCreator) #类的类型
<type 'type'>
仔细观察上⾯的运⾏结果,发现使⽤type对ObjectCreator查看类型是,答案为type, 是不是有些惊讶。。。看下⾯
3. 使⽤type创建类
type还有⼀种完全不同的功能,动态的创建类。
type可以接受⼀个类的描述作为参数,然后返回⼀个类。(要知道,根据传⼊参数的不同,同⼀个函数拥有两种完全不同的⽤法是⼀件很傻的事情,但这在Python中是为了保持向后兼容性)
type可以像这样⼯作:
type(类名, 由⽗类名称组成的元组(针对继承的情况,可以为空),包含属性的字典(名称和值))
⽐如下⾯的代码:
In [2]: class Test: #定义了⼀个Test类
...: pass
...:
In [3]: Test() #创建了⼀个Test类的实例对象
Out[3]: <__main__.Test at 0x10d3f8438>
可以⼿动像这样创建:
Test2 = type("Test2",(),{}) #定了⼀个Test2类
In [5]: Test2() #创建了⼀个Test2类的实例对象
Out[5]: <__main__.Test2 at 0x10d406b38>
我们使⽤"Test2"作为类名,并且也可以把它当做⼀个变量来作为类的引⽤。类和变量是不同的,这⾥没有任何理由把事情弄的复杂。即type函数中第1个实参,也可以叫做其他的名字,这个名字表示类的名字
In [23]: MyDogClass = type('MyDog', (), {})
In [24]: print MyDogClass
<class '__main__.MyDog'>
使⽤help来测试这2个类
In [10]: help(Test) #⽤help查看Test类
Help on class Test in module __main__:
class Test(builtins.object)
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
In [8]: help(Test2) #⽤help查看Test2类 Help on class Test2 in module __main__: class Test2(builtins.object) | Data descriptors defined here: | | __dict__ | dictionary for instance variables (if defined) | | __weakref__ | list of weak references to the object (if defined) |
4. 使⽤type创建带有属性的类
type 接受⼀个字典来为类定义属性,因此
>>> Foo = type('Foo', (), {'bar':True})
可以翻译为:
>>> class Foo(object):
… bar = True
并且可以将Foo当成⼀个普通的类⼀样使⽤:
>>> print Foo
<class '__main__.Foo'>
>>> print Foo.bar
True
>>> f = Foo()
>>> print f
<__main__.Foo object at 0x8a9b84c>
>>> print f.bar
True
当然,你可以向这个类继承,所以,如下的代码:
>>> class FooChild(Foo):
… pass
就可以写成:
>>> FooChild = type('FooChild', (Foo,),{})
>>> print FooChild
<class '__main__.FooChild'>
>>> print FooChild.bar # bar属性是由Foo继承⽽来
True
注意:
type的第2个参数,元组中是⽗类的名字,⽽不是字符串添加的属性是类属性,并不是实例属性 5. 使⽤type创建带有⽅法的类
最终你会希望为你的类增加⽅法。只需要定义⼀个有着恰当签名的函数并将其作为属性赋值就可以了。
添加实例⽅法
|
In [46]: def echo_bar(self): #定义了⼀个普通的函数 ...: print(self.bar) ...: In [47]: FooChild = type('FooChild', (Foo,), {'echo_bar': echo_b In [48]: hasattr(Foo, 'echo_bar') #判断Foo类中,是否有echo_bar这个属 Out[48]: False In [49]: In [49]: hasattr(FooChild, 'echo_bar') #判断FooChild类中,是否有 Out[49]: True In [50]: my_foo = FooChild() In [51]: my_foo.echo_bar() True |
ech
添加静态⽅法
|
In [36]: @staticmethod ...: def testStatic(): ...: print("static method ....") ...: In [37]: Foochild = type('Foochild', (Foo,), {"echo_bar":echo_ba ...: testStatic}) In [38]: fooclid = Foochild() In [39]: fooclid.testStatic Out[39]: <function __main__.testStatic> In [40]: fooclid.testStatic() static method .... |
添加类⽅法
|
In [42]: @classmethod ...: def testClass(cls): ...: print(cls.bar) ...: In [43]: In [43]: Foochild = type('Foochild', (Foo,), {"echo_bar":echo_ba ...: testStatic, "testClass":testClass}) In [44]: In [44]: fooclid = Foochild() In [45]: fooclid.testClass() True |
你可以看到,在Python中,类也是对象,你可以动态的创建类。这就是当你使⽤关键字class时Python在幕后做的事情,⽽这就是通过元类来实现的。
6. 到底什么是元类(终于到主题了)
元类就是⽤来创建类的“东⻄”。你创建类就是为了创建类的实例对象,不是吗?但是我们已经学习到了Python中的类也是对象。
元类就是⽤来创建这些类(对象)的,元类就是类的类,你可以这样理解为:
MyClass = MetaClass() #使⽤元类创建出⼀个对象,这个对象称为“类”
MyObject = MyClass() #使⽤“类”来创建出实例对象
你已经看到了type可以让你像这样做:
MyClass = type('MyClass', (), {})
这是因为函数type实际上是⼀个元类。type就是Python在背后⽤来创建所有类的元类。现在你想知道那为什么type会全部采⽤⼩写形式⽽不是Type呢?好吧,我猜这是为了和str保持⼀致性,str是⽤来创建字符串对象的类,⽽int 是⽤来创建整数对象的类。type就是创建类对象的类。你可以通过检查 __class__属性来看到这⼀点。Python中所有的东⻄,注意,我是指所有的东
⻄——都是对象。这包括整数、字符串、函数以及类。它们全部都是对象,⽽且它们都是从⼀个类创建⽽来,这个类就是type。
>>> age = 35
>>> age.__class__
<type 'int'>
>>> name = 'bob'
>>> name.__class__
<type 'str'>
>>> def foo(): pass
>>>foo.__class__
<type 'function'>
>>> class Bar(object): pass
>>> b = Bar()
>>> b.__class__
<class '__main__.Bar'>
现在,对于任何⼀个__class__的__class__属性⼜是什么呢?
>>> a.__class__.__class__
<type 'type'>
>>> age.__class__.__class__
<type 'type'>
>>> foo.__class__.__class__
<type 'type'>
>>> b.__class__.__class__
<type 'type'>
因此,元类就是创建类这种对象的东⻄。type就是Python的内建元类,当然了,你也可以创建⾃⼰的元类。 7. __metaclass__属性
你可以在定义⼀个类的时候为其添加__metaclass__属性。
class Foo(object):
__metaclass__ = something… ...省略...
如果你这么做了,Python就会⽤元类来创建类Foo。⼩⼼点,这⾥⾯有些技
巧。你⾸先写下class Foo(object),但是类Foo还没有在内存中创建。Python 会在类的定义中寻找__metaclass__属性,如果找到了,Python就会⽤它来创建类Foo,如果没有找到,就会⽤内建的type来创建这个类。把下⾯这段话反复读⼏次。当你写如下代码时 :
class Foo(Bar): pass
Python做了如下的操作:
- Foo中有__metaclass__这个属性吗?如果是,Python会通过
__metaclass__创建⼀个名字为Foo的类(对象)
- 如果Python没有找到__metaclass__,它会继续在Bar(⽗类)中寻找 __metaclass__属性,并尝试做和前⾯同样的操作。
- 如果Python在任何⽗类中都找不到__metaclass__,它就会在模块层次中去寻找__metaclass__,并尝试做同样的操作。
- 如果还是找不到__metaclass__,Python就会⽤内置的type来创建这个类对象。
现在的问题就是,你可以在__metaclass__中放置些什么代码呢?答案就
是:可以创建⼀个类的东⻄。那么什么可以⽤来创建⼀个类呢?type,或者任何使⽤到type或者⼦类化type的东东都可以。
8. ⾃定义元类
元类的主要⽬的就是为了当创建类时能够⾃动地改变类。通常,你会为API做这样的事情,你希望可以创建符合当前上下⽂的类。
假想⼀个很傻的例⼦,你决定在你的模块⾥所有的类的属性都应该是⼤写形
式。有好⼏种⽅法可以办到,但其中⼀种就是通过在模块级别设定
__metaclass__。采⽤这种⽅法,这个模块中的所有类都会通过这个元类来创建,我们只需要告诉元类把所有的属性都改成⼤写形式就万事⼤吉了。
幸运的是,__metaclass__实际上可以被任意调⽤,它并不需要是⼀个正式的类。所以,我们这⾥就先以⼀个简单的函数作为例⼦开始。
python2中
|
#-*- coding:utf-8 -*- def upper_attr(future_class_name, future_class_parents, future_c #遍历属性字典,把不是__开头的属性名字变为⼤写 newAttr = {} for name,value in future_class_attr.items(): if not name.startswith("__"): newAttr[name.upper()] = value #调⽤type来创建⼀个类 return type(future_class_name, future_class_parents, newAttr class Foo(object): __metaclass__ = upper_attr #设置Foo类的元类为upper_attr bar = 'bip' |
python3中
|
#-*- coding:utf-8 -*- def upper_attr(future_class_name, future_class_parents, future_c #遍历属性字典,把不是__开头的属性名字变为⼤写 newAttr = {} for name,value in future_class_attr.items(): if not name.startswith("__"): newAttr[name.upper()] = value #调⽤type来创建⼀个类 return type(future_class_name, future_class_parents, newAttr class Foo(object, metaclass=upper_attr): bar = 'bip' print(hasattr(Foo, 'bar')) print(hasattr(Foo, 'BAR')) f = Foo() print(f.BAR) |
现在让我们再做⼀次,这⼀次⽤⼀个真正的class来当做元类。
#coding=utf-8
class UpperAttrMetaClass(type):
|
# __new__ 是在__init__之前被调⽤的特殊⽅法 # __new__是⽤来创建对象并返回之的⽅法 # ⽽__init__只是⽤来将传⼊的参数初始化给对象 # 你很少⽤到__new__,除⾮你希望能够控制对象的创建 # 这⾥,创建的对象是类,我们希望能够⾃定义它,所以我们这⾥改写__new__ # 如果你希望的话,你也可以在__init__中做些事情 # 还有⼀些⾼级的⽤法会涉及到改写__call__特殊⽅法,但是我们这⾥不⽤ def __new__(cls, future_class_name, future_class_parents, fu #遍历属性字典,把不是__开头的属性名字变为⼤写 newAttr = {} for name,value in future_class_attr.items(): if not name.startswith("__"): newAttr[name.upper()] = value # ⽅法1:通过'type'来做类对象的创建 # return type(future_class_name, future_class_parents, n # ⽅法2:复⽤type.__new__⽅法 # 这就是基本的OOP编程,没什么魔法 # return type.__new__(cls, future_class_name, future_cla # ⽅法3:使⽤super⽅法 return super(UpperAttrMetaClass, cls).__new__(cls, futur #python2的⽤法 class Foo(object): __metaclass__ = UpperAttrMetaClass bar = 'bip' # python3的⽤法 # class Foo(object, metaclass = UpperAttrMetaClass): # bar = 'bip' print(hasattr(Foo, 'bar')) # 输出: False print(hasattr(Foo, 'BAR')) # 输出:True |
就是这样,除此之外,关于元类真的没有别的可说的了。但就元类本身⽽
⾔,它们其实是很简单的:
- 拦截类的创建
- 修改类
- 返回修改之后的类
究竟为什么要使⽤元类?
现在回到我们的⼤主题上来,究竟是为什么你会去使⽤这样⼀种容易出错且晦涩的特性?好吧,⼀般来说,你根本就⽤不上它:
“元类就是深度的魔法,99%的⽤户应该根本不必为此操⼼。如果你想搞清楚究竟是否需要⽤到元类,那么你就不需要它。那些实际⽤到元类的⼈都⾮常清楚地知道他们需要做什么,⽽且根本不需要解释为什么要⽤元类。” ——
Python界的领袖 Tim Peters
python是动态语⾔
1. 动态语⾔的定义
动态编程语⾔ 是 ⾼级程序设计语⾔ 的⼀个类别,在计算机科学领域已被⼴泛应⽤。它是⼀类 在 运⾏时可以改变其结构 的语⾔ :例如新的函数、对象、甚⾄代码可以被引进,已有的函数可以被删除或是其他结构上的变化。动态语⾔⽬前⾮常具有活⼒。例如JavaScript便是⼀个动态语⾔,除此之外如
PHP 、 Ruby 、 Python 等也都属于动态语⾔,⽽ C 、 C++ 等语⾔则不属于动态语⾔。----来⾃ 维基百科
2. 运⾏的过程中给对象绑定(添加)属性
|
>>> class Person(object): def __init__(self, name = None, age = None): self.name = name self.age = age >>> P = Person("⼩明", "24") >>> |
在这⾥,我们定义了1个类Person,在这个类⾥,定义了两个初始属性name 和age,但是⼈还有性别啊!如果这个类不是你写的是不是你会尝试访问性别这个属性呢?
>>> P.sex = "male"
>>> P.sex
'male'
>>>
这时候就发现问题了,我们定义的类⾥⾯没有sex这个属性啊!怎么回事呢?这就是动态语⾔的魅⼒和坑! 这⾥ 实际上就是 动态给实例绑定属性!
3. 运⾏的过程中给类绑定(添加)属性
>>> P1 = Person("⼩丽", "25")
>>> P1.sex
Traceback (most recent call last):
File "<pyshell#21>", line 1, in <module>
P1.sex
AttributeError: Person instance has no attribute 'sex'
>>>
我们尝试打印P1.sex,发现报错,P1没有sex这个属性!---- 给P这个实例绑定属性对P1这个实例不起作⽤! 那我们要给所有的Person的实例加上 sex属性怎么办呢? 答案就是直接给Person绑定属性!
|
>>>> Person.sex = None #给类Person添加⼀个属性 >>> P1 = Person("⼩丽", "25") >>> print(P1.sex) #如果P1这个实例对象中没有sex属性的话,那么就会访问它的 None #可以看到没有出现异常 >>> |
4. 运⾏的过程中给类绑定(添加)⽅法
我们直接给Person绑定sex这个属性,重新实例化P1后,P1就有sex这个属性了! 那么function呢?怎么绑定?
|
>>> class Person(object): def __init__(self, name = None, age = None): self.name = name self.age = age |
|
def eat(self): print("eat food") >>> def run(self, speed): print("%s在移动, 速度是 %d km/h"%(self.name, speed)) >>> P = Person("⽼王", 24) >>> P.eat() eat food >>> >>> P.run() Traceback (most recent call last): File "<pyshell#5>", line 1, in <module> P.run() AttributeError: Person instance has no attribute 'run' >>> >>> >>> import types >>> P.run = types.MethodType(run, P) >>> P.run(180) ⽼王在移动,速度是 180 km/h |
既然给类添加⽅法,是使⽤ 类名.⽅法名 = xxxx ,那么给对象添加⼀个⽅法也是类似的 对象.⽅法名 = xxxx
完整的代码如下:
import types
#定义了⼀个类
class Person(object):
num = 0 def __init__(self, name = None, age = None):
|
self.name = name self.age = age def eat(self): print("eat food") #定义⼀个实例⽅法 def run(self, speed): print("%s在移动, 速度是 %d km/h"%(self.name, speed)) #定义⼀个类⽅法 @classmethod def testClass(cls): cls.num = 100 #定义⼀个静态⽅法 @staticmethod def testStatic(): print("---static method----") #创建⼀个实例对象 P = Person("⽼王", 24) #调⽤在class中的⽅法 P.eat() #给这个对象添加实例⽅法 P.run = types.MethodType(run, P) #调⽤实例⽅法 P.run(180) #给Person类绑定类⽅法 Person.testClass = testClass #调⽤类⽅法 print(Person.num) Person.testClass() print(Person.num) #给Person类绑定静态⽅法 Person.testStatic = testStatic |
#调⽤静态⽅法
Person.testStatic()
5. 运⾏的过程中删除属性、⽅法
删除的⽅法:
- del 对象.属性名
- delattr(对象, "属性名")
通过以上例⼦可以得出⼀个结论:相对于动态语⾔,静态语⾔具有严谨性!所以,玩动态语⾔的时候,⼩⼼动态的坑!
那么怎么避免这种情况呢? 请使⽤__slots__,
__slots__
现在我们终于明⽩了,动态语⾔与静态语⾔的不同动态语⾔:可以在运⾏的过程中,修改代码静态语⾔:编译时已经确定好代码,运⾏过程中不能修改如果我们想要限制实例的属性怎么办?⽐如,只允许对Person实例添加 name和age属性。
为了达到限制的⽬的,Python允许在定义class的时候,定义⼀个特殊的 __slots__变量,来限制该class实例能添加的属性:
>>> class Person(object):
__slots__ = ("name", "age")
>>> P = Person()
>>> P.name = "⽼王"
>>> P.age = 20
>>> P.score = 100
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
AttributeError: Person instance has no attribute 'score'
>>>
注意:
使⽤__slots__要注意,__slots__定义的属性仅对当前类实例起作⽤,对继承的⼦类是不起作⽤的
In [67]: class Test(Person):
...: pass ...:
__slots__
In [68]: t = Test()
In [69]: t.score = 100
__slots__
迭代器
迭代是访问集合元素的⼀种⽅式。迭代器是⼀个可以记住遍历的位置的对象。迭代器对象从集合的第⼀个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
1. 可迭代对象
以直接作⽤于 for 循环的数据类型有以下⼏种:
⼀类是集合数据类型,如 list 、 tuple 、 dict 、 set 、 str 等;
⼀类是 generator ,包括⽣成器和带 yield 的generator function。
这些可以直接作⽤于 for 循环的对象统称为可迭代对象: Iterable 。
2. 判断是否可以迭代可以使⽤ isinstance() 判断⼀个对象是否是 Iterable 对象:
|
In [50]: from collections import Iterable In [51]: isinstance([], Iterable) Out[51]: True In [52]: isinstance({}, Iterable) Out[52]: True In [53]: isinstance('abc', Iterable) Out[53]: True In [54]: isinstance((x for x in range(10)), Iterable) Out[54]: True |
In [55]: isinstance(100, Iterable)
Out[55]: False
⽽⽣成器不但可以作⽤于 for 循环,还可以被 next() 函数不断调⽤并返回下⼀个值,直到最后抛出 StopIteration 错误表示⽆法继续返回下⼀个值了。
3.迭代器
可以被next()函数调⽤并不断返回下⼀个值的对象称为迭代器:Iterator。
可以使⽤ isinstance() 判断⼀个对象是否是 Iterator 对象:
|
In [56]: from collections import Iterator In [57]: isinstance((x for x in range(10)), Iterator) Out[57]: True In [58]: isinstance([], Iterator) Out[58]: False In [59]: isinstance({}, Iterator) Out[59]: False In [60]: isinstance('abc', Iterator) Out[60]: False In [61]: isinstance(100, Iterator) Out[61]: False |
4.iter()函数
⽣成器都是 Iterator 对象,但 list 、 dict 、 str 虽然是 Iterable ,却不是
Iterator 。
把 list 、 dict 、 str 等 Iterable 变成 Iterator 可以使⽤ iter() 函数:
In [62]: isinstance(iter([]), Iterator)
Out[62]: True
In [63]: isinstance(iter('abc'), Iterator)
Out[63]: True
总结
凡是可作⽤于 for 循环的对象都是 Iterable 类型;凡是可作⽤于 next() 函数的对象都是 Iterator 类型集合数据类型如 list 、 dict 、 str 等是 Iterable 但不是 Iterator ,不过可以通过 iter() 函数获得⼀个 Iterator 对象。
闭包
1. 函数引⽤
|
def test1(): print("--- in test1 func----") #调⽤函数 test1() #引⽤函数 ret = test1 print(id(ret)) print(id(test1)) #通过引⽤调⽤函数 ret() |
运⾏结果:
--- in test1 func----
140212571149040
140212571149040
--- in test1 func----
2. 什么是闭包
#定义⼀个函数
def test(number):
#在函数内部再定义⼀个函数,并且这个函数⽤到了外边函数的变量,那么将这个函
def test_in(number_in):
|
print("in test_in 函数, number_in is %d"%number_in) return number+number_in #其实这⾥返回的就是闭包的结果 return test_in #给test函数赋值,这个20就是给参数number ret = test(20) #注意这⾥的100其实给参数number_in print(ret(100)) #注意这⾥的200其实给参数number_in print(ret(200)) |
运⾏结果:
in test_in 函数, number_in is 100
120
in test_in 函数, number_in is 200
220
3. 闭包再理解
内部函数对外部函数作⽤域⾥变量的引⽤(⾮全局变量),则称内部函数为闭包。
# closure.py
def counter(start=0): count=[start] def incr():
count[0] += 1
return count[0] return incr
启动python解释器
|
>>>import closeure >>>c1=closeure.counter(5) >>>print(c1()) 6 >>>print(c1()) 7 >>>c2=closeure.counter(100) >>>print(c2()) 101 >>>print(c2()) 102 |
nonlocal访问外部函数的局部变量(python3)
def counter(start=0): def incr(): nonlocal start start += 1 return start return incr
c1 = counter(5) print(c1()) print(c1())
c2 = counter(50) print(c2()) print(c2())
print(c1()) print(c1()) print(c2()) print(c2())
4. 看⼀个闭包的实际例⼦:
def line_conf(a, b): def line(x): return a*x + b return line
line1 = line_conf(1, 1) line2 = line_conf(4, 5) print(line1(5)) print(line2(5))
这个例⼦中,函数line与变量a,b构成闭包。在创建闭包的时候,我们通过 line_conf的参数a,b说明了这两个变量的取值,这样,我们就确定了函数的最终形式(y = x + 1和y = 4x + 5)。我们只需要变换参数a,b,就可以获得不同的
直线表达函数。由此,我们可以看到,闭包也具有提⾼代码可复⽤性的作⽤。
如果没有闭包,我们需要每次创建直线函数的时候同时说明a,b,x。这样,我们就需要更多的参数传递,也减少了代码的可移植性。
闭包思考:
装饰器
装饰器是程序开发中经常会⽤到的⼀个功能,⽤好了装饰器,开发效率如⻁ 添翼,所以这也是Python⾯试中必问的问题,但对于好多初次接触这个知识的⼈来讲,这个功能有点绕,⾃学时直接绕过去了,然后⾯试问到了就挂
了,因为装饰器是程序开发的基础知识,这个都不会,别跟⼈家说你会
Python, 看了下⾯的⽂章,保证你学会装饰器。
1、先明⽩这段代码
|
#### 第⼀波 #### def foo(): print('foo') foo #表示是函数 foo() #表示执⾏foo函数 #### 第⼆波 #### def foo(): print('foo') foo = lambda x: x + 1 foo() # 执⾏下⾯的lambda表达式,⽽不再是原来的foo函数,因为foo这个名字 |
2、需求来了
初创公司有N个业务部⻔,1个基础平台部⻔,基础平台负责提供底层的功能,如:数据库操作、redis调⽤、监控API等功能。业务部⻔使⽤基础功能时,只需调⽤基础平台提供的功能即可。如下:
|
############### 基础平台提供的功能如下 ############### def f1(): print('f1') def f2(): print('f2') def f3(): print('f3') def f4(): print('f4') ############### 业务部⻔A 调⽤基础平台提供的功能 ############### f1() f2() f3() f4() ############### 业务部⻔B 调⽤基础平台提供的功能 ############### f1() f2() f3() f4() |
⽬前公司有条不紊的进⾏着,但是,以前基础平台的开发⼈员在写代码时候没有关注验证相关的问题,即:基础平台的提供的功能可以被任何⼈使⽤。现在需要对基础平台的所有功能进⾏重构,为平台提供的所有功能添加验证机制,即:执⾏功能前,先进⾏验证。
⽼⼤把⼯作交给 Low B,他是这么做的:
跟每个业务部⻔交涉,每个业务部⻔⾃⼰写代码,调⽤基础平台的功能之前先验证。诶,这样⼀来基础平台就不需要做任何修改了。太棒了,有充⾜的时间泡妹⼦...
当天Low B 被开除了…
⽼⼤把⼯作交给 Low BB,他是这么做的:
|
############### 基础平台提供的功能如下 ############### def f1(): # 验证1 # 验证2 # 验证3 print('f1') def f2(): # 验证1 # 验证2 # 验证3 print('f2') def f3(): # 验证1 # 验证2 # 验证3 print('f3') def f4(): # 验证1 # 验证2 # 验证3 print('f4') ############### 业务部⻔不变 ############### ### 业务部⻔A 调⽤基础平台提供的功能### |
|
f1() f2() f3() f4() ### 业务部⻔B 调⽤基础平台提供的功能 ### f1() f2() f3() f4() |
过了⼀周 Low BB 被开除了…
⽼⼤把⼯作交给 Low BBB,他是这么做的:
只对基础平台的代码进⾏重构,其他业务部⻔⽆需做任何修改
|
############### 基础平台提供的功能如下 ############### def check_login(): # 验证1 # 验证2 # 验证3 pass def f1(): check_login() print('f1') def f2(): check_login() |
print('f2')
def f3():
check_login()
print('f3')
def f4():
check_login()
print('f4')
⽼⼤看了下Low BBB 的实现,嘴⻆漏出了⼀丝的欣慰的笑,语重⼼⻓的跟 Low BBB聊了个天:
⽼⼤说:
写代码要遵循开放封闭 原则,虽然在这个原则是⽤的⾯向对象开发,但是也适⽤于函数式编程,简单来说,它规定已经实现的功能代码不允许被修改,但可以被扩展,即:
封闭:已实现的功能代码块开放:对扩展开发
如果将开放封闭原则应⽤在上述需求中,那么就不允许在函数 f1 、f2、f3、 f4的内部进⾏修改代码,⽼板就给了Low BBB⼀个实现⽅案:
def w1(func): def inner(): # 验证1
# 验证2 # 验证3 func() return inner
|
@w1 def f1(): print('f1') @w1 def f2(): print('f2') @w1 def f3(): print('f3') @w1 def f4(): print('f4') |
对于上述代码,也是仅仅对基础平台的代码进⾏修改,就可以实现在其他⼈调⽤函数 f1 f2 f3 f4 之前都进⾏【验证】操作,并且其他业务部⻔⽆需做任何操作。
Low BBB⼼惊胆战的问了下,这段代码的内部执⾏原理是什么呢?
⽼⼤正要⽣⽓,突然Low BBB的⼿机掉到地上,恰巧屏保就是Low BBB的⼥友照⽚,⽼⼤⼀看⼀紧⼀抖,喜笑颜开,决定和Low BBB交个好朋友。
详细的开始讲解了:单独以f1为例:
|
def w1(func): def inner(): # 验证1 # 验证2 # 验证3 func() return inner @w1 def f1(): print('f1') |
python解释器就会从上到下解释代码,步骤如下:
- def w1(func): ==>将w1函数加载到内存
- @w1
没错, 从表⾯上看解释器仅仅会解释这两句代码,因为函数在 没有被调⽤之前其内部代码不会被执⾏。
从表⾯上看解释器着实会执⾏这两句,但是 @w1 这⼀句代码⾥却有⼤⽂章, @函数名 是python的⼀种语法糖。
上例@w1内部会执⾏⼀下操作:
执⾏w1函数
w1的返回值
|
新f1 = def inner(): #验证 1 #验证 2 #验证 3 原来f1() |
将执⾏完的w1函数返回值 赋值 给@w1下⾯的函数的函数名f1 即将w1 的返回值再重新赋值给 f1,即:
|
return inner |
所以,以后业务部⻔想要执⾏ f1 函数时,就会执⾏ 新f1 函数,在新f1 函数内部先执⾏验证,再执⾏原来的f1函数,然后将原来f1 函数的返回值返回给了业务调⽤者。
如此⼀来, 即执⾏了验证的功能,⼜执⾏了原来f1函数的内容,并将原f1函数返回值 返回给业务调⽤着
Low BBB 你明⽩了吗?要是没明⽩的话,我晚上去你家帮你解决吧!!!
3. 再议装饰器
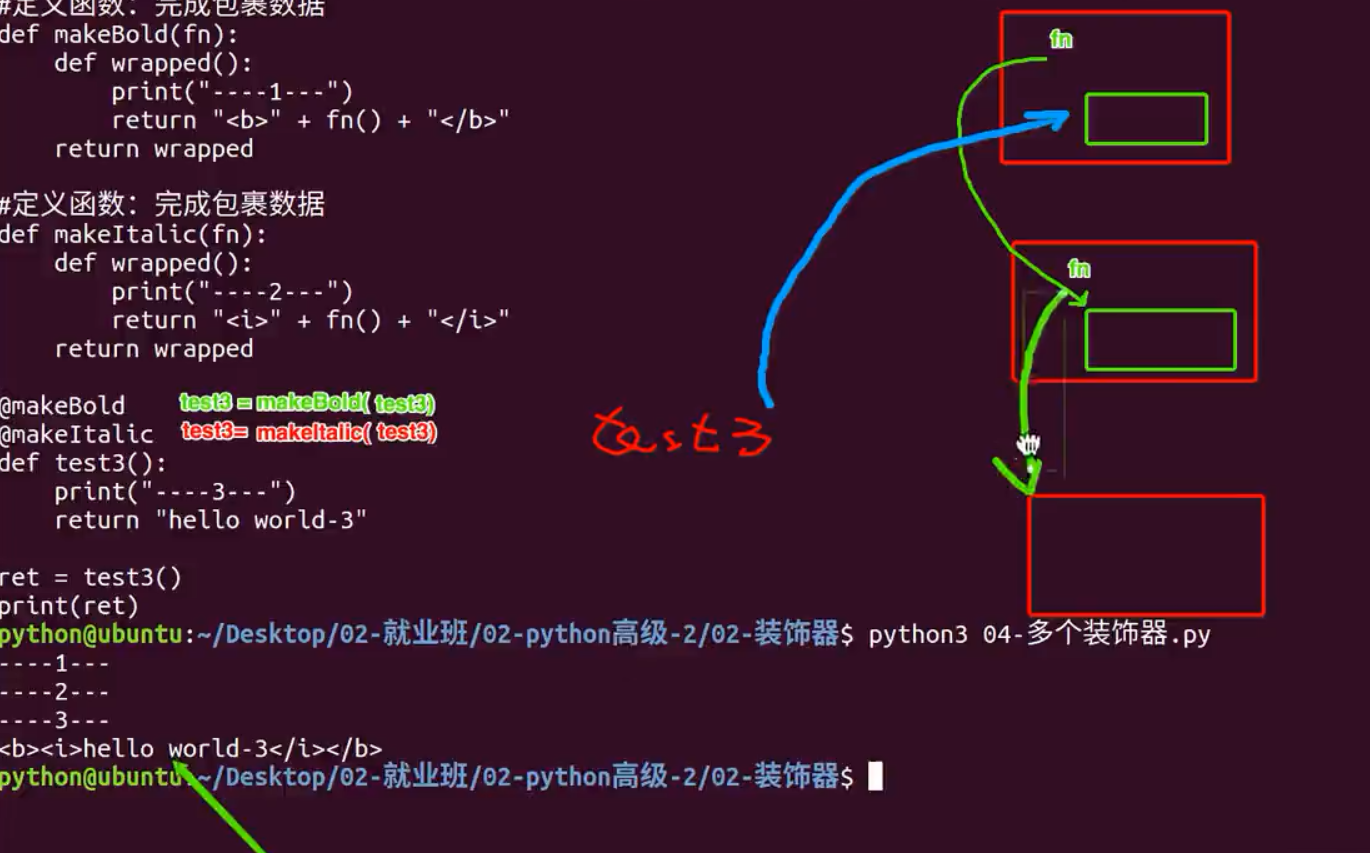
|
#定义函数:完成包裹数据 def makeBold(fn): def wrapped(): return "<b>" + fn() + "</b>" return wrapped #定义函数:完成包裹数据 def makeItalic(fn): def wrapped(): return "<i>" + fn() + "</i>" return wrapped @makeBold def test1(): return "hello world-1" @makeItalic def test2(): return "hello world-2" @makeBold @makeItalic |
def test3(): return "hello world-3"
print(test1())) print(test2())) print(test3()))
运⾏结果:
<b>hello world-1</b>
<i>hello world-2</i>
<b><i>hello world-3</i></b>
4. 装饰器(decorator)功能
- 引⼊⽇志
- 函数执⾏时间统计
- 执⾏函数前预备处理
- 执⾏函数后清理功能
- 权限校验等场景
- 缓存
5. 装饰器示例例1:⽆参数的函数
|
from time import ctime, sleep def timefun(func): def wrappedfunc(): print("%s called at %s"%(func.__name__, ctime())) func() |
|
return wrappedfunc @timefun def foo(): print("I am foo") foo() sleep(2) foo() |
上⾯代码理解装饰器执⾏⾏为可理解成
foo = timefun(foo)
#foo先作为参数赋值给func后,foo接收指向timefun返回的wrappedfunc foo()
#调⽤foo(),即等价调⽤wrappedfunc()
#内部函数wrappedfunc被引⽤,所以外部函数的func变量(⾃由变量)并没有释放
#func⾥保存的是原foo函数对象
例2:被装饰的函数有参数
|
from time import ctime, sleep def timefun(func): def wrappedfunc(a, b): print("%s called at %s"%(func.__name__, ctime())) print(a, b) func(a, b) return wrappedfunc @timefun def foo(a, b): print(a+b) foo(3,5) sleep(2) |
foo(2,4)
例3:被装饰的函数有不定⻓参数
|
from time import ctime, sleep def timefun(func): def wrappedfunc(*args, **kwargs): print("%s called at %s"%(func.__name__, ctime())) func(*args, **kwargs) return wrappedfunc @timefun def foo(a, b, c): print(a+b+c) foo(3,5,7) sleep(2) foo(2,4,9) |
例4:装饰器中的return
|
from time import ctime, sleep def timefun(func): def wrappedfunc(): print("%s called at %s"%(func.__name__, ctime())) func() return wrappedfunc @timefun def foo(): print("I am foo") @timefun |
|
def getInfo(): return '----hahah---' foo() sleep(2) foo() print(getInfo()) |
执⾏结果:
|
foo called at Fri Nov 4 21:55:35 2016 I am foo foo called at Fri Nov 4 21:55:37 2016 I am foo getInfo called at Fri Nov 4 21:55:37 2016 None |
如果修改装饰器为 return func() ,则运⾏结果:
|
foo called at Fri Nov 4 21:55:57 2016 I am foo foo called at Fri Nov 4 21:55:59 2016 I am foo getInfo called at Fri Nov 4 21:55:59 2016 ----hahah--- |
总结:
⼀般情况下为了让装饰器更通⽤,可以有return
例5:装饰器带参数,在原有装饰器的基础上,设置外部变量
|
#decorator2.py from time import ctime, sleep def timefun_arg(pre="hello"): def timefun(func): def wrappedfunc(): print("%s called at %s %s"%(func.__name__, ctime(), return func() return wrappedfunc return timefun @timefun_arg("itcast") def foo(): print("I am foo") @timefun_arg("python") def too(): print("I am too") foo() sleep(2) foo() too() sleep(2) too() |
可以理解为
foo()==timefun_arg("itcast")(foo)()
例6:类装饰器(扩展,⾮重点)
装饰器函数其实是这样⼀个接⼝约束,它必须接受⼀个callable对象作为参
数,然后返回⼀个callable对象。在Python中⼀般callable对象都是函数,但
也有例外。只要某个对象重写了 __call__() ⽅法,那么这个对象就是 callable的。
|
class Test(): def __call__(self): print('call me!') t = Test() t() # call me |
类装饰器demo
|
class Test(object): def __init__(self, func): print("---初始化---") print("func name is %s"%func.__name__) self.__func = func def __call__(self): print("---装饰器中的功能---") self.__func() #说明: #1. 当⽤Test来装作装饰器对test函数进⾏装饰的时候,⾸先会创建Test的实例对象 # 并且会把test这个函数名当做参数传递到__init__⽅法中 # 即在__init__⽅法中的func变量指向了test函数体 # #2. test函数相当于指向了⽤Test创建出来的实例对象 # #3. 当在使⽤test()进⾏调⽤时,就相当于让这个对象(),因此会调⽤这个对象的 # #4. 为了能够在__call__⽅法中调⽤原来test指向的函数体,所以在__init__⽅法 # 所以才有了self.__func = func这句代码,从⽽在调⽤__call__⽅法中能够 @Test def test(): |
__
运⾏结果如下:
---初始化---
func name is test
---装饰器中的功能---
----test---
其他的知识点
import导⼊模块
1. import 搜索路径
import sys sys.path
路径搜索
从上⾯列出的⽬录⾥依次查找要导⼊的模块⽂件
' ' 表示当前路径
程序执⾏时导⼊模块路径
sys.path.append('/home/itcast/xxx')
sys.path.insert(0, '/home/itcast/xxx') #可以确保先搜索这个路径
In [37]: sys.path.insert(0,"/home/python/xxxx")
In [38]: sys.path Out[38]: ['/home/python/xxxx',
'',
'/usr/bin',
'/usr/lib/python35.zip',
'/usr/lib/python3.5',
'/usr/lib/python3.5/plat-x86_64-linux-gnu',
'/usr/lib/python3.5/lib-dynload',
'/usr/local/lib/python3.5/dist-packages',
'/usr/lib/python3/dist-packages',
'/usr/lib/python3/dist-packages/IPython/extensions', '/home/python/.ipython']
2. 重新导⼊模块
循环导⼊
1. 什么是循环导⼊
a.py
from b import b
print '---------this is module a.py----------' def a(): print("hello, a") b()
a()
b.py
|
from a import a print '----------this is module b.py----------' def b(): print("hello, b") def c(): a() c() |
运⾏python a.py
循环导⼊
2. 怎样避免循环导⼊
- 程序设计上分层,降低耦合
- 导⼊语句放在后⾯需要导⼊时再导⼊,例如放在函数体内导⼊
循环导⼊
作⽤域
什么是命名空间
⽐如有⼀个学校,有10个班级,在7班和8班中都有⼀个叫“⼩王”的同学,如果在学校的⼴播中呼叫“⼩王”时,7班和8班中的这2个⼈就纳闷了,你是喊谁呢!!!如果是“7班的⼩王”的话,那么就很明确了,那么此时的7班就是⼩王所在的范围,即命名空间 globals、locals
LEGB 规则
Python 使⽤ LEGB 的顺序来查找⼀个符号对应的对象
locals -> enclosing function -> globals -> builtins
locals,当前所在命名空间(如函数、模块),函数的参数也属于命名空间内的变量 enclosing,外部嵌套函数的命名空间(闭包中常⻅)
|
def fun1(): a = 10 def fun2(): # a 位于外部嵌套函数的命名空间 print(a) |
globals,全局变量,函数定义所在模块的命名空间
|
a = 1 def fun(): # 需要通过 global 指令来声明全局变量 global a # 修改全局变量,⽽不是创建⼀个新的 local 变量 a = 2 |
builtins,内建模块的命名空间。
Python 在启动的时候会⾃动为我们载⼊很多内建的函数、类,
⽐如 dict,list,type,print,这些都位于 __builtin__ 模块中,
|
可以使⽤ dir(__builtin__) 来查看。 这也是为什么我们在没有 import任何模块的情况下, 就能使⽤这么多丰富的函数和功能了。 在Python中,有⼀个内建模块,该模块中有⼀些常⽤函数;在Python启动后, 且没有执⾏程序员所写的任何代码前,Python会⾸先加载该内建函数到内存。 另外,该内建模块中的功能可以直接使⽤,不⽤在其前添加内建模块前缀, 其原因是对函数、变量、类等标识符的查找是按LEGB法则,其中B即代表内建模 ⽐如:内建模块中有⼀个abs()函数,其功能求绝对值,如abs(-20)将返回 |
20
==、is
总结
is 是⽐较两个引⽤是否指向了同⼀个对象(引⽤⽐较)。
== 是⽐较两个对象是否相等。
==、is
深拷⻉、浅拷⻉
1. 浅拷⻉
浅拷⻉是对于⼀个对象的顶层拷⻉
通俗的理解是:拷⻉了引⽤,并没有拷⻉内容
2. 深拷⻉
In [23]: a = [11,22,33]
In [24]: b = [44,55,66]
In [25]: c = (a,b)
In [26]: e = copy.deepcopy(c)
In [27]: a.append(77)
In [28]: a
Out[28]: [11, 22, 33, 77]
In [29]: b
Out[29]: [44, 55, 66]
In [30]: c
Out[30]: ([11, 22, 33, 77], [44, 55, 66])
In [31]: e
Out[31]: ([11, 22, 33], [44, 55, 66])
In [32]:
In [32]:
In [32]: f = copy.copy(c)
In [33]: a.append(88)
In [34]: a
Out[34]: [11, 22, 33, 77, 88]
In [35]: b
Out[35]: [44, 55, 66]
In [36]: c
Out[36]: ([11, 22, 33, 77, 88], [44, 55, 66])
In [37]: e
Out[37]: ([11, 22, 33], [44, 55, 66])
In [38]: f
Out[38]: ([11, 22, 33, 77, 88], [44, 55, 66])
3. 拷⻉的其他⽅式
浅拷⻉对不可变类型和可变类型的copy不同
In [88]: a = [11,22,33]
In [89]: b = copy.copy(a)
In [90]: id(a)
Out[90]: 59275144
In [91]: id(b)
|
Out[91]: 59525600 In [92]: a.append(44) In [93]: a Out[93]: [11, 22, 33, 44] In [94]: b Out[94]: [11, 22, 33] In [95]: In [95]: In [95]: a = (11,22,33) In [96]: b = copy.copy(a) In [97]: id(a) Out[97]: 58890680 In [98]: id(b) Out[98]: 58890680 |
分⽚表达式可以赋值⼀个序列
a = "abc"
b = a[:]
字典的copy⽅法可以拷⻉⼀个字典
d = dict(name="zhangsan", age=27)
co = d.copy()
有些内置函数可以⽣成拷⻉(list)
a = list(range(10))
b = list(a)
copy模块中的copy函数
import copy
a = (1,2,3)
b = copy.copy(a)
进制、位运算
1、什么是进制
1)理解个X进制的概念 :
每⼀位 只允许出现 0~X-1 这⼏个数字,逢X进⼀,基是X, 每⼀位有⼀个权值⼤
⼩是X的幂次。 其表示的数值可以写成按位权展开的多项式之和。
⼗进制: 每⼀位只允许出现0~9这⼗个数字,逢⼗进1,基是⼗,每⼀位数字有⼀个权值⼤⼩是⼗的幂次。 其表示的数值可以写成按位权展开的多项式之和。
⼆进制: 每⼀位只允许出现0~1这⼆个数字,逢⼆进1,基是 ⼆, 每⼀位数字有⼀个权值⼤⼩是⼆的幂次。 其表示的数值可以写成按位权展开的多项式之和。
⼋进制:
⼗六进制
2)
假如⽤两个字节表示 ⼀个整数, 如下:
⼗进制数字1 的⼆进制表现形式: 0000 0000 0000 0001 ⼗进制数字2 的⼆进制表现形式: 0000 0000 0000 0010
如何表示⼆进制数的正负?
3)有符号数和⽆符号数的概念
规则:把⼆进制数中的最⾼位(最左边的那位)⽤作符号位
对于有符号数,最⾼位被计算机系统规定为符号位(0为正,1为负) 对于⽆符号数,最⾼位被计算机系统规定为数据位
按照这种说法,⽐如有符号数 +2 -2 的原码形式:
+2 = 0000 0000 0000 0010
-2 = 1000 0000 0000 0010
真值 机器数
+1 = 0000 0000 0000 0001
-1 = 1000 0000 0000 0001
-----------------------------------------
1000 0000 0000 0010
-1+1 的结果?
-1+1 = 1000 0000 0000 0010 ----》 -2
不等于0,按理说-1+1等于0才对,为什么会是-2呢?规则
数字在计算机中,是⽤⼆进制补码的形式来保存的,因此-1 +1需要按照补码进⾏相加才是正确的结果
2、原码、反码、补码
1) 如何计算补码?
规则:
正数:原码 = 反码 = 补码负数:反码 = 符号位不变,其他位取反
补码 = 反码+1
1 的原码:0000 0000 0000 0001
-1的原码:1000 0000 0000 0001
-1的反码:1111 1111 1111 1110
-1的补码:1111 1111 1111 1111
重新计算 -1+1 结果
1111 1111 1111 1111
0000 0000 0000 0001
--------------------------0000 0000 0000 0000
2) 从补码转回原码负数补码转换原码的规则:
|
原码 = 补码的符号位不变 -->数据位取反--> 尾+1 -1的补码:1111 1111 1111 1111 取反:1000 0000 0000 0000 -1的原码:1000 0000 0000 0001 |
【了解】可以把减法⽤加法来算,只需设计加法器就好了。运算的时候都是⽤补码去
运算的。 2-1 = 2+(-1)=0000 0000 0000 0010 +1111 1111 1111 1111
【了解】
为何要使⽤原码, 反码和补码 既然原码才是被⼈脑直接识别并⽤于计算表示
⽅式, 为何还会有反码和补码呢? ⾸先, 因为⼈脑可以知道第⼀位是符号位, 在计算的时候我们会根据符号位, 选择对应加减,但是对于计算机,加减乘数已经是最基础的运算, 要设计的尽量简单。计算机辨别"符号位"显然会让计算机的基础电路设计变得⼗分复杂!于是⼈们想出了将符号位也参与运算的⽅法. 我们知道,根据运算法则减去⼀个正数等于加上⼀个负数, 即: 1-1 = 1 + (-1) = 0 , 所以机器可以只有加法⽽没有减法, 这样计算机运算的设计就更简单了.
于是⼈们开始探索 将符号位参与运算, 并且只保留加法的⽅法
3. 进制间转换
#10进制转为2进制
>>> bin(10)
'0b1010'
#2进制转为10进制
>>> int("1001",2)
9
#10进制转为16进制
>>> hex(10)
'0xa'
#16进制到10进制
>>> int('ff', 16)
255
>>> int('0xab', 16)
171
#16进制到2进制
>>> bin(0xa)
'0b1010'
>>>
#10进制到8进制
>>> oct(8)
'010'
#2进制到16进制
>>> hex(0b1001)
'0x9'
4. 位运算
看如下示例:
如果有⼀个⼗进制数 5,其⼆进制为: 0000 0101 把所有的数向左移动⼀位 其结果为: 0000 1010
想⼀想:⼆进制 0000 1010 ⼗进制是多少呢???其答案为10,有没有发现是5的2倍呢!
再假设有⼀个⼗进制数 3, 其⼆进制 为: 0000 0011 把所有的数向左移动⼀位 其结果为: 0000 0110
⼆进制0000 0110 的⼗进制为6,正好也是3的2倍
通过以上2个例⼦,能够看出,把⼀个数的各位整体向左移动⼀个位,就变成原来的2倍
那么在Python中,怎样实现向左移动呢?还有其他的吗???
<1>位运算的介绍
& 按位与
| 按位或
^ 按位异或
~ 按位取反
<< 按位左移
>> 按位右移
⽤途: 直接操作⼆进制,省内存,效率⾼
<2>位运算
1)<< 按位左移
各⼆进位全部左移n位,⾼位丢弃,低位补0
x << n 左移 x 的所有⼆进制位向左移动n位,移出位删掉,移进的位补零
【注意事项】
a. 左移1位相当于 乘以2
⽤途:快速计算⼀个数乘以2的n次⽅ (8<<3 等同于8*2^3)
b.左移可能会改变⼀个数的正负性
2)>> 右移
【注意事项】
右移1位相当于 除以2
x 右移 n 位就相当于除以2的n次⽅ ⽤途:快速计算⼀个数除以2的n次⽅
(8>>3 等同于8/2^3)
3)& 按位与
全1才1否则0 :只有对应的两个⼆进位均为1时,结果位才为1,否则为0
⽤6和3这个例⼦。不要⽤9 和13的例⼦
4) | 按位或
有1就1 只要对应的⼆个⼆进位有⼀个为1时,结果位就为1,否则为0
5) ^ 按位异或
不同为1 当对应的⼆进位相异(不相同)时,结果为1,否则为0
6) ~ 取反
~9 = -10
【为什么9取反变成了-10的说明】:
9的原码 ==> 0000 1001 因为正数的原码=反码=补码,所以在 真正存储的时候就是0000 1001
接下来进⾏对9的补码进⾏取反操作
进⾏取反==> 1111 0110 这就是对9 进⾏了取反之后的补码
既然已经知道了补码,那么接下来只要转换为 咱们⼈能识别的码型就可以,因此按照规则 ,把这个1111 0110 这个补码 转换为原码即可符号位不变,其它位取反==> 1000 1001 然后+1 ,得到原码 =======>1000 1010 这就是 -10
【扩展】
1)任何数和1进⾏&操作,得到这个数的最低位 数字&1 = 数字的⼆进制形式的最低位
2)位运算优先级
私有化
xx: 公有变量
_x: 单前置下划线,私有化属性或⽅法,from somemodule import *禁⽌导
⼊,类对象和⼦类可以访问
__xx:双前置下划线,避免与⼦类中的属性命名冲突,⽆法在外部直接访问(名字重整所以访问不到)
__xx__:双前后下划线,⽤户名字空间的魔法对象或属性。例如: __init__ , __ 不要⾃⼰发明这样的名字
xx_:单后置下划线,⽤于避免与Python关键词的冲突
通过name mangling(名字重整(⽬的就是以防⼦类意外重写基类的⽅法或者属性)如:_Class__object)机制就可以访问private了。
|
#coding=utf-8 class Person(object): def __init__(self, name, age, taste): self.name = name self._age = age self.__taste = taste def showperson(self): print(self.name) print(self._age) print(self.__taste) def dowork(self): self._work() self.__away() def _work(self): print('my _work') |
|
def __away(self): print('my __away') class Student(Person): def construction(self, name, age, taste): self.name = name self._age = age self.__taste = taste def showstudent(self): print(self.name) print(self._age) print(self.__taste) @staticmethod def testbug(): _Bug.showbug() #模块内可以访问,当from cur_module import *时,不导⼊ class _Bug(object): @staticmethod def showbug(): print("showbug") s1 = Student('jack', 25, 'football') s1.showperson() print('*'*20) #⽆法访问__taste,导致报错 #s1.showstudent() s1.construction('rose', 30, 'basketball') s1.showperson() print('*'*20) s1.showstudent() print('*'*20) Student.testbug() |
总结
⽗类中属性名为 __名字 的,⼦类不继承,⼦类不能访问
如果在⼦类中向 __名字 赋值,那么会在⼦类中定义的⼀个与⽗类相同名字的属性
_名 的变量、函数、类在使⽤ from xxx import * 时都不会被导⼊
属性property
1. 私有属性添加getter和setter⽅法
|
class Money(object): def __init__(self): self.__money = 0 def getMoney(self): return self.__money def setMoney(self, value): if isinstance(value, int): self.__money = value else: print("error:不是整型数字") |
2. 使⽤property升级getter和setter⽅法
|
class Money(object): def __init__(self): self.__money = 0 def getMoney(self): return self.__money def setMoney(self, value): if isinstance(value, int): self.__money = value else: print("error:不是整型数字") money = property(getMoney, setMoney) |
|
class Money(object): def __init__(self): self.__money = 0 @property def money(self): return self.__money |
运⾏结果:
|
In [1]: from get_set import Money In [2]: In [2]: a = Money() In [3]: In [3]: a.money Out[3]: 0 In [4]: a.money = 100 In [5]: a.money Out[5]: 100 In [6]: a.getMoney() Out[6]: 100 |
3. 使⽤property取代getter和setter⽅法
@property 成为属性函数,可以对属性赋值时做必要的检查,并保证代码的清晰短⼩,主要有2个作⽤
将⽅法转换为只读
重新实现⼀个属性的设置和读取⽅法,可做边界判定
|
@money.setter def money(self, value): if isinstance(value, int): self.__money = value else: print("error:不是整型数字") |
运⾏结果
In [3]: a = Money() In [4]:
In [4]:
In [4]: a.money
Out[4]: 0
In [5]: a.money = 100
In [6]: a.money
Out[6]: 100
其他的知识点其他的知识点
垃圾回收
1. ⼩整数对象池
整数在程序中的使⽤⾮常⼴泛,Python为了优化速度,使⽤了⼩整数对象池, 避免为整数频繁申请和销毁内存空间。
Python 对⼩整数的定义是 [-5, 257) 这些整数对象是提前建⽴好的,不会被垃圾回收。在⼀个 Python 的程序中,所有位于这个范围内的整数使⽤的都是同⼀个对象.
同理,单个字⺟也是这样的。
但是当定义2个相同的字符串时,引⽤计数为0,触发垃圾回收
2. ⼤整数对象池
每⼀个⼤整数,均创建⼀个新的对象。
3. intern机制
a1 = "HelloWorld" a2 = "HelloWorld" a3 = "HelloWorld" a4 = "HelloWorld" a5 = "HelloWorld" a6 = "HelloWorld" a7 = "HelloWorld" a8 = "HelloWorld" a9 = "HelloWorld"
python会不会创建9个对象呢?在内存中会不会开辟9个”HelloWorld”的内存空间呢? 想⼀下,如果是这样的话,我们写10000个对象,⽐如
a1=”HelloWorld”…..a1000=”HelloWorld”, 那他岂不是开辟了1000
个”HelloWorld”所占的内存空间了呢?如果真这样,内存不就爆了吗?所以 python中有这样⼀个机制—— intern机制 ,让他只占⽤⼀个”HelloWorld”所占的内存空间。靠引⽤计数去维护何时释放。
总结
⼩整数[-5,257)共⽤对象,常驻内存单个字符共⽤对象,常驻内存单个单词,不可修改,默认开启intern机制,共⽤对象,引⽤计数为0,则销毁
数值类型和字符串类型在 Python 中都是不可变的,这意味着你⽆法修改这个对象的值,每次对变量的修改,实际上是创建⼀个新的对象
垃圾回收(⼆)
1. Garbage collection(GC垃圾回收)
现在的⾼级语⾔如java,c#等,都采⽤了垃圾收集机制,⽽不再是c,c++⾥
⽤户⾃⼰管理维护内存的⽅式。⾃⼰管理内存极其⾃由,可以任意申请内存,但如同⼀把双刃剑,为⼤量内存泄露,悬空指针等bug埋下隐患。 对于⼀个字符串、列表、类甚⾄数值都是对象,且定位简单易⽤的语⾔,⾃然不会让⽤户去处理如何分配回收内存的问题。 python⾥也同java⼀样采⽤了垃圾收集机制,不过不⼀样的是: python采⽤的是引⽤计数机制为主,标记-清除和分代收集两种机制为辅的策略引⽤计数机制:
python⾥每⼀个东⻄都是对象,它们的核⼼就是⼀个结构体: PyObject
|
typedef struct_object { int ob_refcnt; struct_typeobject *ob_type; } PyObject; |
PyObject是每个对象必有的内容,其中ob_refcnt就是做为引⽤计数。当⼀个对象有新的引⽤时,它的ob_refcnt就会增加,当引⽤它的对象被删除,它的 ob_refcnt就会减少
|
#define Py_INCREF(op) ((op)->ob_refcnt++) //增加计数 #define Py_DECREF(op) //减少计数 if (--(op)->ob_refcnt != 0) ; else __Py_Dealloc((PyObject *)(op)) |
当引⽤计数为0时,该对象⽣命就结束了。
引⽤计数机制的优点:
简单
实时性:⼀旦没有引⽤,内存就直接释放了。不⽤像其他机制等到特定时机。实时性还带来⼀个好处:处理回收内存的时间分摊到了平时。
引⽤计数机制的缺点:
维护引⽤计数消耗资源循环引⽤
list1 = [] list2 = []
list1.append(list2) list2.append(list1)
list1与list2相互引⽤,如果不存在其他对象对它们的引⽤,list1与list2的引⽤计数也仍然为1,所占⽤的内存永远⽆法被回收,这将是致命的。 对于如今的强⼤硬件,缺点1尚可接受,但是循环引⽤导致内存泄露,注定python还将引⼊新的回收机制。(标记清除和分代收集)
2. 画说 Ruby 与 Python 垃圾回收
英⽂原⽂: visualizing garbage collection in ruby and python
2.1 应⽤程序那颗跃动的⼼
GC系统所承担的⼯作远⽐"垃圾回收"多得多。实际上,它们负责三个重要任务。它们
为新⽣成的对象分配内存 识别那些垃圾对象,并且 从垃圾对象那回收内存。
如果将应⽤程序⽐作⼈的身体:所有你所写的那些优雅的代码,业务逻辑,
算法,应该就是⼤脑。以此类推,垃圾回收机制应该是那个身体器官呢?
(我从RuPy听众那听到了不少有趣的答案:腰⼦、⽩⾎球 :) )
我认为垃圾回收就是应⽤程序那颗跃动的⼼。像⼼脏为身体其他器官提供⾎液和营养物那样,垃圾回收器为你的应该程序提供内存和对象。如果⼼脏停跳,过不了⼏秒钟⼈就完了。如果垃圾回收器停⽌⼯作或运⾏迟缓,像动脉阻塞,你的应⽤程序效率也会下降,直⾄最终死掉。
2.2 ⼀个简单的例⼦
运⽤实例⼀贯有助于理论的理解。下⾯是⼀个简单类,分别⽤Python和Ruby 写成,我们今天就以此为例:
顺便提⼀句,两种语⾔的代码竟能如此相像:Ruby 和 Python 在表达同⼀事物上真的只是略有不同。但是在这两种语⾔的内部实现上是否也如此相似呢?
2.3 Ruby 的对象分配
当我们执⾏上⾯的Node.new(1)时,Ruby到底做了什么?Ruby是如何为我们创建新的对象的呢? 出乎意料的是它做的⾮常少。实际上,早在代码开始执
⾏前,Ruby就提前创建了成百上千个对象,并把它们串在链表上,名⽈:可
⽤列表。下图所示为可⽤列表的概念图:
想象⼀下每个⽩⾊⽅格上都标着⼀个"未使⽤预创建对象"。当我们调⽤
Node.new ,Ruby只需取⼀个预创建对象给我们使⽤即可:
上图中左侧灰格表示我们代码中使⽤的当前对象,同时其他⽩格是未使⽤对象。(请注意:⽆疑我的示意图是对实际的简化。实际上,Ruby会⽤另⼀个对象来装载字符串"ABC",另⼀个对象装载Node类定义,还有⼀个对象装载了代码中分析出的抽象语法树,等等)
如果我们再次调⽤ Node.new,Ruby将递给我们另⼀个对象:
这个简单的⽤链表来预分配对象的算法已经发明了超过50年,⽽发明⼈这是赫赫有名的计算机科学家John McCarthy,⼀开始是⽤Lisp实现的。Lisp不仅是最早的函数式编程语⾔,在计算机科学领域也有许多创举。其⼀就是利⽤垃圾回收机制⾃动化进⾏程序内存管理的概念。标准版的Ruby,也就是众所周知的"Matz's Ruby Interpreter"(MRI),所使⽤的 GC算法与McCarthy在1960年的实现⽅式很类似。⽆论好坏,Ruby的垃圾回收机制已经53岁⾼龄了。像Lisp⼀样,Ruby预先创建⼀些对象,然后在你分配新对象或者变量的时候供你使⽤。
2.4 Python 的对象分配
我们已经了解了Ruby预先创建对象并将它们存放在可⽤列表中。那Python⼜怎么样呢?
尽管由于许多原因Python也使⽤可⽤列表(⽤来回收⼀些特定对象⽐如 list),但在为新对象和变量分配内存的⽅⾯Python和Ruby是不同的。
例如我们⽤Pyhon来创建⼀个Node对象:
与Ruby不同,当创建对象时Python⽴即向操作系统请求内存。(Python实际上实现了⼀套⾃⼰的内存分配系统,在操作系统堆之上提供了⼀个抽象层。
但是我今天不展开说了。) 当我们创建第⼆个对象的时候,再次像OS请求内存:
看起来够简单吧,在我们创建对象的时候,Python会花些时间为我们找到并分配内存。
2.5 Ruby 开发者住在凌乱的房间⾥
Ruby把⽆⽤的对象留在内存⾥,直到下⼀次GC执⾏
回过来看Ruby。随着我们创建越来越多的对象,Ruby会持续寻可⽤列表⾥取预创建对象给我们。因此,可⽤列表会逐渐变短:
...然后更短:
请注意我⼀直在为变量n1赋新值,Ruby把旧值留在原
处。"ABC","JKL"和"MNO"三个Node实例还滞留在内存中。Ruby不会⽴即清除代码中不再使⽤的旧对象!Ruby开发者们就像是住在⼀间凌乱的房间,地板上摞着⾐服,要么洗碗池⾥都是脏盘⼦。作为⼀个Ruby程序员,⽆⽤的垃圾对象会⼀直环绕着你。
2.6 Python 开发者住在卫⽣之家庭
⽤完的垃圾对象会⽴即被Python打扫⼲净
Python与Ruby的垃圾回收机制颇为不同。让我们回到前⾯提到的三个Python
Node对象:
在内部,创建⼀个对象时,Python总是在对象的C结构体⾥保存⼀个整数,称为 引⽤数 。期初,Python将这个值设置为1:
值为1说明分别有个⼀个指针指向或是引⽤这三个对象。假如我们现在创建⼀个新的Node实例,JKL:
与之前⼀样,Python设置JKL的引⽤数为1。然⽽,请注意由于我们改变了n1 指向了JKL,不再指向ABC,Python就把ABC的引⽤数置为0了。 此刻,
Python垃圾回收器⽴刻挺身⽽出!每当对象的引⽤数减为0,Python⽴即将其释放,把内存还给操作系统:
上⾯Python回收了ABC Node实例使⽤的内存。记住,Ruby弃旧对象原地于不顾,也不释放它们的内存。
Python的这种垃圾回收算法被称为引⽤计数。是George-Collins在1960年发明的,恰巧与John McCarthy发明的可⽤列表算法在同⼀年出现。就像MikeBernstein在6⽉份哥谭市Ruby⼤会杰出的垃圾回收机制演讲中说的: "1960年是垃圾收集器的⻩⾦年代..."
Python开发者⼯作在卫⽣之家,你可以想象,有个患有轻度OCD(⼀种强迫症) 的室友⼀刻不停地跟在你身后打扫,你⼀放下脏碟⼦或杯⼦,有个家伙已经准备好把它放进洗碗机了!现在来看第⼆例⼦。加⼊我们让n2引⽤n1:
上图中左边的DEF的引⽤数已经被Python减少了,垃圾回收器会⽴即回收
DEF实例。同时JKL的引⽤数已经变为了2 ,因为n1和n2都指向它。
2.7 标记-清除
最终那间凌乱的房间充斥着垃圾,再不能岁⽉静好了。在Ruby程序运⾏了⼀阵⼦以后,可⽤列表最终被⽤光光了:
此刻所有Ruby预创建对象都被程序⽤过了(它们都变灰了),可⽤列表⾥空空如也(没有⽩格⼦了)。
此刻Ruby祭出另⼀McCarthy发明的算法,名⽈:标记-清除。⾸先Ruby把程序停下来,Ruby⽤"地球停转垃圾回收⼤法"。之后Ruby轮询所有指针,变量和代码产⽣别的引⽤对象和其他值。同时Ruby通过⾃身的虚拟机便利内部指针。标记出这些指针引⽤的每个对象。我在图中使⽤M表示。
上图中那三个被标M的对象是程序还在使⽤的。在内部,Ruby实际上使⽤⼀串位值,被称为:可⽤位图(译注:还记得《编程珠玑》⾥的为突发排序吗,这对离散度不⾼的有限整数集合具有很强的压缩效果,⽤以节约机器的资源。),来跟踪对象是否被标记了。
如果说被标记的对象是存活的,剩下的未被标记的对象只能是垃圾,这意味着我们的代码不再会使⽤它了。我会在下图中⽤⽩格⼦表示垃圾对象:
接下来Ruby清除这些⽆⽤的垃圾对象,把它们送回到可⽤列表中:
在内部这⼀切发⽣得迅雷不及掩⽿,因为Ruby实际上不会吧对象从这拷⻉到那。⽽是通过调整内部指针,将其指向⼀个新链表的⽅式,来将垃圾对象归位到可⽤列表中的。
现在等到下回再创建对象的时候Ruby⼜可以把这些垃圾对象分给我们使⽤了。在Ruby⾥,对象们六道轮回,转世投胎,享受多次⼈⽣。
2.8 标记-删除 vs. 引⽤计数
乍⼀看,Python的GC算法貌似远胜于Ruby的:宁舍洁宇⽽居秽室乎?为什么Ruby宁愿定期强制程序停⽌运⾏,也不使⽤Python的算法呢?
然⽽,引⽤计数并不像第⼀眼看上去那样简单。有许多原因使得不许多语⾔不像Python这样使⽤引⽤计数GC算法:⾸先,它不好实现。Python不得不在每个对象内部留⼀些空间来处理引⽤数。这样付出了⼀⼩点⼉空间上的代价。但更糟糕的是,每个简单的操作
(像修改变量或引⽤)都会变成⼀个更复杂的操作,因为Python需要增加⼀个计数,减少另⼀个,还可能释放对象。
第⼆点,它相对较慢。虽然Python随着程序执⾏GC很稳健(⼀把脏碟⼦放在洗碗盆⾥就开始洗啦),但这并不⼀定更快。Python不停地更新着众多引⽤数值。特别是当你不再使⽤⼀个⼤数据结构的时候,⽐如⼀个包含很多元素的列表,Python可能必须⼀次性释放⼤量对象。减少引⽤数就成了⼀项复杂的递归过程了。
最后,它不是总奏效的。引⽤计数不能处理环形数据结构--也就是含有循环引⽤的数据结构。
3. Python中的循环数据结构以及引⽤计数
3.1 循环引⽤
通过上篇,我们知道在Python中,每个对象都保存了⼀个称为引⽤计数的整数值,来追踪到底有多少引⽤指向了这个对象。⽆论何时,如果我们程序中的⼀个变量或其他对象引⽤了⽬标对象,Python将会增加这个计数值,⽽当程序停⽌使⽤这个对象,则Python会减少这个计数值。⼀旦计数值被减到零,Python将会释放这个对象以及回收相关内存空间。
从六⼗年代开始,计算机科学界就⾯临了⼀个严重的理论问题,那就是针对引⽤计数这种算法来说,如果⼀个数据结构引⽤了它⾃身,即如果这个数据结构是⼀个循环数据结构,那么某些引⽤计数值是肯定⽆法变成零的。为了更好地理解这个问题,让我们举个例⼦。下⾯的代码展示了⼀些上周我们所
⽤到的节点类:
我们有⼀个"构造器"(在Python中叫做 __init__ ),在⼀个实例变量中存储⼀个单独的属性。在类定义之后我们创建两个节点,ABC以及DEF,在图中为左边的矩形框。两个节点的引⽤计数都被初始化为1,因为各有两个引⽤指向各个节点(n1和n2)。
现在,让我们在节点中定义两个附加的属性,next以及prev:
跟Ruby不同的是,Python中你可以在代码运⾏的时候动态定义实例变量或对象属性。这看起来似乎有点像Ruby缺失了某些有趣的魔法。(声明下我不是
⼀个Python程序员,所以可能会存在⼀些命名⽅⾯的错误)。我们设置
n1.next 指向 n2,同时设置 n2.prev 指回 n1。现在,我们的两个节点使⽤循环引⽤的⽅式构成了⼀个 双向链表 。同时请注意到 ABC 以及 DEF 的引⽤计数值已经增加到了2。这⾥有两个指针指向了每个节点:⾸先是 n1 以及 n2,其次就是 next 以及 prev。
现在,假定我们的程序不再使⽤这两个节点了,我们将 n1 和 n2 都设置为 null(Python中是None)。
好了,Python会像往常⼀样将每个节点的引⽤计数减少到1。
3.2 在Python中的零代(Generation Zero)
请注意在以上刚刚说到的例⼦中,我们以⼀个不是很常⻅的情况结尾:我们有⼀个“孤岛”或是⼀组未使⽤的、互相指向的对象,但是谁都没有外部引
⽤。换句话说,我们的程序不再使⽤这些节点对象了,所以我们希望Python 的垃圾回收机制能够⾜够智能去释放这些对象并回收它们占⽤的内存空间。但是这不可能,因为所有的引⽤计数都是1⽽不是0。Python的引⽤计数算法不能够处理互相指向⾃⼰的对象。
这就是为什么Python要引⼊ Generational GC 算法的原因!正如Ruby使⽤⼀个链表(free list)来持续追踪未使⽤的、⾃由的对象⼀样,Python使⽤⼀种不同的链表来持续追踪活跃的对象。⽽不将其称之为“活跃列表”,Python的内部C代码将其称为零代(Generation Zero)。每次当你创建⼀个对象或其他什么值的时候,Python会将其加⼊零代链表:
从上边可以看到当我们创建ABC节点的时候,Python将其加⼊零代链表。请注意到这并不是⼀个真正的列表,并不能直接在你的代码中访问,事实上这个链表是⼀个完全内部的Python运⾏时。 相似的,当我们创建DEF节点的时候,Python将其加⼊同样的链表:
现在零代包含了两个节点对象。(他还将包含Python创建的每个其他值,与⼀些Python⾃⼰使⽤的内部值。)
3.3 检测循环引⽤
随后,Python会循环遍历零代列表上的每个对象,检查列表中每个互相引⽤的对象,根据规则减掉其引⽤计数。在这个过程中,Python会⼀个接⼀个的统计内部引⽤的数量以防过早地释放对象。
为了便于理解,来看⼀个例⼦:
从上⾯可以看到 ABC 和 DEF 节点包含的引⽤数为1.有三个其他的对象同时存在于零代链表中,蓝⾊的箭头指示了有⼀些对象正在被零代链表之外的其他对象所引⽤。(接下来我们会看到,Python中同时存在另外两个分别被称为⼀代和⼆代的链表)。这些对象有着更⾼的引⽤计数因为它们正在被其他指针所指向着。
接下来你会看到Python的GC是如何处理零代链表的。
通过识别内部引⽤,Python能够减少许多零代链表对象的引⽤计数。在上图的第⼀⾏中你能够看⻅ABC和DEF的引⽤计数已经变为零了,这意味着收集器可以释放它们并回收内存空间了。剩下的活跃的对象则被移动到⼀个新的链表:⼀代链表。
从某种意义上说,Python的GC算法类似于Ruby所⽤的标记回收算法。周期性地从⼀个对象到另⼀个对象追踪引⽤以确定对象是否还是活跃的,正在被程序所使⽤的,这正类似于Ruby的标记过程。
Python中的GC阈值
Python什么时候会进⾏这个标记过程?随着你的程序运⾏,Python解释器保持对新创建的对象,以及因为引⽤计数为零⽽被释放掉的对象的追踪。从理论上说,这两个值应该保持⼀致,因为程序新建的每个对象都应该最终被释放掉。
当然,事实并⾮如此。因为循环引⽤的原因,并且因为你的程序使⽤了⼀些⽐其他对象存在时间更⻓的对象,从⽽被分配对象的计数值与被释放对象的计数值之间的差异在逐渐增⻓。⼀旦这个差异累计超过某个阈值,则Python 的收集机制就启动了,并且触发上边所说到的零代算法,释放“浮动的垃圾”,并且将剩下的对象移动到⼀代列表。
随着时间的推移,程序所使⽤的对象逐渐从零代列表移动到⼀代列表。⽽
Python对于⼀代列表中对象的处理遵循同样的⽅法,⼀旦被分配计数值与被释放计数值累计到达⼀定阈值,Python会将剩下的活跃对象移动到⼆代列表。
通过这种⽅法,你的代码所⻓期使⽤的对象,那些你的代码持续访问的活跃
对象,会从零代链表转移到⼀代再转移到⼆代。通过不同的阈值设置,
Python可以在不同的时间间隔处理这些对象。Python处理零代最为频繁,其次是⼀代然后才是⼆代。
弱代假说
来看看代垃圾回收算法的核⼼⾏为:垃圾回收器会更频繁的处理新对象。⼀个新的对象即是你的程序刚刚创建的,⽽⼀个来的对象则是经过了⼏个时间周期之后仍然存在的对象。Python会在当⼀个对象从零代移动到⼀代,或是从⼀代移动到⼆代的过程中提升(promote)这个对象。
为什么要这么做?这种算法的根源来⾃于弱代假说(weak generational
hypothesis)。这个假说由两个观点构成:⾸先是年亲的对象通常死得也快,
⽽⽼对象则很有可能存活更⻓的时间。
假定现在我⽤Python或是Ruby创建⼀个新对象:
根据假说,我的代码很可能仅仅会使⽤ABC很短的时间。这个对象也许仅仅只是⼀个⽅法中的中间结果,并且随着⽅法的返回这个对象就将变成垃圾
了。⼤部分的新对象都是如此般地很快变成垃圾。然⽽,偶尔程序会创建⼀些很重要的,存活时间⽐较⻓的对象-例如web应⽤中的session变量或是配置项。
通过频繁的处理零代链表中的新对象,Python的垃圾收集器将把时间花在更有意义的地⽅:它处理那些很快就可能变成垃圾的新对象。同时只在很少的时候,当满⾜阈值的条件,收集器才回去处理那些⽼变量。
垃圾回收(三)-gc模块
⼀.垃圾回收机制
Python中的垃圾回收是以引⽤计数为主,分代收集为辅。
1、导致引⽤计数+1的情况
对象被创建,例如a=23 对象被引⽤,例如b=a
对象被作为参数,传⼊到⼀个函数中,例如func(a)
对象作为⼀个元素,存储在容器中,例如list1=[a,a]
2、导致引⽤计数-1的情况
对象的别名被显式销毁,例如del a
对象的别名被赋予新的对象,例如a=24
⼀个对象离开它的作⽤域,例如f函数执⾏完毕时,func函数中的局部变量(全局变量不会)
对象所在的容器被销毁,或从容器中删除对象
3、查看⼀个对象的引⽤计数
import sys
a = "hello world"
sys.getrefcount(a)
可以查看a对象的引⽤计数,但是⽐正常计数⼤1,因为调⽤函数的时候传⼊ a,这会让a的引⽤计数+1
⼆.循环引⽤导致内存泄露引⽤计数的缺陷是循环引⽤的问题
|
import gc class ClassA(): def __init__(self): print('object born,id:%s'%str(hex(id(self)))) def f2(): while True: c1 = ClassA() c2 = ClassA() c1.t = c2 c2.t = c1 del c1 del c2 #把python的gc关闭 gc.disable() f2() |
执⾏f2(),进程占⽤的内存会不断增⼤。
创建了c1,c2后这两块内存的引⽤计数都是1,执
⾏ c1.t=c2 和 c2.t=c1 后,这两块内存的引⽤计数变成2.
在del c1后,内存1的对象的引⽤计数变为1,由于不是为0,所以内存1 的对象不会被销毁,所以内存2的对象的引⽤数依然是2,在del c2后,同理,内存1的对象,内存2的对象的引⽤数都是1。
虽然它们两个的对象都是可以被销毁的,但是由于循环引⽤,导致垃圾回收器都不会回收它们,所以就会导致内存泄露。
三.垃圾回收
|
#coding=utf-8 import gc class ClassA(): def __init__(self): print('object born,id:%s'%str(hex(id(self)))) # def __del__(self): # print('object del,id:%s'%str(hex(id(self)))) def f3(): print("-----0------") # print(gc.collect()) c1 = ClassA() c2 = ClassA() c1.t = c2 c2.t = c1 print("-----1------") del c1 del c2 print("-----2------") print(gc.garbage) print("-----3------") print(gc.collect()) #显式执⾏垃圾回收 print("-----4------") print(gc.garbage) print("-----5------") if __name__ == '__main__': gc.set_debug(gc.DEBUG_LEAK) #设置gc模块的⽇志 f3() |
python2运⾏结果:
-----0------
|
object born,id:0x724b20 object born,id:0x724b48 -----1----------2-----[] -----3------ gc: collectable <ClassA instance at 0x724b20> gc: collectable <ClassA instance at 0x724b48> gc: collectable <dict 0x723300> gc: collectable <dict 0x71bf60> 4 -----4------ [<__main__.ClassA instance at 0x724b20>, <__main__.ClassA instan -----5------ |
说明:
垃圾回收后的对象会放在gc.garbage列表⾥⾯
gc.collect()会返回不可达的对象数⽬,4等于两个对象以及它们对应的 dict
有三种情况会触发垃圾回收:
- 调⽤gc.collect(),
- 当gc模块的计数器达到阀值的时候。
- 程序退出的时候
四.gc模块常⽤功能解析
gc模块提供⼀个接⼝给开发者设置垃圾回收的选项 。上⾯说到,采⽤引⽤计数的⽅法管理内存的⼀个缺陷是循环引⽤,⽽gc模块的⼀个主要功能就是解决循环引⽤的问题。
常⽤函数:
1、gc.set_debug(flags) 设置gc的debug⽇志,⼀般设置为gc.DEBUG_LEAK
2、gc.collect([generation]) 显式进⾏垃圾回收,可以输⼊参数,0代表只检查第⼀代的对象,1代表检查⼀,⼆代的对象,2代表检查⼀,⼆,三代的对象,如果不传参数,执⾏⼀个full collection,也就是等于传2。 返回不可达
(unreachable objects)对象的数⽬
3、gc.get_threshold() 获取的gc模块中⾃动执⾏垃圾回收的频率。
4、gc.set_threshold(threshold0[, threshold1[, threshold2]) 设置⾃动执⾏垃圾回收的频率。
5、gc.get_count() 获取当前⾃动执⾏垃圾回收的计数器,返回⼀个⻓度为3 的列表
gc模块的⾃动垃圾回收机制
必须要import gc模块,并且 is_enable()=True 才会启动⾃动垃圾回收。
这个机制的 主要作⽤就是发现并处理不可达的垃圾对象 。
垃圾回收=垃圾检查+垃圾回收
在Python中,采⽤分代收集的⽅法。把对象分为三代,⼀开始,对象在创建的时候,放在⼀代中,如果在⼀次⼀代的垃圾检查中,改对象存活下来,就会被放到⼆代中,同理在⼀次⼆代的垃圾检查中,该对象存活下来,就会被放到三代中。
gc模块⾥⾯会有⼀个⻓度为3的列表的计数器,可以通过gc.get_count()获取。
例如(488,3,0),其中488是指距离上⼀次⼀代垃圾检查,Python分配内存的数⽬减去释放内存的数⽬,注意是内存分配,⽽不是引⽤计数的增加。例如:
print gc.get_count() # (590, 8, 0) a = ClassA()
print gc.get_count() # (591, 8, 0)
del a
print gc.get_count() # (590, 8, 0)
3是指距离上⼀次⼆代垃圾检查,⼀代垃圾检查的次数,同理,0是指距离上
⼀次三代垃圾检查,⼆代垃圾检查的次数。
gc模快有⼀个⾃动垃圾回收的 阀值 ,即通过gc.get_threshold函数获取到的 ⻓度为3的元组,例如(700,10,10) 每⼀次计数器的增加,gc模块就会检查增加后的计数是否达到阀值的数⽬,如果是,就会执⾏对应的代数的垃圾检查,然后重置计数器
例如,假设阀值是(700,10,10):
|
当计数器从(699,3,0)增加到(700,3,0),gc模块就会执⾏gc.collect(0),即检查当计数器从(699,9,0)增加到(700,9,0),gc模块就会执⾏gc.collect(1),即检查当计数器从(699,9,9)增加到(700,9,9),gc模块就会执⾏gc.collect(2),即检查 |
注意点
gc模块唯⼀处理不了的是循环引⽤的类都有__del__⽅法,所以项⽬中要避免定义__del__⽅法
|
import gc class ClassA(): pass # def __del__(self): # print('object born,id:%s'%str(hex(id(self)))) gc.set_debug(gc.DEBUG_LEAK) a = ClassA() b = ClassA() a.next = b |
b.prev = a
print "--1--" print gc.collect() print "--2--" del a print "--3--" del b print "--3-1--" print gc.collect() print "--4--"
运⾏结果:
|
--1-0 --2-- --3---3-1-- gc: collectable <ClassA instance at 0x21248c8> gc: collectable <ClassA instance at 0x21248f0> gc: collectable <dict 0x2123030> gc: collectable <dict 0x2123150> 4 --4-- |
如果把del打开,运⾏结果为:
|
--1-0 --2-- --3---3-1-- gc: uncollectable <ClassA instance at 0x6269b8> gc: uncollectable <ClassA instance at 0x6269e0> gc: uncollectable <dict 0x61bed0> |
|
gc: uncollectable <dict 0x6230c0> 4 --4-- |
内建属性
"teachclass.py"
class Person(object): pass
#py2中⽆继承⽗类,称之经典类,py3中已默认继承object class Person: pass
⼦类没有实现 __init__ ⽅法时,默认⾃动调⽤⽗类的。 如定义 __init__ ⽅法时,需⾃⼰⼿动调⽤⽗类的 __init__ ⽅法
|
常⽤专有属性 |
说明 |
触发⽅式 |
|
__init__ |
构造初始化函数 |
创建实例后,赋值时使⽤, 在 __new__ 后 |
|
__new__ |
⽣成实例所需属性 |
创建实例时 |
|
__class__ |
实例所在的类 |
实例. __class__ |
|
__str__ |
实例字符串表示,可读性 |
print(类实例),如没实现,使⽤repr结果 |
|
__repr__ |
实例字符串表示,准确性 |
类实例 回⻋ 或者 print(repr(类实例)) |
|
__del__ |
析构 |
del删除实例 |
|
__dict__ |
实例⾃定义属性 |
vars(实例.__dict__) |
|
__doc__ |
类⽂档,⼦类不继承 |
help(类或实例) |
|
__getattribute__ |
属性访问拦截器 |
访问实例属性时 |
|
__bases__ |
类的所有⽗类构成元素 |
类名.__bases__ |
__getattribute__ 例⼦:
class Itcast(object):
def __init__(self,subject1): self.subject1 = subject1 self.subject2 = 'cpp'
|
#属性访问时拦截器,打log def __getattribute__(self,obj): if obj == 'subject1': print('log subject1') return 'redirect python' else: #测试时注释掉这2⾏,将找不到subject2 return object.__getattribute__(self,obj) def show(self): print('this is Itcast') s = Itcast("python") print(s.subject1) print(s.subject2) |
运⾏结果:
log subject1 redirect python cpp
__getattribute__的坑
|
class Person(object): def __getattribute__(self,obj): print("---test---") if obj.startswith("a"): return "hahha" else: return self.test def test(self): print("heihei") |
|
t.Person() t.a #返回hahha t.b #会让程序死掉 #原因是:当t.b执⾏时,会调⽤Person类中定义的__getattribute__ #if条件不满⾜,所以 程序执⾏else⾥⾯的代码,即return self.test #self.test的值返回,那么⾸先要获取self.test的值,因为self此时就 #t.test 此时要获取t这个对象的test属性,那么就会跳转到__getattri #⽣了递归调⽤,由于这个递归过程中 没有判断什么时候推出,所以这个程序 #每次调⽤函数,就需要保存⼀些数据,那么随着调⽤的次数越来越多,最终 # # 注意:以后不要在__getattribute__⽅法中调⽤self.xxxx |
⽅
内建函数
Build-in Function,启动python解释器,输⼊ dir(__builtins__) , 可以看到
很多python解释器启动后默认加载的属性和函数,这些函数称之为内建函数, 这些函数因为在编程时使⽤较多,cpython解释器⽤c语⾔实现了这些函数,启动解释器 时默认加载。
这些函数数量众多,不宜记忆,开发时不是都⽤到的,待⽤到时再
help(function), 查看如何使⽤,或结合百度查询即可,在这⾥介绍些常⽤的内建函数。
range
range(stop) -> list of integers
range(start, stop[, step]) -> list of integers
start:计数从start开始。默认是从0开始。例如range(5)等价于 range(0, 5);
stop:到stop结束,但不包括stop.例如:range(0, 5) 是[0, 1, 2, 3, 4] 没有5
step:每次跳跃的间距,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
python2中range返回列表,python3中range返回⼀个迭代值。如果想得到列表,可通过list函数
a = range(5) list(a)
创建列表的另外⼀种⽅法
In [21]: testList = [x+2 for x in range(5)]
In [22]: testList
Out[22]: [2, 3, 4, 5, 6]
map函数 map函数会根据提供的函数对指定序列做映射
map(...)
map(function, sequence[, sequence, ...]) -> list
function:是⼀个函数 sequence:是⼀个或多个序列,取决于function需要⼏个参数返回值是⼀个list
参数序列中的每⼀个元素分别调⽤function函数,返回包含每次function函数返回值的list。
|
#函数需要⼀个参数 map(lambda x: x*x, [1, 2, 3]) #结果为:[1, 4, 9] #函数需要两个参数 map(lambda x, y: x+y, [1, 2, 3], [4, 5, 6]) #结果为:[5, 7, 9] def f1( x, y ): return (x,y) l1 = [ 0, 1, 2, 3, 4, 5, 6 ] l2 = [ 'Sun', 'M', 'T', 'W', 'T', 'F', 'S' ] l3 = map( f1, l1, l2 ) print(list(l3)) #结果为:[(0, 'Sun'), (1, 'M'), (2, 'T'), (3, 'W'), (4, 'T'), (5, |
filter函数 filter函数会对指定序列执⾏过滤操作
|
filter(...) filter(function or None, sequence) -> list, tuple, or string Return those items of sequence for which function(item) is t function is None, return the items that are true. If sequen or string, return the same type, else return a list. |
function:接受⼀个参数,返回布尔值True或False sequence:序列可以是str,tuple,list
filter函数会对序列参数sequence中的每个元素调⽤function函数,最后返回的结果包含调⽤结果为True的元素。返回值的类型和参数sequence的类型相同
filter(lambda x: x%2, [1, 2, 3, 4])
[1, 3]
filter(None, "she")
'she'
reduce函数 reduce函数,reduce函数会对参数序列中元素进⾏累积
reduce(...)
reduce(function, sequence[, initial]) -> value
Apply a function of two arguments cumulatively to the items from left to right, so as to reduce the sequence to a single For example, reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calcu
((((1+2)+3)+4)+5). If initial is present, it is placed befo
reduce依次从sequence中取⼀个元素,和上⼀次调⽤function的结果做参数再次调⽤function。 第⼀次调⽤function时,如果提供initial参数,会以 sequence中的第⼀个元素和initial 作为参数调⽤function,否则会以序列 sequence中的前两个元素做参数调⽤function。 注意function函数不能为 None。
reduce(lambda x, y: x+y, [1,2,3,4])
10
reduce(lambda x, y: x+y, [1,2,3,4], 5)
15
reduce(lambda x, y: x+y, ['aa', 'bb', 'cc'], 'dd')
'ddaabbcc'
在Python3⾥,reduce函数已经被从全局名字空间⾥移除了, 它现在被放置在fucntools模块⾥⽤的话要先引⼊: from functools import
reduce
sorted函数
集合set
集合与之前列表、元组类似,可以存储多个数据,但是这些数据是不重复的
集合对象还⽀持union(联合), intersection(交), difference(差)和 sysmmetric_difference(对称差集)等数学运算.
|
>>> x = set('abcd') >>> x {'c', 'a', 'b', 'd'} >>> type(x) <class 'set'> >>> >>> >>> y = set(['h','e','l','l','o']) >>> y {'h', 'e', 'o', 'l'} >>> >>> >>> z = set('spam') >>> z {'s', 'a', 'm', 'p'} >>> >>> >>> y&z #交集 set() >>> >>> >>> x&z #交集 {'a'} >>> >>> >>> x|y #并集 {'a', 'e', 'd', 'l', 'c', 'h', 'o', 'b'} >>> >>> x-y #差集 |
集合set
|
{'c', 'a', 'b', 'd'} >>> >>> >>> x^z #对称差集(在x或z中,但不会同时出现在⼆者中) {'m', 'd', 's', 'c', 'b', 'p'} >>> >>> >>> len(x) 4 >>> len(y) 4 >>> len(z) 4 >>> |
集合set
functools
functools 是python2.5被引⼈的,⼀些⼯具函数放在此包⾥。
python2.7中
python3.5中
import functools dir(functools)
运⾏结果:
['MappingProxyType',
'RLock',
'WRAPPER_ASSIGNMENTS',
'WRAPPER_UPDATES',
'WeakKeyDictionary',
'_CacheInfo',
'_HashedSeq',
'__all__',
'__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__spec__',
'_c3_merge',
'_c3_mro',
'_compose_mro',
'_convert',
'_find_impl',
'_ge_from_gt',
'_ge_from_le',
'_ge_from_lt',
'_gt_from_ge',
'_gt_from_le',
'_gt_from_lt',
'_le_from_ge',
'_le_from_gt',
'_le_from_lt',
'_lru_cache_wrapper',
'_lt_from_ge',
'_lt_from_gt',
'_lt_from_le',
'_make_key',
'cmp_to_key',
'get_cache_token',
'lru_cache',
'namedtuple',
'partial',
'partialmethod',
'reduce',
'singledispatch',
'total_ordering',
'update_wrapper',
'wraps']
python3中增加了更多⼯具函数,做业务开发时⼤多情况下⽤不到,此处介绍使⽤频率较⾼的2个函数。
partial函数(偏函数)
把⼀个函数的某些参数设置默认值,返回⼀个新的函数,调⽤这个新函数会更简单。
|
import functools def showarg(*args, **kw): print(args) print(kw) p1=functools.partial(showarg, 1,2,3) p1() p1(4,5,6) p1(a='python', b='itcast') p2=functools.partial(showarg, a=3,b='linux') p2() p2(1,2) p2(a='python', b='itcast') |
wraps函数
使⽤装饰器时,有⼀些细节需要被注意。例如,被装饰后的函数其实已经是另外⼀个函数了(函数名等函数属性会发⽣改变)。
添加后由于函数名和函数的doc发⽣了改变,对测试结果有⼀些影响,例如:
|
def note(func): "note function" def wrapper(): "wrapper function" print('note something') return func() return wrapper @note def test(): "test function" print('I am test') test() print(test.__doc__) |
运⾏结果
note something I am test wrapper function
所以,Python的functools包中提供了⼀个叫wraps的装饰器来消除这样的副作⽤。例如:
|
import functools def note(func): "note function" @functools.wraps(func) def wrapper(): "wrapper function" print('note something') return func() return wrapper @note |
def test(): "test function" print('I am test')
test() print(test.__doc__)
运⾏结果
note something I am test test function
模块进阶
Python有⼀套很有⽤的标准库(standard library)。标准库会随着Python解释
器,⼀起安装在你的电脑中的。 它是Python的⼀个组成部分。这些标准库是
Python为你准备好的利器,可以让编程事半功倍。
常⽤标准库
|
标准库 |
说明 |
|
builtins |
内建函数默认加载 |
|
os |
操作系统接⼝ |
|
sys |
Python⾃身的运⾏环境 |
|
functools |
常⽤的⼯具 |
|
json |
编码和解码 JSON 对象 |
|
logging |
记录⽇志,调试 |
|
multiprocessing |
多进程 |
|
threading |
多线程 |
|
copy |
拷⻉ |
|
time |
时间 |
|
datetime |
⽇期和时间 |
|
calendar |
⽇历 |
|
hashlib |
加密算法 |
|
random |
⽣成随机数 |
|
re |
字符串正则匹配 |
|
socket |
标准的 BSD Sockets API |
|
shutil |
⽂件和⽬录管理 |
|
glob |
基于⽂件通配符搜索 |
hashlib
|
import hashlib m = hashlib.md5() #创建hash对象,md5:(message-Digest Algorithm 5 print m #<md5 HASH object> m.update('itcast') #更新哈希对象以字符串参数 print m.hexdigest() #返回⼗六进制数字字符串 |
应⽤实例
⽤于注册、登录....
|
import hashlib import datetime KEY_VALUE = 'Itcast' now = datetime.datetime.now() m = hashlib.md5() str = '%s%s' % (KEY_VALUE,now.strftime("%Y%m%d")) m.update(str.encode('utf-8')) value = m.hexdigest() print(value) |
运⾏结果:
8ad2d682e3529dac50e586fee8dc05c0
更多标准库
常⽤扩展库
|
扩展库 |
说明 |
|
requests |
使⽤的是 urllib3,继承了urllib2的所有特性 |
|
urllib |
基于http的⾼层库 |
|
scrapy |
爬⾍ |
|
beautifulsoup4 |
HTML/XML的解析器 |
|
celery |
分布式任务调度模块 |
|
redis |
缓存 |
|
Pillow(PIL) |
图像处理 |
|
xlsxwriter |
仅写excle功能,⽀持xlsx |
|
xlwt |
仅写excle功能,⽀持xls ,2013或更早版office |
|
xlrd |
仅读excle功能 |
|
elasticsearch |
全⽂搜索引擎 |
|
pymysql |
数据库连接库 |
|
mongoengine/pymongo |
mongodbpython接⼝ |
|
matplotlib |
画图 |
|
numpy/scipy |
科学计算 |
|
django/tornado/flask |
web框架 |
|
xmltodict |
xml 转 dict |
|
SimpleHTTPServer |
简单地HTTP Server,不使⽤Web框架 |
|
gevent |
基于协程的Python⽹络库 |
|
fabric |
系统管理 |
|
pandas |
数据处理库 |
|
scikit-learn |
机器学习库 |
就可以运⾏起来静态服务。平时⽤它预览和下载⽂件太⽅便了。
在终端中输⼊命令:
python2中
python -m SimpleHTTPServer PORT
python3中
python -m http.server PORT
读写excel⽂件
1.安装个easy_install⼯具
sudo apt-get install python-setuptools
2.安装模块
sudo easy_install xlrd sudo easy_install xlwt
matplotlib
调试
pdb pdb是基于命令⾏的调试⼯具,⾮常类似gnu的gdb(调试c/c++)。
|
命令 |
简写命令 |
作⽤ |
|
break |
b |
设置断点 |
|
continue |
c |
继续执⾏程序 |
|
list |
l |
查看当前⾏的代码段 |
|
step |
s |
进⼊函数 |
|
return |
r |
执⾏代码直到从当前函数返回 |
|
quit |
q |
中⽌并退出 |
|
next |
n |
执⾏下⼀⾏ |
|
|
p |
打印变量的值 |
|
help |
h |
帮助 |
|
args |
a |
查看传⼊参数 |
|
回⻋ |
重复上⼀条命令 |
|
|
break |
b |
显示所有断点 |
|
break lineno |
b lineno |
在指定⾏设置断点 |
|
break file:lineno |
b file:lineno |
在指定⽂件的⾏设置断点 |
|
clear num |
删除指定断点 |
|
|
bt |
查看函数调⽤栈帧 |
执⾏时调试
程序启动,停⽌在第⼀⾏等待单步调试。
python -m pdb some.py
交互调试
进⼊python或ipython解释器
程序⾥埋点
当程序执⾏到pdb.set_trace() 位置时停下来调试
代码上下⽂
...
import pdb pdb.set_trace() ...
⽇志调试
print⼤法好
使⽤pdb调试的5个demo demo 1
|
import pdb a = "aaa" pdb.set_trace() b = "bbb" c = "ccc" final = a + b + c print final #调试⽅法 # 《1 显示代码》 # l---->能够显示当前调试过程中的代码,其实l表示list列出的意思 #如下,途中,-> 指向的地⽅表示要将要执⾏的位置 # 2 a = "aaa" # 3 pdb.set_trace() # 4 b = "bbb" # 5 c = "ccc" # 6 pdb.set_trace() # 7 -> final = a + b + c # 8 print final # 《2 执⾏下⼀⾏代码》 # n---->能够向下执⾏⼀⾏代码,然后停⽌运⾏等待继续调试 n表示next的意思 # 《3 查看变量的值》 # p---->能够查看变量的值,p表示prit打印输出的意思 #例如: # p name 表示查看变量name的值 |
demo 2
import pdb a = "aaa" pdb.set_trace() b = "bbb" c = "ccc"
|
pdb.set_trace() final = a + b + c print final # 《4 将程序继续运⾏》 # c----->让程序继续向下执⾏,与n的区别是n只会执⾏下⾯的⼀⾏代码,⽽c会像 # 《5 set_trace()》 # 如果程序中有多个set_trace(),那么能够让程序在使⽤c的时候停留在下⼀个set |
py
demo 3
|
#coding=utf-8 import pdb def combine(s1,s2): s3 = s1 + s2 + s1 s3 = '"' + s3 +'"' return s3 a = "aaa" pdb.set_trace() b = "bbb" c = "ccc" final = combine(a,b) print final # 《6 设置断点》 # b---->设置断点,即当使⽤c的时候,c可以在遇到set_trace()的时候停⽌,也可 #例如: #b 11 在第11⾏设置断点,注意这个11可以使⽤l来得到 # (Pdb) l # 4 s3 = s1 + s2 + s1 # 5 s3 = '"' + s3 +'"' # 6 return s3 # 7 a = "aaa" |
|
# 8 pdb.set_trace() # 9 -> b = "bbb" # 10 c = "ccc" # 11 final = combine(a,b) # 12 print final # [EOF] # (Pdb) b 11 # Breakpoint 1 at /Users/wangmingdong/Desktop/test3.py:11 # (Pdb) c # > /Users/wangmingdong/Desktop/test3.py(11)<module>() # -> final = combine(a,b) # (Pdb) l # 6 return s3 # 7 a = "aaa" # 8 pdb.set_trace() # 9 b = "bbb" # 10 c = "ccc" # 11 B-> final = combine(a,b) # 12 print final # 《7 进⼊函数继续调试》 # s---->进⼊函数⾥⾯继续调试,如果使⽤n表示把⼀个函数的调⽤当做⼀条语句执⾏ #例如 # (Pdb) l # 6 return s3 # 7 a = "aaa" # 8 pdb.set_trace() # 9 b = "bbb" # 10 c = "ccc" # 11 B-> final = combine(a,b) # 12 print final # [EOF] # (Pdb) s # --Call-- # > /Users/wangmingdong/Desktop/test3.py(3)combine() # -> def combine(s1,s2): # (Pdb) l # 1 import pdb |
|
# 2 # 3 -> def combine(s1,s2): # 4 s3 = s1 + s2 + s1 # 5 s3 = '"' + s3 +'"' # 6 return s3 # 7 a = "aaa" # 8 pdb.set_trace() # 9 b = "bbb" # 10 c = "ccc" # 11 B final = combine(a,b) # (Pdb) # 《8 查看传递到函数中的变量》 # a---->调⽤⼀个函数时,可以查看传递到这个函数中的所有的参数;a表示arg的意 #例如: # (Pdb) l # 1 #coding=utf-8 # 2 import pdb # 3 # 4 -> def combine(s1,s2): # 5 s3 = s1 + s2 + s1 # 6 s3 = '"' + s3 +'"' # 7 return s3 # 8 # 9 a = "aaa" # 10 pdb.set_trace() # 11 b = "bbb" # (Pdb) a # s1 = aaa # s2 = bbb # 《9 执⾏到函数的最后⼀步》 # r----->如果在函数中不想⼀步步的调试了,只是想到这个函数的最后⼀条语句那个 |
demo 4
|
In [1]: def pdb_test(arg): ...: for i in range(arg): ...: print(i) ...: return arg ...: In [2]: #在python交互模式中,如果想要调试这个函数,那么可以 In [3]: #采⽤,pdb.run的⽅式,如下: In [4]: import pdb In [5]: pdb.run("pdb_test(10)") > <string>(1)<module>() (Pdb) s --Call-- > <ipython-input-1-ef4d08b8cc81>(1)pdb_test() -> def pdb_test(arg): (Pdb) l 1 -> def pdb_test(arg): 2 for i in range(arg): 3 print(i) 4 return arg [EOF] (Pdb) n > <ipython-input-1-ef4d08b8cc81>(2)pdb_test() -> for i in range(arg): (Pdb) l 1 def pdb_test(arg): 2 -> for i in range(arg): 3 print(i) 4 return arg [EOF] (Pdb) n > <ipython-input-1-ef4d08b8cc81>(3)pdb_test() -> print(i) (Pdb) |
0
> <ipython-input-1-ef4d08b8cc81>(2)pdb_test() -> for i in range(arg):
(Pdb)
> <ipython-input-1-ef4d08b8cc81>(3)pdb_test()
-> print(i)
(Pdb)
1
> <ipython-input-1-ef4d08b8cc81>(2)pdb_test() -> for i in range(arg):
(Pdb)
demo 5 运⾏过程中使⽤pdb修改变量的值
|
In [7]: pdb.run("pdb_test(1)") > <string>(1)<module>() (Pdb) s --Call-- > <ipython-input-1-ef4d08b8cc81>(1)pdb_test() -> def pdb_test(arg): (Pdb) a arg = 1 (Pdb) l 1 -> def pdb_test(arg): 2 for i in range(arg): 3 print(i) 4 return arg [EOF] (Pdb) !arg = 100 #!!!这⾥是修改变量的⽅法 (Pdb) n > <ipython-input-1-ef4d08b8cc81>(2)pdb_test() -> for i in range(arg): (Pdb) l 1 def pdb_test(arg): 2 -> for i in range(arg): 3 print(i) 4 return arg |
[EOF]
(Pdb) p arg
100
(Pdb)
练⼀练:请使⽤所学的pdb调试技巧对其进⾏调试出bug
|
#coding=utf-8 import pdb def add3Nums(a1,a2,a3): result = a1+a2+a3 return result def get3NumsAvarage(s1,s2): s3 = s1 + s2 + s1 result = 0 result = add3Nums(s1,s2,s3)/3 if __name__ == '__main__': a = 11 # pdb.set_trace() b = 12 final = get3NumsAvarage(a,b) print final |
pdb 调试有个明显的缺陷就是对于多线程,远程调试等⽀持得不够好,同时没有较为直观的界⾯显示,不太适合⼤型的 python 项⽬。⽽在较⼤的
python 项⽬中,这些调试需求⽐较常⻅,因此需要使⽤更为⾼级的调试⼯具。
编码⻛格
错误认知
这很浪费时间我是个艺术家
所有⼈都能穿的鞋不会合任何⼈的脚我善⻓制定编码规范正确认知
促进团队合作减少bug处理
提⾼可读性,降低维护成本有助于代码审查
养成习惯,有助于程序员⾃身的成⻓
pep8 编码规范
Python Enhancement Proposals :python改进⽅案 https://www.python.org/dev/peps/
pep8 官⽹规范地址
https://www.python.org/dev/peps/pep-0008/
Guido的关键点之⼀是:代码更多是⽤来读⽽不是写。编码规范旨在改善
Python代码的可读性。
⻛格指南强调⼀致性。项⽬、模块或函数保持⼀致都很重要。
每级缩进⽤4个空格。
括号中使⽤垂直隐式缩进或使⽤悬挂缩进。后者应该注意第⼀⾏要没有参数,后续⾏要有缩进。
Yes
|
# 对准左括号 foo = long_function_name(var_one, var_two, var_three, var_four) # 不对准左括号,但加多⼀层缩进,以和后⾯内容区别。 def long_function_name( var_one, var_two, var_three, var_four): print(var_one) # 悬挂缩进必须加多⼀层缩进. foo = long_function_name( var_one, var_two, var_three, var_four) |
No
|
# 不使⽤垂直对⻬时,第⼀⾏不能有参数。 foo = long_function_name(var_one, var_two, var_three, var_four) # 参数的缩进和后续内容缩进不能区别。 def long_function_name( var_one, var_two, var_three, var_four): print(var_one) |
4个空格的规则是对续⾏可选的。
# 悬挂缩进不⼀定是4个空格
foo = long_function_name(
|
var_one, var_two, var_three, var_four) if语句跨⾏时,两个字符关键字(⽐如if)加上⼀个空格,再加上左括号构成了很好的缩 # 没有额外缩进,不是很好看,个⼈不推荐. if (this_is_one_thing and that_is_another_thing): do_something() # 添加注释 if (this_is_one_thing and that_is_another_thing): # Since both conditions are true, we can frobnicate. do_something() # 额外添加缩进,推荐。 # Add some extra indentation on the conditional continuation lin if (this_is_one_thing and that_is_another_thing): do_something() |
右边括号也可以另起⼀⾏。有两种格式,建议第2种。
|
# 右括号不回退,个⼈不推荐 my_list = [ 1, 2, 3, 4, 5, 6, ] result = some_function_that_takes_arguments( 'a', 'b', 'c', 'd', 'e', 'f', ) # 右括号回退 my_list = [ 1, 2, 3, |
|
4, 5, 6, ] result = some_function_that_takes_arguments( 'a', 'b', 'c', 'd', 'e', 'f', ) |
空格或Tab?
空格是⾸选的缩进⽅法。
Tab仅仅在已经使⽤tab缩进的代码中为了保持⼀致性⽽使⽤。
Python 3中不允许混合使⽤Tab和空格缩进。
Python 2的包含空格与Tab和空格缩进的应该全部转为空格缩进。
最⼤⾏宽
限制所有⾏的最⼤⾏宽为79字符。
⽂本⻓块,⽐如⽂档字符串或注释,⾏⻓度应限制为72个字符。
空⾏
两⾏空⾏分割顶层函数和类的定义。
类的⽅法定义⽤单个空⾏分割。
额外的空⾏可以必要的时候⽤于分割不同的函数组,但是要尽量节约使
⽤。
额外的空⾏可以必要的时候在函数中⽤于分割不同的逻辑块,但是要尽量节约使⽤。
源⽂件编码
在核⼼Python发布的代码应该总是使⽤UTF-8(ASCII在Python 2)。
Python 3(默认UTF-8)不应有编码声明。
导⼊在单独⾏
Yes:
|
import os import sys from subprocess import Popen, PIPE |
No:
import sys, os
导⼊始终在⽂件的顶部,在模块注释和⽂档字符串之后,在模块全局变量和常量之前。
导⼊顺序如下:标准库进⼝,相关的第三⽅库,本地库。各组的导⼊之间要有空⾏。
禁⽌使⽤通配符导⼊。
通配符导⼊(from import *)应该避免,因为它不清楚命名空间有哪些名称存,混淆读者和许多⾃动化的⼯具。
字符串引⽤
Python中单引号字符串和双引号字符串都是相同的。注意尽量避免在字符串中的反斜杠以提⾼可读性。
根据PEP 257, 三个引号都使⽤双引号。
括号⾥边避免空格
# 括号⾥边避免空格
# Yes
spam(ham[1], {eggs: 2})
# No
spam( ham[ 1 ], { eggs: 2 } )
逗号,冒号,分号之前避免空格
# 逗号,冒号,分号之前避免空格
# Yes
if x == 4: print x, y; x, y = y, x
# No
if x == 4 : print x , y ; x , y = y , x
索引操作中的冒号当作操作符处理前后要有同样的空格(⼀个空格或者没有空格,个⼈建议是没有。)
|
# Yes ham[1:9], ham[1:9:3], ham[:9:3], ham[1::3], ham[1:9:] ham[lower:upper], ham[lower:upper:], ham[lower::step] ham[lower+offset : upper+offset] ham[: upper_fn(x) : step_fn(x)], ham[:: step_fn(x)] ham[lower + offset : upper + offset] # No ham[lower + offset:upper + offset] ham[1: 9], ham[1 :9], ham[1:9 :3] ham[lower : : upper] ham[ : upper] |
函数调⽤的左括号之前不能有空格
|
# Yes spam(1) dct['key'] = lst[index] # No spam (1) dct ['key'] = lst [index] |
赋值等操作符前后不能因为对⻬⽽添加多个空格
# Yes
|
x = 1 y = 2 long_variable = 3 # No x = 1 y = 2 long_variable = 3 |
⼆元运算符两边放置⼀个空格
涉及 =、符合操作符 ( += , -=等)、⽐较( == , < , > , != , <> , <= , >= , in , not in , is , is not )、布尔( and , or , not )。
优先级⾼的运算符或操作符的前后不建议有空格。
|
# Yes i = i + 1 submitted += 1 x = x*2 - 1 hypot2 = x*x + y*y c = (a+b) * (a-b) # No i=i+1 submitted +=1 x = x * 2 - 1 hypot2 = x * x + y * y c = (a + b) * (a - b) |
关键字参数和默认值参数的前后不要加空格
|
# Yes def complex(real, imag=0.0): return magic(r=real, i=imag) |
|
# No def complex(real, imag = 0.0): return magic(r = real, i = imag) |
通常不推荐复合语句(Compound statements: 多条语句写在同⼀⾏)。
|
# Yes if foo == 'blah': do_blah_thing() do_one() do_two() do_three() # No if foo == 'blah': do_blah_thing() do_one(); do_two(); do_three() |
尽管有时可以在if/for/while 的同⼀⾏跟⼀⼩段代码,但绝不要跟多个⼦句,并尽量避免换⾏。
|
# No if foo == 'blah': do_blah_thing() for x in lst: total += x while t < 10: t = delay() 更不是: # No if foo == 'blah': do_blah_thing() else: do_non_blah_thing() try: something() finally: cleanup() do_one(); do_two(); do_three(long, argument, list, like, this) |
if foo == 'blah': one(); two(); three()
避免采⽤的名字
决不要⽤字符'l'(⼩写字⺟el),'O'(⼤写字⺟oh),或 'I'(⼤写字⺟eye) 作为单个字符的变量名。⼀些字体中,这些字符不能与数字1和0区别。⽤'L' 代替'l'时。
包和模块名
模块名要简短,全部⽤⼩写字⺟,可使⽤下划线以提⾼可读性。包名和模块名类似,但不推荐使⽤下划线。