文章转载自:https://zhuanlan.zhihu.com/p/102331478
很多初学的小伙伴们,在学到“类”的时候,就开始烦迷糊了。“类”到底是个什么东西,是用来干嘛的?然后就疯狂百度搜索,搜出了很多。一看回答,很多都是在扯什么面向对象,还讲了一堆稀奇古怪的概念,看了反而更迷糊了。。
所以,我这篇文章,就是要带大家,用最简单、通俗、暴力的方式理解什么是类,类能干什么,怎么使用。
首先,我们要明白,既然python的作者设计了“类”这个东西,那肯定是在编程的时候有这种需求的。那我们什么时候需要用到类呢?当然,可以用到类的地方有很多很多。但如果大家还没有太多的代码经验,我就直接告诉你们答案了:如果多个函数需要反复使用同一组数据,使用类来处理,会很方便。
举个大家在中学都接触过的例子:解三角形。
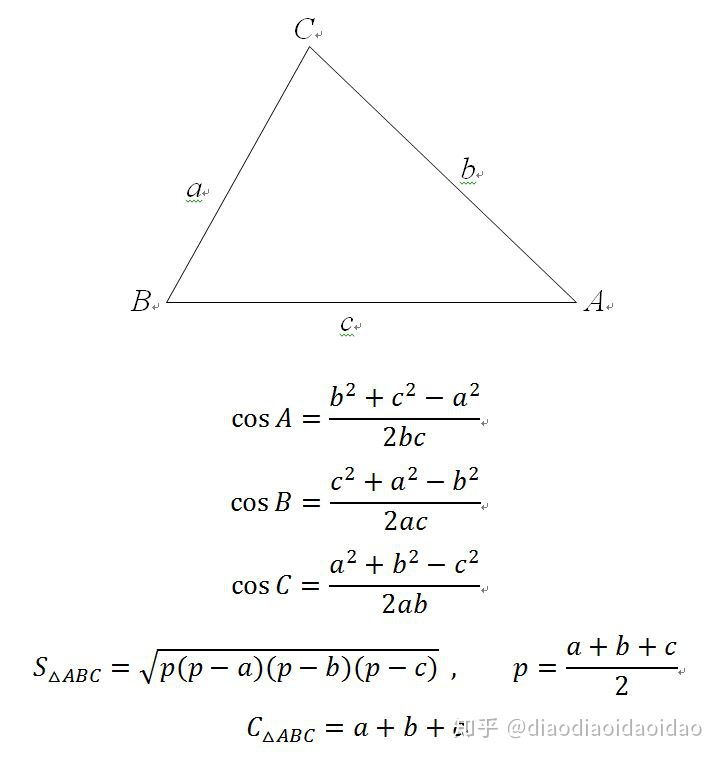
我需要做一个模块,实现以下功能:输入三角形的三条边长a,b,c,然后计算并返回该三角形三个角的角度,以及该三角形的面积、周长。
你会说,这很简单啊,我们一般就这么做就行了,假如输入三角形的边长为6,7,8:
1 def ...: # 参照公式把五个函数定义出来,就不详细写了 2 ... 3 def ...: 4 ... 5 6 # 然后调用定义好的函数,传入边长数据 7 angleA(6,7,8) # 计算角A 8 ->0.8127555613686607 # 注意返回值为弧度 9 10 angleB(6,7,8) # 计算角B 11 ->1.0107210205683146 12 13 angleC(6,7,8) # 计算角C 14 ->1.318116071652818 15 16 square(6,7,8) # 计算面积 17 ->20.33316256758894 18 19 circle(6,7,7) # 计算周长,额,好像有个数字写错了 20 ->20 # 计算结果当然也就错了
这不就搞定了嘛,把计算需要用到的五个函数依次定义出来,然后调就好了。但大家仔细观察一下,这样写有什么不太好的地方?相信大家都发现了,这是同一个三角形,每次计算角度、面积、周长的时候,都要把三条边的长度传进去,一方面这很麻烦,另一方面,万一有一个不小心写错了,那么那条结果当然也就错了啊。
我们根据三角形全等的条件可以知道,三角形的三条边确定了,那么它的三个角、面积、周长,也就都确定了。所以对于同一个三角形,最好只需要传一次数据就可以了。
这不也简单嘛,把它们都写在一个函数里不就得了:
1 def calculate(a,b,c): 2 angleA = ... 3 angleB = ... 4 angleC = ... 5 square = ... 6 circle = ... 7 return {'角A':angleA, '角B':angleB, '角C':angleC, '面积':square, '周长':circle} 8 9 result=calculate(6,7,8) 10 11 result['角A'] 12 ->0.8127555613686607 13 14 result['面积'] 15 ->20.33316256758894
好了,这不又搞定了,看起来没什么问题了吧。看起来当然没有问题了,但大家再仔细想一想,假如我只需要计算“角A”和“面积”,用上面的方法,也只返回了这两个结果,但实际上,那个函数在执行的时候,实际上把五个值都求了一遍。数量少还好,但数量多起来,效率肯定就要大受影响了。
这怎么办呢?聪明的你可能又想到了,在函数里加入第四个参数d,用来标记需要计算哪个,然后函数中插入if语句判断……
得,代码我也不想写了,原来很清晰的逻辑,非得糟蹋成这样。。
这又要使用简便,又要效率高,还要逻辑清晰,这可怎么办呢?我们了想又想,认为函数还是要分开来写的。但我们脑洞一下,最好有一个“大的东西”叫“三角形生成器”,把这些函数包括进来。使用的时候参数直接传给三角形生成器,然后三角形生成器会根据传入的边长生成一个个具体的三角形,生成的三角形除了具有输入进来的边长数据外,还可以自己计算自己的三个角、面积、周长。也就是,我们希望能够实现以下的效果:
1 # 定义一个“大的东西”,名字就叫triangle 2 ... 3 ... 4 # 一番神奇的操作,然后 5 6 tr1=triangle(6,7,8) # 把三条边长传给这个大的东西,然后就生成一个三角形赋给tr1
在这行代码里,我们把边长数值传给了“三角形生成器”triangle(),生成了一个三角形,然后赋值给变量tr1。此时的tr1,就代表着边长为6,7,8的具体三角形。
然后,我们可以很方便地查看这个三角形三边的边长(也就是刚才传进来的数据):
1 tr1.a 2 ->6 3 4 tr1.b 5 ->7 6 7 tr1.c 8 ->8
计算并查看三个角的角度:
1 tr1.angleA() 2 ->0.8127555613686607 3 4 tr1.angleB() 5 ->1.0107210205683146 6 7 tr1.angleC() 8 ->1.318116071652818
计算并查看它的面积与周长:
1 tr1.square() 2 ->20.33316256758894 3 4 tr1.circle() 5 ->21
又来了一个边长为8,9,10的三角形:
tr2=triangle(8,9,10) # 生成另外一个三角形
计算这两个三角形的面积差:
1 tr2.square()-tr1.square() # tr2是新生成的三角形,原来的tr1还在呢没删掉 2 ->13.863876777945055
这种想法很大胆是不是?可应该怎么实现呢?这就要用到类了。
可大家在反思一下,这种想法真的很smart吗?在python中,万物皆对象,我们操作字符串、列表、字典、文件IO等内置对象的时候,用的方法,看起来不是一模一样吗。。只不过那个“三角形”是我们自创的而已。讲到这里,你也许已经明白了,类,其实就是提供了自定义对象的能力。
好了,不多讲了,我们把上面那个“一番神奇的操作”展开看看吧。
1 import math # 计算反三角函数要用到 2 3 class triangle: # 定义类:三角形生成器 4 def __init__(self,a,b,c): # 成员函数,声明需要与外部交互的参数(类的属性) 5 self.a=a # 先看着 6 self.b=b # 这几个东西是干嘛的后面会讲 7 self.c=c 8 9 def angleA(self): # 计算函数(类的方法) 10 agA=math.acos((self.b**2+self.c**2-self.a**2)/(2*self.b*self.c)) 11 return agA 12 13 def angleB(self): # 公式看不懂的回去翻课本去 14 agB=math.acos((self.c**2+self.a**2-self.b**2)/(2*self.a*self.c)) 15 return agB 16 17 def angleC(self): 18 agC=math.acos((self.a**2+self.b**2-self.c**2)/(2*self.a*self.b)) 19 return agC 20 21 def square(self): 22 p=(self.a+self.b+self.c)/2 23 s=math.sqrt(p*(p-self.a)*(p-self.b)*(p-self.c)) 24 return s 25 26 def circle(self): 27 cz=self.a+self.b+self.c 28 return cz
其实也简单,就是先声明包含的参数,然后再写包含的函数就行了。具体的写法规则很多文档都有介绍,我就不多讲了。
用的时候也简单,既然类是自定级对象的规则,那我们就先传入数据,根据规则生成具体的对象(称之为实例化):
1 tr1=triangle(6,7,8)
像这个,就是根据三角形的生成规则,传入的三条边长,生成的具体三角形,然后那些边长啊、角度啊、面积啊才会有意义。
1 print(tr1.a) 2 print(tr1.b) 3 print(tr1.c) 4 print(tr1.angleA()) 5 print(tr1.angleB()) 6 print(tr1.angleC()) 7 print(tr1.square()) 8 print(tr1.circle()) 9 10 -> 11 6 12 7 13 8 14 0.8127555613686607 15 1.0107210205683146 16 1.318116071652818 17 20.33316256758894 18 21
总结一下,所有的对象,不管是python内置的,还是import第三方包里面的,还是我们自己用类定义然后实例化的,观察总结一下,可以发现,它们都是由两部分组成,一部分是像a、b、c这样的数据,它们决定这个对象是什么,另一部分是像angleA()、angleB()、angleC()这样的函数,他们用来表示用这些数据做什么。在面向对象的编程中,一个对象的数据,称之为对象的属性,一个对象拥有的函数,称之为对象的方法。大家可能经常听说这两个名词,哪怕是其他的编程语言,面向对象作为一种思想,都是相通的。
然后大家可能还有几个问题:
第一个函数def __init()__是干什么的?
顾名思义,init是初始化的意思,init函数,也就是初始化函数,意思就是,当实例化类的时候,自动运行的函数,如果我们实例化的时候给类传了参数,参数也是呈交给这个函数来处理的。所以,你可以在init函数里写上任何你希望实例化的时候就自动执行的函数,比如像print('实例化已完成')什么的都是可以的。
但大部分时候,我们希望实例化的时候干些啥?当然是把数据传给类的属性啊,所以绝大部分情况下,init函数都充当了构造函数的作用,我们可以在这里面写明把传来的数据赋予谁,或经过怎样的预处理后再赋予谁。
就拿那个三角形来说,我们希望在生成三角形(实例化)的时候,就给三角形生成器(类)传入三条边长,而不是实例化完了之后,再tr1.a=6,tr1.b=7这样的一个个赋值。所以我们直接就在init函数里写明了参数的传递规则。
另外再说一句,在传入参数实例化后,除了可以查看,也是可以再次修改的:
1 tr1.a 2 ->6 3 4 tr1.a=7 5 tr1.a 6 ->7
那个self是什么东西,为什么要写self.a?
我们在使用对象的属性的时候,写法是“对象名.属性名”,就像上面的tr1.a。在定义类的时候,为了保持一致,也要采用这种写法。但由于类定义的时候,还没有实例化,并不清楚对象名是什么,所以可以随便写一个(但要前后一致),一般都写self。
看完这篇文章,知道类是什么了吧,然后再去搜索那些你想要的资料,就能看明白了。