6. 学习模型的评估与选择
Content
6. 学习模型的评估与选择
6.1 如何调试学习算法
6.2 评估假设函数(Evaluating a hypothesis)
6.3 模型选择与训练/验证/测试集(Model selection and training/validation/test sets)
6.4 偏差与方差
6.4.1 Diagnosing bias vs. variance.
6.4.2 正则化与偏差/方差(Regularization and bias/variance)
6.5 学习曲线(Learning Curves)
6.6 调试学习算法
我们已经学习了许多有用的学习模型(线性回归,Logistic回归,神经网络),但是当要解决一个实际问题时,以下问题是我们要考虑的:
-
如何知道我们所设计的模型是有用的或者较好的?
-
当模型应用的不理想时,我们应该从哪些方面进行改进?
-
如何针对具体问题选择学习模型?
下面将针对上述问题提出建议。
6.1 如何调试学习算法
现在假设我们已经实现了如下的一个正则化的线性回归模型用于预测房价
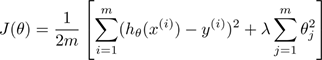
根据已有的训练集,我们已经将该模型训练完毕。但是,当我们需要在新的数据集上进行房价的预测时,发现预测的结果和实际有很大的误差。下面我们应该做什么?我们可以从下面的一些角度考虑:
-
获取更多的数据量
- 有时数据量大并没有帮助
-
通常数据量越大,学习模型训练得越好,但是即使这样,也应该做一些初步实验(见6.5节 学习曲线)来确保数据量越大,训练越好。(如果一开始就用大量的数据来训练模型,将会耗费大量的时间:收集数据,训练模型)
-
减少特征量
-
细心的从已有的特征量中选出一个子集
-
可以手工选择,也可以用一些降维( dimensionality reduction)技术
-
-
增加额外的特征量
-
有时并不起作用
-
仔细考虑数据集,是否遗漏了一些重要的特征量(可能花费较多的时间)
-
添加的特征量可能只是训练集的特征,不适合全体数据集,可能会过拟合
-
-
添加多项式的特征量
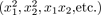
-
减少正则化参数
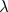
-
增加正则化参数
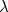
可以发现,我们似乎有很多种方法来改善学习模型,但是,有些方法可能要花费很多时间(或许还不起作用),有些方法可能是矛盾的。所以,需要一种方式来给我们指明方向:到底应该采用哪种或哪些方式来优化模型。我们将这种方式称为机器学习诊断(Machine Learning Diagnostics)。机器学习诊断是一种测试法,能够深入了解某种算法到底是否有用。这通常也能够告诉我们,要想改进一种算法的效果,什么样的尝试才是有意义的,从而节省时间,减少不必要的尝试。
6.2 评估假设函数(Evaluating a hypothesis)
当我们确定学习算法的参数的时候,我们考虑的是选择使训练误差最小化的参数。但我们已经知道(见3.1 underfitting and overfitting ),仅仅是因为这个假设具有很小的训练误差,并不能说明它就一定是一个好的假设函数,可能该假设函数会过拟合,泛化能力弱。
该如何判断一个假设函数是过拟合的呢?对于简单的例子,可以对假设函数 h(x) 进行画图 然后观察图形趋势。但是,特征量较多时(大于2),画图就很难实现。因此,我们需要另一种方法来评估我们的假设函数。如下给出了一种评估假设函数的标准方法:
假设我们有这样一组数据组(如图6-1),我们要做的是将这些数据分成两部分: 训练集和测试集。一种典型的分割方法是按照7:3的比例,将70%的数据作为训练集,30%的数据作为测试集。这里默认原有数据集是无序的(随机的),所以我们选择前70%作为训练集,后30%作为测试集,但如果原数据集是有序的,我们应该随机选择出7:3的数据集分别作为训练集和测试集。
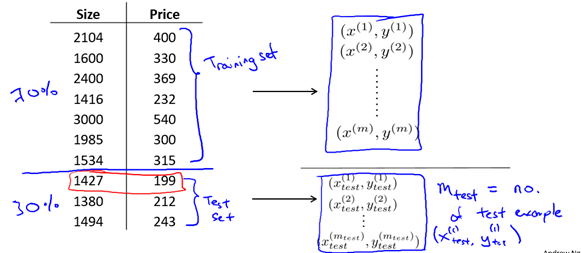
图6-1 大小为10的数据集及其划分
因此,典型的训练和测试方案如下:
-
用70%划分得到的训练集来训练模型:即最小化J(θ)
-
计算训练后的模型在测试集上的误差(test set error)。

其中Jtest(θ) 为测试集上的平均平方误差(average square error),mtest为测试集的大小。
如果我们使用线性回归,test set error 则为
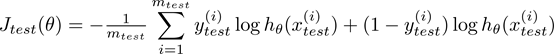
另一种定义Logistics回归的误差是误分类率(misclassification error)或称0/1错分率(0/1 misclassification).
-
定义error function

-
Test error is
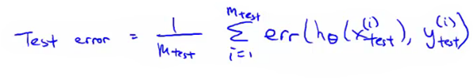
6.3 模型选择与训练/验证/测试集(Model selection and training/validation/test sets)
如何选择正则化参数的大小和多项式的次数是常常面临的问题,称之为模型选择问题。我们已经多次接触到过拟合现象,在过拟合的情况中,参数非常拟合训练集,那么模型对于相同数据组预测集的预测误差不能够用来推广到一般情况的,即是不能作为实际的泛化误差。也就是不能说明你的假设对于新样本的效果。
下面我们来考虑模型选择问题,假如要选择能最好地拟合数据的多项式次数,具体地,我们在次数为1到10之间应该如何做出选择。
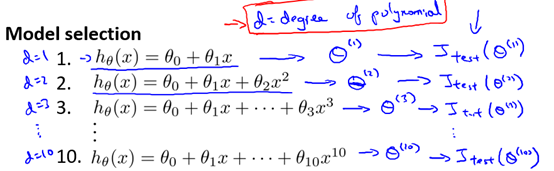
d表示应该选择的多项式次数。所以,似乎除了要确定的参数θ之外,我们同样需要用数据集来确定这个多项式的次数d。
- d =1 (linear)
- d=2 (quadratic)
- ...
- d=10
那么我们可以这样做:
-
选择第一个模型(d = 1),然后求训练误差的最小值,得到一个参数向量θ1
-
选择第二个模型(d = 2), 二次函数模型, 进行同样的过程, 得到另一个参数向量θ2
以此类推,最后得到θ10
接下来对所有这些模型,求出测试集误差
- Jtest(θ1)
- Jtest(θ2)
- ...
- Jtest(θ10)
接下来为了确定选择哪一个模型最好,即哪一个对应的测试集误差最小。对于这个例子,我们假设最终选择了五次多项式模型。
确定模型后,现在我们想知道,这个模型能不能很好地推广到新样本。我们可以观察这个五次多项式假设模型对测试集的拟合情况,但这里有一个问题是:这样做仍然不能公平地说明,我的假设推广到一般时的效果。其原因在于,我们刚才是使用的测试集和假设拟合来得到的多项式次数d 这个参数,这也就是说,我们选择了一个能够最好地拟合测试集的参数d的值。因此,我们的参数向量θ5在拟合测试集时的结果很可能导致一个比实际泛化误差更完美的预测结果。换言之,我们是找了一个最能拟合测试集的参数d,因此我再用测试集来评价我们的模型就显得不公平了。
为了解决这一问题,在模型选择中,如果我们想要评价某个假设,我们通常采用以下的方法:给定某个数据集,和刚才将数据分为训练和测试集不同的是,我们要将其分为三段:
- 训练集 Training set (60%) - m values
- 交叉检验集 Cross validation (CV) set (20%)mcv
- 测试集 Test set (20%) mtest
我们随之也可以定义训练误差,交叉验证误差和测试误差如下:

因此,我们按如下方式选择模型:
1. Minimize cost function for each of the models as before
2. Test these hypothesis on the cross validation set to generate the cross validation error
3. Pick the hypothesis with the lowest cross validation error. e.g. pick θ5
4. Finally,Estimate generalization error of model using the test set
值得注意的是,在如今的机器学习应用中, 也有很多人是用测试集来选择模型, 然后又同样的测试集来评价模型的表现报告测试误差,看起来好像还能得到比较不错的泛化误差。如果有很多很多测试集的话,这也许还能行得通,否则得到的测试误差很大程度要比实际的泛化误差好。因此最佳做法还是把数据分成训练集、验证集、测试集。
6.4 偏差与方差
6.4.1 Diagnosing bias vs. variance
如图6-2,当运行一个学习算法时,如果这个算法的表现不理想,那么多半是出现两种情况,要么是偏差比较大(欠拟合),要么是方差比较大(过拟合),能判断出现的情况是这两种情况中的哪一种非常重要,因为它是一个很有效的指示器,告诉我们可以改进算法的最有效的方法和途径。
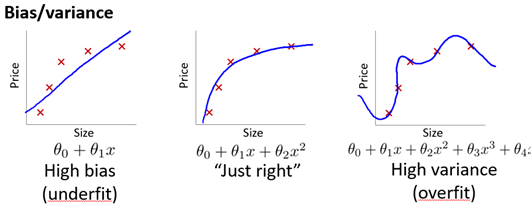
图6-2 不同模型的拟合情况
现在我们已经掌握了训练集,验证集和测试集的概念。我们就能更好地理解偏差和方差的问题。具体来说,我们沿用之前所使用的训练集误差和验证集误差的定义也就是平方误差,画出图6-3.
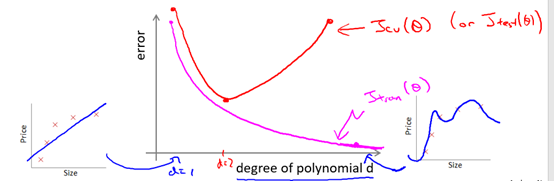
图6-3 多项式次数与误差的关系
d等于1是用线性函数来进行拟合,而在最右边的这个图表示更高次数的多项式的拟合情况。随着我们增大多项式的次数,我们将对训练集拟合得越来越好,所以如果d等于1时 对应着一个比较大的训练误差,而如果我们的多项式次数很高时 我们的训练误差就会很小 甚至可能等于0 因为可能非常拟合训练集。所以,当我们增大多项式次数时,我们不难发现训练误差明显下降。
接下来我们再看交叉验证误差,如果d等于1,意味着用一个很简单的函数来拟合数据,此时我们不能很好地拟合训练集(欠拟合),我们会得到一个较大的交叉验证误差,而如果我们用一个中等大小的多项式次数来拟合时,如d等于2,那么我们会得到一个更小的交叉验证误差,因为我们找了一个能够更好拟合数据的次数。但是,如果次数d太大,比如说d的值取为4 ,那么我们又过拟合了,我们又会得到一个较大的交叉验证误差。
具体来说 假设我们得出了一个学习算法,而这个算法并没有表现地如期望那么好,我们应该判断此时的学习算法是正处于高偏差的问题还是高方差的问题。
-
当训练误差和交叉验证误差相近且都比较大时,即对应图6-3曲线中的左端,对应的就是高偏差的问题
-
相反地,当训练误差较小而交叉验证误差远大于训练误差时,即对应图6-3曲线右端,对应的是高方差的问题
6.4.2 正则化与偏差/方差(Regularization and bias/variance )
我们知道,算法正则化可以有效地防止过拟合。但正则化跟算法的偏差和方差又有什么关系呢?对于如下正则化的线性回归模型

我们分析以下三种情形:
-
第一种情形是正则化参数λ取一个比较大的值,如等于10000,此时,所有这些参数θ将被大大惩罚,其结果是这些参数的值将近似等于0 并且假设模型 h(x) 的值将等于或者近似等于
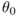 。因此我们最终得到的假设函数应该近似是一条平滑的直线(如图6-4-(1)),因此这个假设处于高偏差,对数据集欠拟合(underfit)。
。因此我们最终得到的假设函数应该近似是一条平滑的直线(如图6-4-(1)),因此这个假设处于高偏差,对数据集欠拟合(underfit)。 -
与之对应的另一种情况是λ值很小,比如λ=0,这种情况下,如果我们要拟合一个高阶多项式,通常会处于高方差和过拟合(overfitting)的情况(如图6-4-(3))。因为λ的值等于0相当于没有正则化项 因此会对假设过拟合。
-
如图6-4-(2),只有λ取不大不小的值时,才会得到一组对数据刚好拟合的参数值θ。
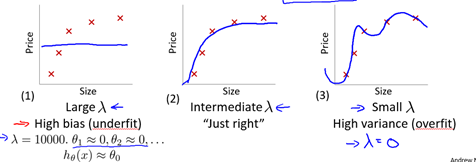
图6-4 不同λ取值的拟合情况
现在我们可以按照如下方式选择出一个最合适的正则化参数 λ:
- 确定λ可能的取值向量,通常为[0,0.01,0.02,0.04,0.08,… ,10.24]
- 每一个λ的可能取值对应一个模型,对每一个模型进行训练,使代价函数
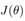 最小,得到对应的参数θ。
最小,得到对应的参数θ。 - 对于每个训练后的模型,计算出其在交叉检验集上的误差

- 取使
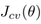 最小的模型作为我们的模型,并将其应用于测试集,得到测试误差
最小的模型作为我们的模型,并将其应用于测试集,得到测试误差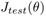 ,并以此估计泛化误差。
,并以此估计泛化误差。
其中:

与多项式次数与误差类似,我们可以画出λ与误差的函数关系,如图6-5所示
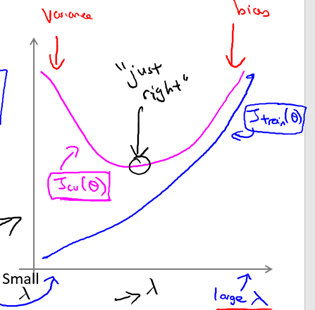
图6-5 λ与误差的关系
6.5 学习曲线(Learning Curves)
有时我们需要检查学习算法运行是否一切正常,或者希望改进算法的表现或效果,那么学习曲线(Learning Curves)就是一种很好的工具。并且,我们可以使用学习曲线来判断某一个学习算法是否处于偏差,方差问题或是二者皆有。下面我们就来介绍学习曲线。
学习曲线和图6-5类似,它们的区别在于学习曲线是以训练集的大小m为横坐标。纵坐标仍然是训练集误差Jtrain和交叉检验误差Jcv。
一般情况下的学习曲线如图6-7所示:
-
对于训练集误差而言,m越小,越容易拟合,误差越小,换言之,Jtrain随m的增大而增大。
-
对于交叉检验误差而言,m越小,模型的泛化能力越弱,故误差越大,换言之,Jcv随m的增大而减小。
-
当m大到一定程度时,训练集误差和交叉检验误差较接近且都比较小。
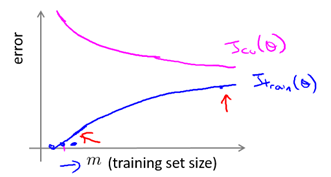
图6-7 一般情况下的学习曲线
当学习算法是高偏差时,如图6-8所示,此时:
-
对于训练集误差而言,当m很小时,误差很小,但由于它不能很好的拟合训练集,随后就会增长较快,达到一个较稳定的值。
-
对于交叉检验误差而言,当m很小时,算法的泛化能力非常弱,误差很大,随着m的增加,泛化能力稍有提升,误差会有所减小,但由于学习算法本身对训练集误差较大,故交叉检验误差不会下降太多,最后稳定在一个较高的值。
-
在m不太大时,训练集误差就和交叉检验误差接近,但都比较大。
所以,在高偏差的情况下,增大训练集往往不起作用。
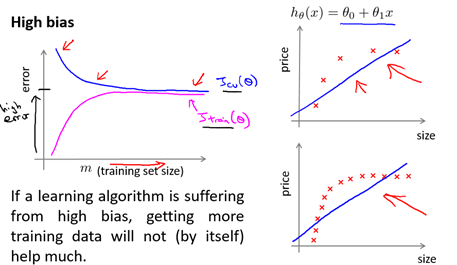
图6-8 高偏差时的学习曲线
当学习算法是高方差时,如图6-9所示,此时:
-
对于训练集误差而言,当m很小时,误差很小,并且由于算法能很好的拟合训练集(过拟合),随着m的增加,误差只有少量增加(增加很慢)。
-
对于交叉检验误差而言,当m很小时,算法的泛化能力非常弱,误差很大,随着m的增加,泛化能力稍有提升,误差会有所减小,但由于学习算法过拟合,泛化能力有限,故交叉检验误差不会下降太多,最后稳定在一个较高的值。
-
在m较大时,训练集误差和交叉检验误差也有一定的差距,此时训练集误差较小,而交叉检验集误差较大。
所以,在高方差的情况下,增大训练集通常是有效的(减少过拟合)。
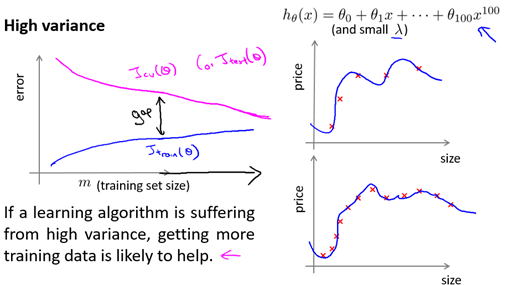
图6-9 高方差时的学习曲线
6.6 调试学习算法
经过了上面的分析,现在我们对调试学习算法的策略进行总结
-
Get more training examples --> helps to fix high variance
-
Not good if you have high bias
-
-
Smaller set of features --> fixes high variance (overfitting)
-
Not good if you have high bias
-
-
Try adding additional features --> fixes high bias (because hypothesis is too simple, make hypothesis more specific)
-
Add polynomial terms --> fixes high bias problem
-
Decreasing λ --> fixes high bias
-
Increases λ --> fixes high variance
对于神经网络而言,我们需要针对不同的问题设计不同的网络结构,通常从下面两种角度考虑:
-
选择一个较小的网络
-
较少的隐藏层(如1层)和较少的隐藏单元,适用于变量(特征量)较少的情况
-
可能欠拟合,但计算代价较小
-
-
选择一个较大的网络
-
更多的隐藏层-需要我们决定具体是多少层较好
-
适用于变量较多的情况,
-
可能会过拟合,需要使用正则化来削弱过拟合
-
计算代价更大
-
通常而言,选择一层隐藏层或许是比较好的选择。当然,在应用神经网路时也应将已有数据集划分为训练集,交叉检验集和测试集。