本文主要内容来自于《Hadoop权威指南》英文版中的Spark章节,能够说是个人的翻译版本号,涵盖了基本的Spark概念。假设想获得更好地阅读体验,能够訪问这里.
安装Spark
首先从spark官网下载稳定的二进制分发版本号,注意与你安装的Hadoop版本号相匹配:
wget http://archive.apache.org/dist/spark/spark-1.6.0/spark-1.6.0-bin-hadoop2.6.tgz解压:
tar xzf spark-x.y.z-bin-distro.tgz为了方便执行,将bin文件夹增加到PATH中:
export SPARK_HOME=/home/spark/
export PATH=$PATH:$SPARK_HOME/bin完毕。
简单样例
Spark提供了交互式的Spark-shell。这是入门的好起点。
spark-shell是基于Scala REPL的交互式工具。
启动shell:
spark-shell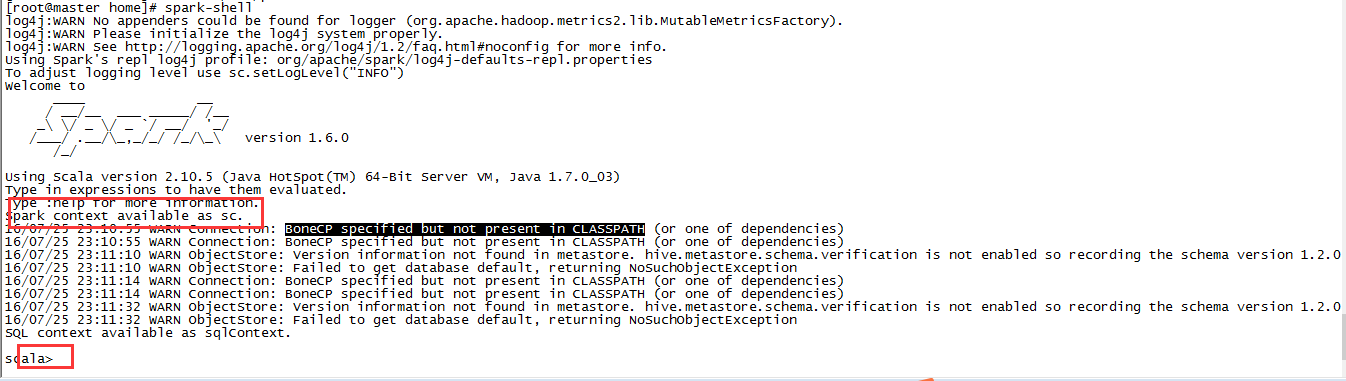
从输出中我们能够看到。shell创建了一个Scala变量,存放的是SparkContext的实例。
我们使用sc载入一个文本文件:
val lines = sc.textFile("input/ncdc/sample.txt") 
lines变量引用的是一个RDD对象(Resilient Distributed Dataset)。RDD是Spark最核心的抽象。它是一个(通过分区。partitioned)分布在集群多台机器上的仅仅读对象集合。
在一个典型的Spark应用程序中,一个或者多个RDD被载入作为输入。经过一系列的转化(transformation)之后变成目标RDD集合。然后一个动作(action)作用于这些RDD上,比如计算结果或者保存到持久化介质中。
RDD中的resilient是指:当一个RDD分区(partition)丢失之后。Spark会自己主动从其原始的RDD又一次计算。载入RDD或者在RDD上调用transformation时,并没有触发真正的处理过程,Spark仅仅是创建执行的计划。
仅仅有当action作用域RDD时,才会触发真正的数据处理,比如执行foreach().
接着前面载入的数据,拿到lines之后。我们想要把每一行的字段进行切分:
val records = lines.map( _.split(" "))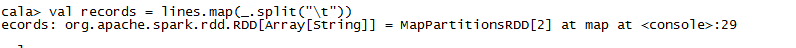
map方法将一个函数作用在RDD中的每一个元素上,这个样例中,split把每一行(RDD[String])转变成一个Scala的字符串数组(RDD[Array[String]])。
移除脏数据:
val filtered = records.filter( rec => (rec(1) !="9999" && rec(2).match("[01459]")))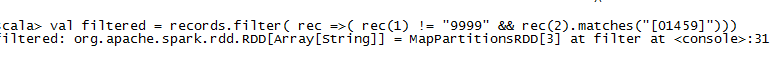
filer针对RDD中的每一个元素执行一个predicate推断,传入的是一个返回Boolean类型的函数,Scala中数组的訪问訪问是通过()操作。
这里主要是过滤到脏数据。
为了找到每一年的最高温度。我们须要执行一个分组操作,Spark提供了reduceByKey的操作,可是仅仅能应用在key-value类型的RDD(使用Scala的Tuple2来表示)上面,因此须要先做一次转换:
val tuples = filtered.map(rec => (rec(0).toInt,rec(1).toInt))
通过map操作来完毕。将字符串素组转化为Int二元组,scala中调用方法时假设没有參数能够省略不写括号。
转换之后我们就能够进行聚合操作:
val maxTemps = tuples.reduceByKey((a,b)=> Math.max(a,b))
reduceByKey接受一个函数。这个函数将一对值合并为一个值,然后不断应用在key相应的全部值上。假设1950这个key相应的记录有:
(1950,20) // 1
(1950,19) // 2
(1950,22) // 3reduceByKey操作会把max函数应用到1和2身上,即执行max(20,19),得到20,然后再把20跟第三条记录对照。得到终于的22. 我们把结果输出:
maxTemps.foreach(println(_))foreach是个action操作,针对RDD中的每一个元素应用println(_)这个函数。这时候才会触发整个RDD链条执行计算,输出结果到控制台:
(1950,22)
(1949,111)我们也能够把计算结果保存到磁盘中:
maxTemps.saveAsTextFile("output")查看输出文件:
cat output/part-*Spark Applications,JObs,Stages , and Tasks
Spark中也有一些核心的概念。相似于MapReduce,Spark也有作业(job)的概念,可是更为通用一些,作业由随意的stage 有向无环图(DAG)组成,stage有点相似于MapReduce中的map或reduce阶段(phase)。
Spark执行时将Stage进一步被拆分为task,并在分布于集群上的RDD partitions并行执行。作业总是执行于Application的上下文中,这个上下文通过SparkContext来表示,用于组织相关的RDD和共享变量。一个Application能够并行或串行执行多个Job。
Application提供了一种在同一个应用中共享数据集的机制,前面执行的作业能够将数据集缓存。兴许的作业能够直接訪问这些缓存的RDD。这与MapReduce中每一个作业都须要从磁盘中读取输入数据是不同的。交互式的Spark会话如Spark-shell就是一个应用实例。
一个Scala应用程序
spark-shell提供了一种探索和学习Spark非常好的方式。可是实际中常常须要将业务逻辑作为一个自包括的、完整的应用打包在一起,能够多次执行。以下是一个Scala应用的样例:
import org.apache.spark.SparkContext._
import org.apche.spark.{SparkContext,SparkConf}
object MaxxTemperature{
def main(agrs: Array[String]) {
val conf = new SparkConf().setAppName("Max Temperature")
val sc = new SparkContext(conf)
sc.textFile(agrs[0]))
.map(_.split(" "))
.filter(rec => (rec(1) != "9999" && rec(2).match("[01459]")))
.map(rec => (rec(0).toInt , rec(1).toInt))
.reduceByKey( (a,b) => Math.max(a,b))
.saveAsTextFile(args(1))
}
}当作为一个独立的应用时,我们须要自己创建SparkContext,由于没有shell提供这个对象给我们。SparkConf用于配置应用的各个属性,这里我们仅仅设置了应用名称。
Spark中的转换(Transformation)大多数在RDD这个类中定义,可是这个样例中的reduceByKey()其实是在PairRDDFunctions类中定义的,我们之所以不须要显式转换。是由于有以下的导入语句:
import org.apache.spark.SparkContext._这个语句导入了Spark中各种隐式转换的函数,这个导入在编写应用的时候非常有用。
完毕这个简单应用的编写之后。我们使用spark-submit来执行程序:
spark-submit --class MaxTemperature --master local spark-examples.jar input/ncdc/sample.txt output/max-tempspark-submit相似于Hadoop中的hadoop jar命令,class參数指定了执行Main入口,master指定执行模式,local模式下全部组件都执行在一个JVM中,spark-examples.jar包括编译过的应用程序代码,后面是输入和输出參数。
Java样例
Spark使用基于JVM的语言Scala。能够非常好地与Java集成。Spark提供的Java API中,RDD使用类JavaRDD封装,JavaPairRDD用于特殊的key-value RDD。这两个类都事先了JavaRDDLike接口。RDD的大部分操作方法都在这个接口中定义。
上述的逻辑使用Java来表达例如以下:
public class MaxTemperatureSpark {
public static void main(String[] args) throws Exception {
if (ages.length != 2){
System.err.println("Usage: MaxTemperaturSpark <input path> <output path>");
System.exit(-1);
}
SparkConf conf = new SparkConf();
JavaSparkContext sc = new JavaSparkContext("local","Max TemperaturSpark",conf);
JavaRDD<String> lines = sc.textFile(args[0]);
JavaRDD<String[]> records = lines.map( new Function<String , String[]>(){
@Override
public String[] call(String s){
return s.split(" ");
}
});
JavaRDD<String[]> filtered = records.filter(new Function<String[],Boolean>(){
@Override
public Boolean call(String[] rec){
return rec[1] != "9999" && rec[2].matches("[01459]");
}
});
JavaPairRDD<Integer,Integer> tuples = filtered.mapToPair(
new PairFunction<String[],Integer,Integer>(){
@Override
public Tuple2<Integer,Integer> call(String[] rec) {
return new Tuple2<Integer,Integer> ( Integer.parseInt(rec[0]),Integer.parseInd(rec[1]));
}
} );
JavaPairRDD<Integer,Integer> maxTemps = tuples.reduceByKey(
new Function2<Integer,Integer,Integer>(){
@Override
public Integer call (Integer i1 , Integer i2){
return Math.max(i1,i2);
}
}
);
maxTemps.saveAsTextFile(agrs[1]);
}
}能够看到代码非常冗长,Java在处理函数式的代码的确非常不给力。
实现逻辑非常简单,就是不断对RDD做转换,转换的逻辑大多通过各阶的函数来表示,比如Function。Function2。PairFunction等。另外静态类型的特点也要求我们在定义每一个RDD都要指定其泛型类型。没有了Scala中的隐式转换。因此从String数组RDD到PairRDD也须要我们自己动手。
编译这个类,然后使用spark-submit提交。格式与Scala版本号全然一样。除了类名变了。
Python样例
Spark也提供了Python的API,一般叫PySpark。通过使用Python中的lambda表达式。Python写出来的代码和Scala非常相似,比較紧凑。
from pyspark import SparkContext
import re ,sys
sc = SparkContext("local","Max Temperature")
sc.textFile(sys.argv[1])
.map( lambda s: s.split(" "))
.filter(lambda rec : (rec[1]!="9999" and re.match("[01459]" ,rec[2])))
.map(lambda rec: (int(rec[0]),int(rec[1])))
.reduceByKey(max)
.saveAsTextFile(sys.argv[2])非常好,代码非常紧凑,參数通过sys.argv传入,下标从1開始而不是0. 转换逻辑通过lambda来表达,正则匹配用了re模块。reduce的时候用了python内置的max函数。
Python代码执行时,Spark会fork出子线程来执行这些用户代码。在启动程序(launcher program)和executor中都会fork子进程。
两个进程之间使用socket通信,全部父进程能够把RDD Partition的数据传递给Python代码。
执行Python版本号时。我们制定的是Python文件而不是jar包:
spark-submit --master local
src/python/MaxTemperature.py
input/ncdn/sample.txt output另外。使用pyspark命令也能够启动Python版的交互式REPL。
RDD
RDD是Spark应用中最核心的部分。接下来看一些RDD相关的内容。
创建RDD
有3种能够创建RDD:
1. 从内存中的对象集合创建(parallelism collection)
2. 从外部存储文件创建(如HDFS)
3. 从其它已存在的RDD转换而来
第1种方式适合内存不敏感的少量数据进行操作。
比如以下代码对1-10的整数进行处理:
val params = sc.parallelize( 1 to 10)
val results = params.map(doSomethingExpensive)doSomethingExpensive函数在params上的每一个元素并行计算,并行度由spark.default.parallelism參数指定,默认情况下,假设在local模式执行。该值为机器的CPU核数。假设执行在集群环境中,该值为集群中属于该应用的executor拥有的CPU总核数。
假设我们不想使用默认的并行度。能够在parallelize方法传入第二个參数指定,以下的代码指定并行度为10:
val params = sc.parallelize(1 to 10 , 10)第2种方法通过创建对外部数据的引用来创建RDD:
val text:RDD[String] = sc.textFile("hdfs-path")路径參数必须是Hadoop文件系统的的文件路径。比如本地文件路径。HDFS文件路径,或者HDFS暴露的web接口webhdfs。
在内部。Spark使用MapReduce的TextInputFormat API读取文件,因此文件的分区和MapReduce是一样的,一个Block相应一个Partition。我们也能够明白指定想要的Partition数:
val text:RDD[String] = sc.textFile("hadoop-fs-path" , 10 )另外。我们能够把整个文件当做一条记录来处理,此时创建的RDD是一个PairRDD。key为文件路径,value为文件的内容:
val file:RDD[(String,String)] = sc.wholeTextFiles("hadoop-fs-path")除了读取文本文件外,Spark也能够读取其它格式的文件,比如SequenceFile:
sc.sequenceFile[IntWritable,Text](input-path)对于Writable数据类型,Spark会自己主动将其转成相应的Java类型,因此以下这个语句与上边的等同:
sc.sequenceFile[Int,String](input-path)对于随意类型的Hadoop InputFormat,有2中方式能够创建RDD:
- hadoopFile(): 用于基于文件的。用一个路径来指定的情况
- hadoopRDD():用于其它情况,比如HBase的TableInputFormat。
新版本号的MapReduce(即V2)使用相应的newAPIHadoopFile和newAPIHadoopRDD。
比如我们想读取Avro格式的文件:
val job = new Job()
AvroJob.setInputKeySchema(job,WeatherRecord.getClassSchema)
val data = sc.newAPIHadoopFile(input-path ,
classOf[AvroKeyInputFormat[WeatherRecord]],
classOf[AvroKey[WeatherRecord]],
classOf[NullWritable],
job.getCofiguration)第二行中我们把Schema增加做Job的配置中,方法四个參数分别为:
- 文件路径
- InputFormat类型
- Key类型
- Value类型
- Job配置
第3中创建RDD的方式是从已有的RDD转换而来,下一部分的Transformation具体介绍这样的方式。
转化:Transformation和Action
Spark定义了2种作用于RDD的的操作:Transformation和Action。Transformation从一个已有的RDD。计算生成还有一个RDD。
Action作用在一个RDD上,计算后对结果进行操作。返回给用户或者保存到外部存储中。
调用Action会马上生效。可是Transformation是懒执行的(lazy),全部转换操作仅仅有当Action触发之后才会执行。
val text = sc.textFile(input-path)
val lower: RDD[String] = text.map(_.toLowerCase)
lower.foreach(println(_))上述代码中,map是一个操作,foreach是一个Action,仅仅有当调用foreach时,Spark才会执行一个作业,从文件里读取数据创建RDD,针对每一个元素调用toLowerCase方法,输出控制台。
区分一个操作是Transformation还是Action,一般能够通过返回类型来推断。假设返回的是RDD,则为Transformation。否则为Action。关于RDD操作的描写叙述,大部分能够在org.apache.spark.rdd包下的RDD类找到,特定类型的键值对RDD。能够在PairRDDFunctions中找到。
Spark的库中带了非常丰富的操作。包括mapping,grouping,aggregating。repartitioning。sampling,joining等转换操作,Action操作包括从RDD中提取固定个数的元素,抽样。保存到外部等。
更具体的描写叙述能够在Spark文档中找到。
作用在键值对RDD上的聚合操作主要有3个:
- reduceByKey
- foldByKey
- aggerateByKey。
这三个操作都是作用在每一个key上,对key上的值列表进行聚合操作。得到一个值。相应的reduce。fold,aggregate操作相似,可是是作用在整个RDD上,终于生成单一值。以下以一个样例来说明这三个Transformation:
val pairs:RDD[(String,Int)]=
sc.parallelize(Array(("a",3),("a",1),("b",7),("a",5)))
val sums: RDD[(String,Int)] = pairs.reduceByKey(_+_)
assert(sums.collect().toSet === Set(("a",9),("b",7)))针对每一个key,reduceByKey操作将加法函数_+_循环作用在全部值。比如,对于a这个key。其值有:3,1,5, 执行加法(3+1)+5=9,每一次计算将上一次计算结果与下一个值进行运算。
由于这些操作通常都是在集群中并行执行,所以聚合函数必须是commutative和associative的,也就是计算结果跟的顺序无关,我们的样例中(3+1)+5与(5+3)+1结果是一样的。
foldByKey的转换操作例如以下:
val sums :RDD[(String,Int)] = pairs.foldByKey(0)(_+_)
assert( sums.collect().toSet === Set(("a",9),"b",7)))不同于reduceByKey,foldByKey须要传递一个初始的”零值”,不同类型的零值可能不同,此时聚合变成 (((0+3)+1)+5)=9,初始值第一个參与运算,其它值顺序无关,b相应的聚合为0+7=7。
reduceByKey和foldByKey都无法改动聚合结果的类型,即整数相加之后得到的依旧数整数,不能改动类型。
要想改动聚合结果的类型,须要使用aggregateByKey:
val sums :RDD[(String , HashSet[Int])]=
pairs.aggregateByKey(new HashSet[Int])( _+=_ ,_++=_)
assert( sums.collect().toSet ===
Set( ("a",Set(1,3,5)),
("b",Set(7))
)
)我们提供了一个初始的值。即空的Set[Int],另外我们提供了两个函数(_+=_,_++=_).第一个函数控制值是怎样合并到Set中的,_+=_是a=a+b的简写,对于Set而言。就是把值增加到原有的Set中,返回一个新的Set。原有Set保持不变。
第2个函数控制的是两个Set是怎样合并在一起的,这个在reduce中合并来自己多个Partition的聚合结果时使用。这里的函数_++=_表示将第二个Set中的元素都加到第一个Set中。
转换之后的RDD能够在内存中持久化,以便兴许的操作能够更高速地訪问。
持久化:Persistence
前面我们提到将RDD转化成键值对的RDD,这个开销相对照较大。我们将转化的结果缓存下来:
tuples.cache()调用cache方法并不会立马将结果缓存,而是设置一个标志位告诉Spark:当执行这个作业的时候,将结果缓存下来。
为了让这个缓存真正存在内存中。我们触发一个Action:
tuples.reduceByKey((a,b)=>Marh.max(a,b)).foreach(println(_))返回结果中的BlockManagerInfo显示RDD的编号(RDD number)为4,有2个Paritition。同一个应用中兴许作业假设须要用到这个RDD。将直接从缓存载入。我们执行一个找最小值的的转换:
tuples.reduceByKey((a,b) => Math.min(a,b)).foreach(println(_))从输出信息能够看到RDD是直接从缓存载入的(Found Block locally)。当数据量比較大事,能够节约的时间非常可观。相比于MapReduce。不同的作业之间假设想连接起来,仅仅能通过写入文件,兴许作业再从磁盘中读取。Spark能够将数据集缓冲在集群的内存中,兴许作业能够高速读取数据。
Spark RDD的这样的特性使得其在交互性的应用中非常有用,对于须要多次迭代的算法也非常适合在Spark上执行,迭代过程中的产生的数据能够缓存在内存中,供下一轮迭代使用。
迭代算法能够通过MapReduce实现,可是每一轮迭代的结果须要写入磁盘,下一轮再从磁盘读取。效率低下。
须要注意的是,缓存的RDD仅仅能被同一个应用的作业读取,假设须要跨应用使用这些RDD。须要使用相应的saveAs*以及hadoopFile,hadoopRDD保存数据到外部存储,然后再写入。
当一个应用执行结束后。其全部缓存的RDD将无法訪问。除非保存到外部存储中。
持久化级别
调用cache方法,能够将RDD的各个partition保存到其executor的内存中。假设内存容纳不下,作业不会失败。而是在必要的时候又一次计算。对于拥有非常多Transformation的大型作业,又一次计算是非常昂贵的。
因此Spark提供了不同级别的持久化机制。在调用persist方法时传入StorageLevel參数。控制持久化类型和级别。
默认情况下,持久化级别为MEMORY_ONLY,这个级别的缓存数据,在内存中以对象的形式存在。能够通过将对象序列化成字节数组。达到更紧凑的数据格式,节约内存空间,这个级别是MEMORY_ONLY_SER。相比MEMORY_ONLY,这样的序列化的方式更耗CPU,可是当未序列化的数据存不下内存而序列化之后能够存放于内存时,这样的牺牲是值得的,用CPU换内存,这是常见的一种权衡。MEMORY_ONLY_SER的持久化级别同一时候减少了GC压力,由于RDD是以一个字节数组存在于内存中的。而不是非常多对象。
怎样知道内存是否能容纳下RDD。能够通过查看BlockManager的日志文件来获取这一信息。
另外,每一个驱动程序的SparkContext都在4040端口上执行了一个HTTP Server,这个服务器提供了非常多有用的信息,比如关于SparkContext执行环境。当中执行的作业。还有缓存的RDD Paritition信息。
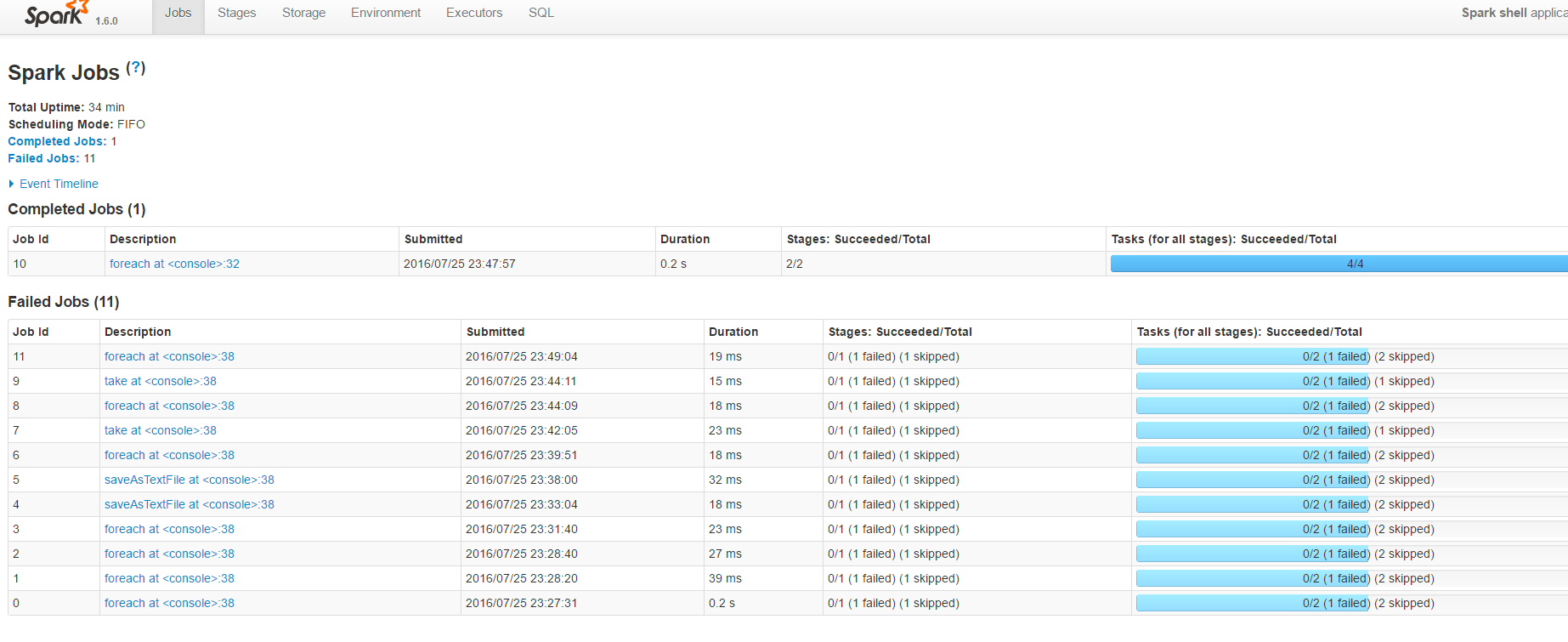
默认情况下。RDD Partition有用Java的序列化方式来序列化数据,但通常情况下Kyro是一个更好的选择。不管实在速度上还是空间效率上。另外能够通过压缩来进一步节约内存空间,可是这是以CPU计算为代价的。要使用压缩格式。将spark.rdd.compress属性设为true。并依据须要设置压缩算法spark.io.compression.codec.
假设又一次计算RDD的代价非常昂贵,那么值得考虑另外的2中持久化级别:MEMORY_AND_DISK和MEMORY_AND_DISK_SER。前者会在内存不足时将数据写入到磁盘,后者在序列化后的数据仍然无法存放在内存时。将数据写到磁盘。
另外还有一些更高级的持久化特性,比如将RDD Partition的多个副本存在集群的不同节点上。或者使用对外(off-heap)内存,更具体内容參考Spark文档。
序列化
Spark中的序列化通常考虑2个方面:
- 数据序列化
- 函数序列化
数据序列化
默认情况下。Spark使用Java的序列化机制序列化数据,并通过网络发送给其它Executor。持久化(或者缓存)RDD Partition的时候也会涉及到数据序列化。实现了Serializable或Externalizable接口的对象使用Java标准的方式序列化之后,非常easy被其它JVM应用理解。
可是在性能和空间效率上不是非常理想。
对于大部分的Spark程序来说。Kyro 序列化是更好的选择方式。Kyro是一种各高效的通用Java序列化库。要使用Kyro序列化。须要在SparkConf上配置例如以下序列化器:
conf.set("spark.serializer","org.apache.spark.serializer.KyroSerializer")Kyro不要求实现不论什么特定的接口(像java.io.serializable那样)。侵入性非常小。所以POJO能够直接被序列化,除了启用Kyro序列化以外,无需不论什么其它操作。可是,假设在使用一个类之前先在Kyro注冊,能够使得性能更加高效。假设没有注冊,Kyro在序列化时会写入一个对象所属类的引用,每一个被序列化的对象都会写入一个类的全称。假设事先注冊,则仅仅写入一个整数ID。Spark已经默认注冊了Scala的类和更多框架的类,比如Avro Generic,Thrift的类。
在Kyro中注冊类非常直接,创建一个KyroRegistrator的子类。实现registerClasses方法:
class CustomKyroRegistrator extends KyroRegistrator {
override def registerClassed(kyro : Kyro) {
kyro.register(classOf[WeatherRecord])
}
}然后在驱动程序中。将Registrator的类名全称赋给spark.kyro.registrator属性:
conf.set("spark.kyro.registrator","CustomKyroRegistrator")函数序列化
在Scala中,函数的序列化採用的是Java标准的序列化机制。Spark也使用这样的标准的方式发送函数给远程的Executor节点。其实。即使执行在local模式(即全部Spark组价都在一个JVM中执行),Spark也会序列化函数。
假设在代码中使用了不可序列化的函数,Spark将会报错,比如从不可序列化类的一个方法中转换而来的方法是不可序列化的。
共享变量
Spark程序常常须要訪问不在RDD中的数据,比如以下的代码在map方法中使用了一个查询表:
val lookup = Map( 1 -> "a" , 2 ->"e" , 3->"i" , 4->"0",5->"u")
val result = sc.parallelize(Array(2,1,3)).map(lookup(_))
assert( result.collect.toSet === Set("a" , "e","i"))这样的方式没有问题,lookup变量被序列化之后作为一个闭包(closure)传递给map方法。
可是使用广播变量(broadcast variables),能够更高效地达到相同的效果
广播变量:Broadcast variables
广播变量会被序列化,然后发送给每一个executor,executor将广播变量缓存,以便兴许须要的时候使用,这不同于被序列化为闭包一部分的常规变量。常规变量会作为闭包的一部分通过网络发送给每一个task。
广播变量有点相似MapReduce中的分布式缓存,尽管Spark的实现中将数据存储在内存。仅仅有在内存耗尽时才会写到磁盘(而MapReduce的分布式缓存位于磁盘中)。
使用SparkContext的broadcast方法来广播变量,该方法返回一个Broadcast[T]类型的包装器:
val lookup:Broadcast[Map[Int,String]] =
sc.broadcast(Map(1->"a",2->"e",3->"i",4->"o", 5 ->"u"))
val result = sc.parallelize(Array(2,1,3)).map(lookup.value(_))广播变量的值通过value来訪问。注意的是,广播变量是单向传播的,从驱动到任务,没有办法更新广播变量或者将更新传播回驱动程序。这样的情况下。能够通过Accumulator来实现。
Accumulators
累积器是一个共享变量,任务仅仅能做增加操作。就像MapReduce中的counter。
当一个作业执行完毕后。累积器的终于值能够从驱动程序中获取。以下这个样例使用累积器来统计整形的RDD中有多少个元素,同一时候使用reduce Action来计算总和:
val count:Accumulator[Int] = sc.accumulator(0)
val result = sc.parallelize(Array(1,2,3))
.map( i => {count += 1; i})
.reduce((x,y) => x + y)
assert(count.value === 3)
assert(result === 6)累计变量count通过SparkContext的accumulator方法创建。
当中的map操作是个identify function。原值返回,可是产生了count加1的副作用。
当作业执行完毕之后,累积器的值通过value訪问得到。
上面的样例中,我们使用Int类型的累积器,可是不论什么数值类型的数据类型都能够用于累积器。
Spark另外提供了accumulable方法,用于累积器的结果类型和被累积的类型不一致的情况,accumulableCollection用于累积可变集合的值。更多内容參考Spark文档。
Spark作业执行过程
Spark作业的执行从宏观上看。仅仅要由driver和executors组成。driver执行application(SparkContext)、调度作业(schedule tasks)。executor负责具体任务的执行。通常情况下。driver执行在client机器上(client一般不受整个集群管理)。可是在YARN的cluster模式上,driver执行在Application Master上。
下图是Spark执行作业的总体流程:
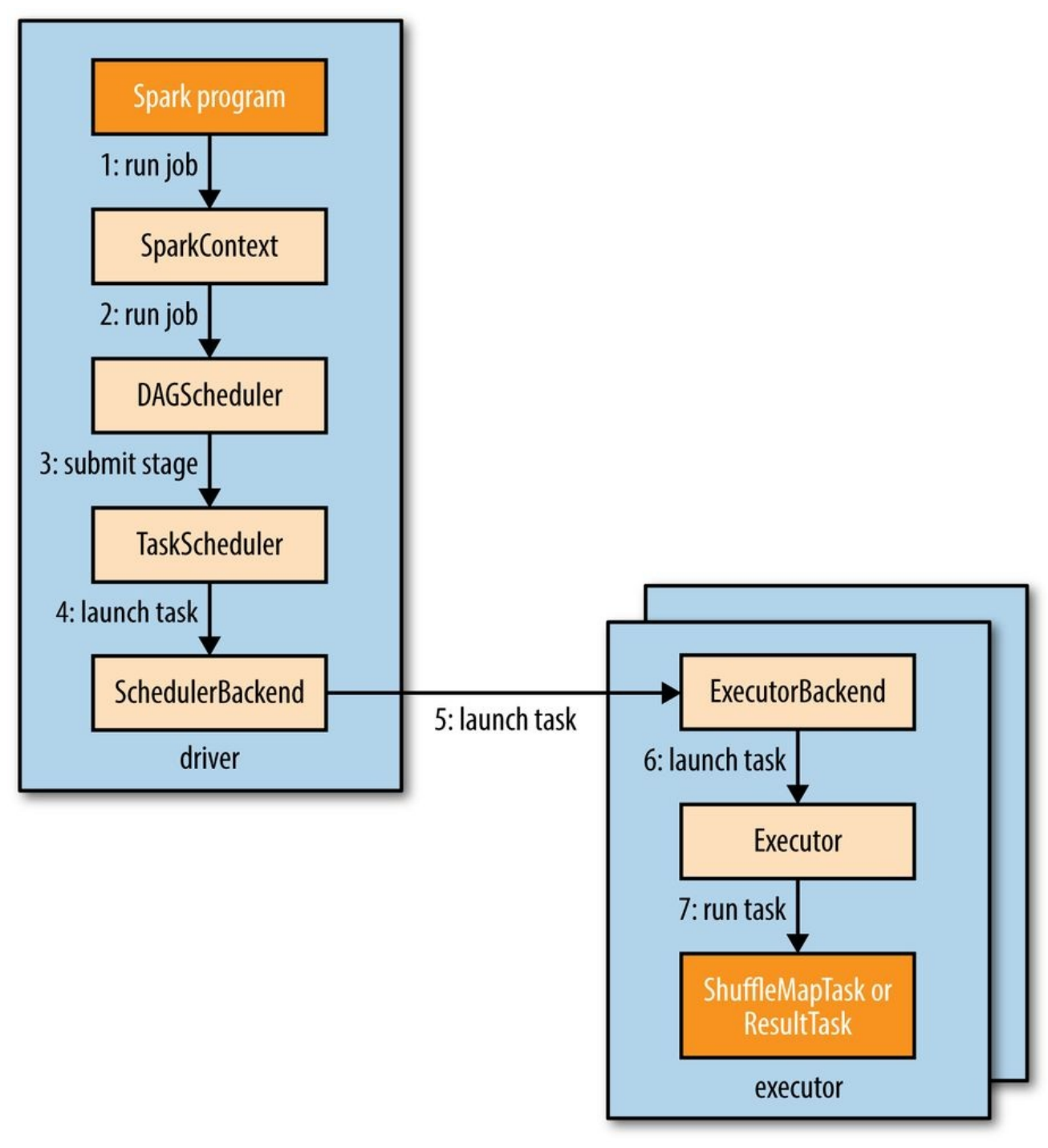
当有Action在RDD上执行时,作业被自己主动提交,提交将调用SparkContext的run_job被调用,进而把作业提交给Scheduler。Scheduler执行在driver上,由两部分组成:
- DAG Scheduler:负责将作业分解为stage组成的DAG
- Task Scheduler:负责提交每一个stage的Task到集群。
构造DAG
在介绍作业怎样被分解为DAG之前,我们须要了解一下stage能够执行的任务类型,stage能够执行2中类型的任务:shuffle map task和result task。
- shuffle map task
这样的类型的任务相似于MapReduce中的map端shuffle。每一个shuffle map任务在RDD partition上执行计算,而且依据partitioning 函数将结果写入新的partition,这些结果在兴许被下一个stage取走。shuffle map task执行在最后一个stage以外的全部stage。 - result task
result task执行在作业的最后一个stage上,最后一个stage将结果返回给用户程序(user’s program).每一个Result任务在他的RDD Partition上执行,并将结果发回给driver。driver组合来自每一个partition的结果。得到终于的计算结果。
最简单的作业能够仅仅有Result Task,也就是仅仅有一个由Result Task组成的stage。对于复杂的应用。可能须要组合多个shuffle stage。比如,以下的样例中我们想要计算词语的频率分布直方图:
val hist:Map[Int,Long] = sc.textFile(inputPath)
.map(word => (word.toLowerCase(),1))
.reduceByKey((a,b)=>a+b)
.map(_.swap)
.countByKey()前两个Transformation统计词频,即计算每一个词语出现的次数。第三个Transformation对调key和value。得到的是(count。word)。最后的Action countByKey()得到频率直方图。即出现N词的词语有M个。
Spark的DAG Scheduler将这个作业分解为2个Stage。由于reduceByKey()这个Operation须要通过shuffle stage来完毕。最后的DAG例如以下图所看到的:
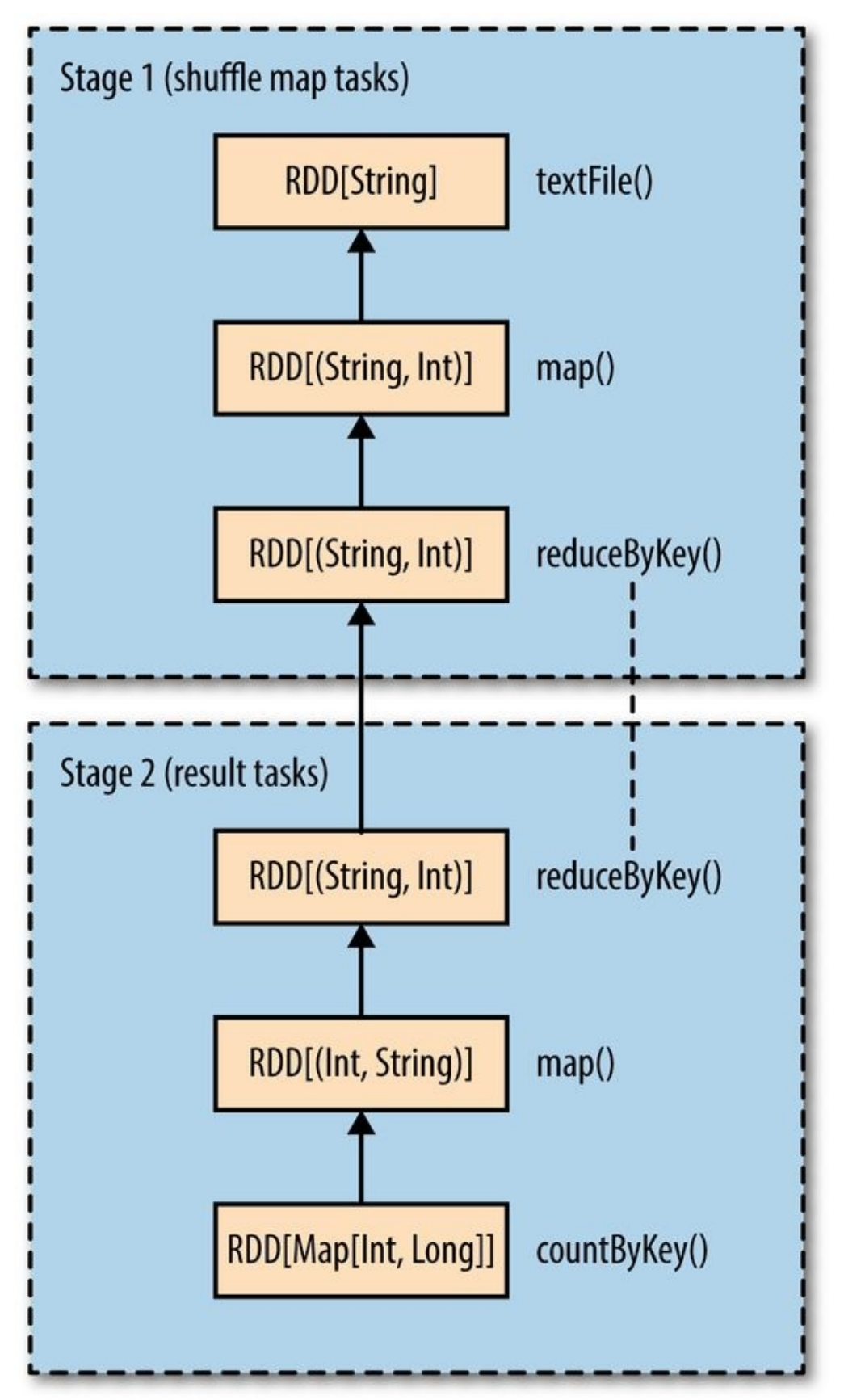
在一个stage内,RDD通过也被组织成DAG。上图中展示了RDD的类型以及产生该RDD的操作。RDD[String]有sc.textFile()创建。
图中省略了一些Spark内部产生的RDD,比如textFile()创建的RDD其实是MappedRDD[String],其父类为HadoopRDD[LongWritable,Text]。
注意到reduceByKey同一时候出如今两个Stage中,这是由于它是使用shuffle实现的。在map端(stage1)reduce函数作为combiner执行,在reduce端(stage2)作为reducer执行。
这一点相似于MapReduce。有些情况下降Reducer的实现直接作为map端的Combinor,对map任务的输出结果先做一次预聚合,能够避免在网络上传输大量数据。
Spark的shuffle实现把输出写入到本地的分区文件(partitioned file),即使是内存级别的RDD,这些文件被下一个stage的RDD取走。
假设RDD已经被上一个job(同一个Application)持久化,则DAG Scheduler不会再创建stage又一次计算这个RDD(或者由这个RDD衍生的其它RDD)。
DAG Scheduler还负责将stage分级为task,然后将task提交给Task Scheduler。在这个样例中,输入文件的每一个partition,执行一个task(shuffle map)。reduceByKey()的并行度(parallelism)能够通过其第二个參数设置,假设没有设置,则从其上一级RDD推断。这个样例中就是输入数据的partition数量。
针对每一个Task。DAG Scheduler都给出了一个位置偏好(placement preference),Task Scheduler能够依据这些偏好,更有效地理由本地数据的优势(data locality)。
比如。假设task处理的是来自HDFS的RDD,则更倾向于执行在拥有相应数据的节点上(node local)。而假设一个task处理的数据来自于缓存在内存中的RDD partition。则倾向于执行在内存中拥有这些数据的executor(process local)。
一旦DAG Scheduler构建完stage的DAG后。将每一个stage的任务提交给task scheduler。子stage仅仅有在其上一级完毕之后才提交。
任务调度
当task scheduler收到一组任务后,它依据应用持有的executor列表(在YARN中。Spark会实现申请固定数量的容器,然后自己决定怎样使用这些Container,这一点不同于批处理的MapReduce,MapReduce按需申请Container)。结合任务的位置偏好,决定每一个任务执行在哪个executor,即task-executor映射。
然后把task分配给空暇的executor,直到任务集都执行完毕。
默认情况下。每一个task分配一核CPU,CPU数量能够通过spark.task.cpus设置。
对于一个给定的executor,作业调度器优先分配有process-local偏好的task,然后依次是node-local,rack-local。最后才是没有位置偏好(nonlocal的任务或者猜測执行(speculative)的任务。
已分配的任务通过scheduler backend启动,这个backend发送启动任务的消息给相应的executor backend,告知executor開始执行任务。
Spark使用Akka发送远程消息,而不是使用Hadoop的RPC机制,Akka用于构建高并发和分布式的JVM应用。提供了工具箱和执行时。
Executor在任务结束或者失败的时候发送状态消息给driver,假设任务执行失败。task scheduler将又一次提交任务到还有一个executor。
假设启用了猜測执行(默认没有启用),对于执行慢的任务,会启用speculative任务。
任务执行
Executor接到执行任务的消息后,首先确认任务须要的jar包和文件都是最新的。
假设之前的任务执行过,executor会在本地缓存这些jar包和文件,仅仅有当发生变更时才会又一次下载。接着反序列化任务代码,任务代码以序列化字节的形式通过任务启动消息发送到executor。最后任务在executor同一个JVM中被执行。因此无需再任务启动的时候又一次启动JVM。
任务执行的结果序列化之后发送给executor backend,然后作为状态更新消息(status update message)发回给driver。
假设是shuffle map task。返回中包括的信息用于下一个stage提取数据,相似于MapReduce中map任务完毕之后,通过心跳发送消息给Application Master,然后Reducer通过心跳得知map已经执行完毕,进而去copy数据。假设是Result task。将相应partition的执行结果发送给driver。driver组合出终于结果。
Executor和Cluster Manager
上一部分我们了解了Spark是怎样依靠executor来执行任务的。接下来进一步了解executor到底是怎样启动的。Spark中,executor的声明周期通过cluster manager来管理。Spark提供了多种不同的manager:
- Local
Local模式中,仅仅有一个跟driver执行在同一个JVM的executor。对于測试或者执行小型任务,这样的模式非常有用。该模式下master的url为local(使用一个线程),local[n](n个线程)或者local(*)(线程数和CPU核数相等)。
- Standalone
Standalone是cluster manager一种简单的分布式实现。执行一个Spark master和一个或多个的worker。当Spark应用启动之后,master代表应用要求worker执行task。master的url为spark://host:port - Mesos
Apache Mesos是一种通用的集群资源管理框架。在fine-grained模式下。每一个Spark Task作为一个Mesos Task执行。这样的方式能够更有效地利用集群资源,可是以进程启动负担为代价。
在coarse-grained模式下,executor在进程任务执行任务。所以集群资源在Spark应用程序执行过程中一直被executor持有。
master的url地址为mesos://host:port
- YARN
YARN是Hadoop使用的资源管理框架,每一个Spark应用相应一个YARN 应用实例。每一个executor在其自己的Container中执行。master的url为yarn-client或者yarn-cluster。
Mesos和YARN的资源管理方式优于Standalone。它们考虑了集群中其它应用对资源的需求(比如MapReduce作业),而Standalone採用静态的资源分配方式,没有办法动态地调整以满足集群的其它资源需求。
YARN是唯一一个与Hadoop的Kerberos安全机制集成的cluster manager。
Spark on YARN
Spark能够通过两种模式执行在YARN上:
- YARN client mode:
Driver执行在client机器上。对于包括有交互式组件的应用,必须使用这样的模式,比如spark-shell和pyspark。在开发和调试Spark应用的时候,这样的模式能够立马查看到debug信息。
- YARN cluster mode:
Driver执行在集群的Application Master上,适合于生产环境中的应用。整个应用执行在集群上,方便管理应用的日志文件。
另外YARN在Application Master故障的时候会重试应用。
YARN client mode
在YARN client模式上,在driver构造出SparkContext实例(下图step1)的时候,就開始于YARN进行交互。Context向YARN的资源管理器(RM)提交一个应用(step2),RM在集群的NodeManager中启动一个Container,并在Container中执行Spark ExecutorLauncher(step3)。ExecutorLauncher的任务是向RM申请资源(step4),并在申请到资源后将Executor Backend作为容器在相应的NodeManager中启动(step5)
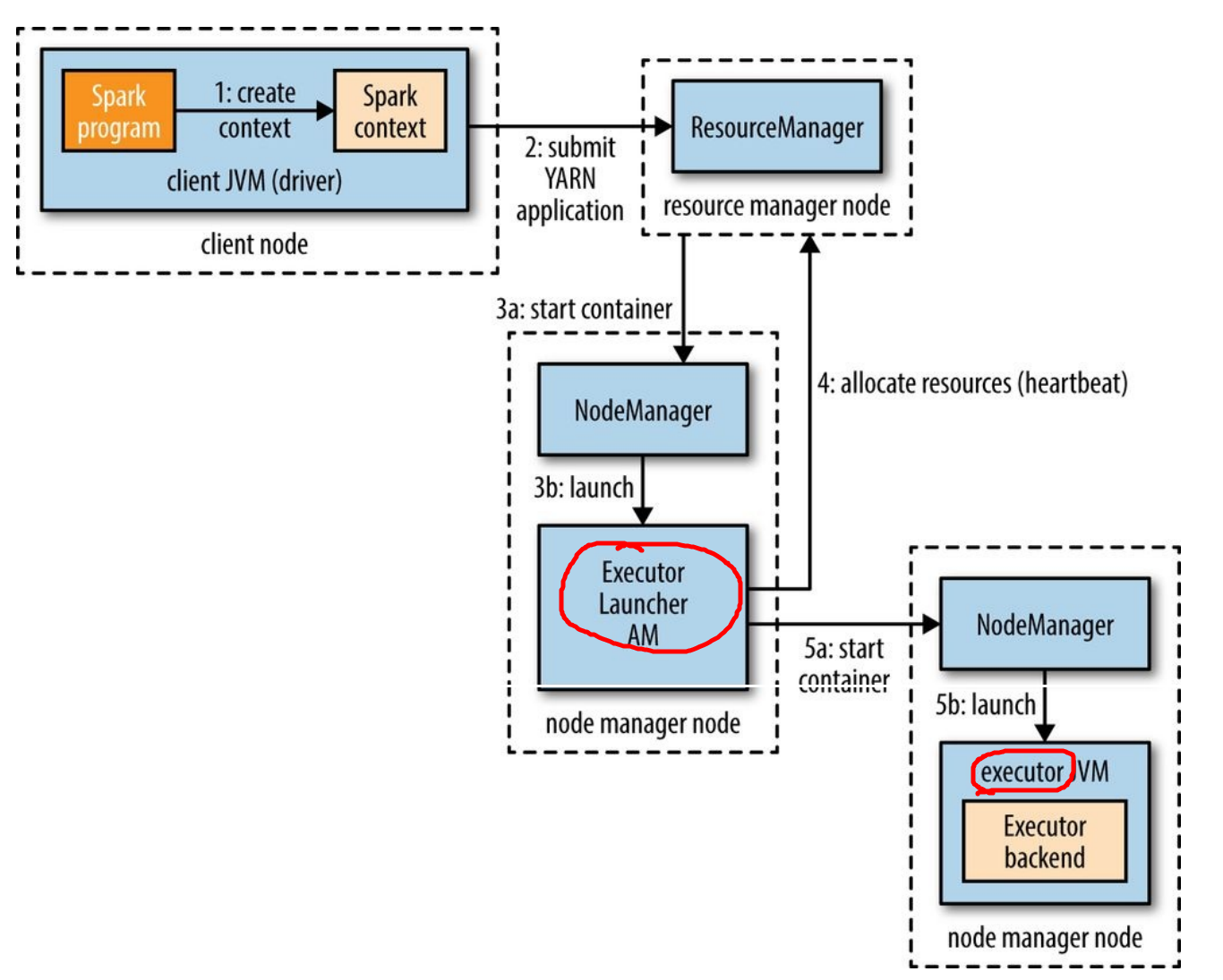
当executor启动后,回头连接到SparkContext并注冊自己,注冊的这个步骤能够给SparkContext提供整个应用的executor信息,一遍task scheduler在决定将任务执行在哪个节点(task placement decision)的时候,能够考虑任务的位置偏好。
executor的数量在启动spark-shell,spark-submit或者pyspark时指定,假设没有指定,默认启动2个executor。每一个executor使用的CPU核数(默认1)和内存大小(默认1024M)也能够在这个时候设置,以下这个样例启动spark-shell,执行4个executor:
spark-shell --master yarn-client --num-executors 4 --executor-cores 1 -- executor-memory 2g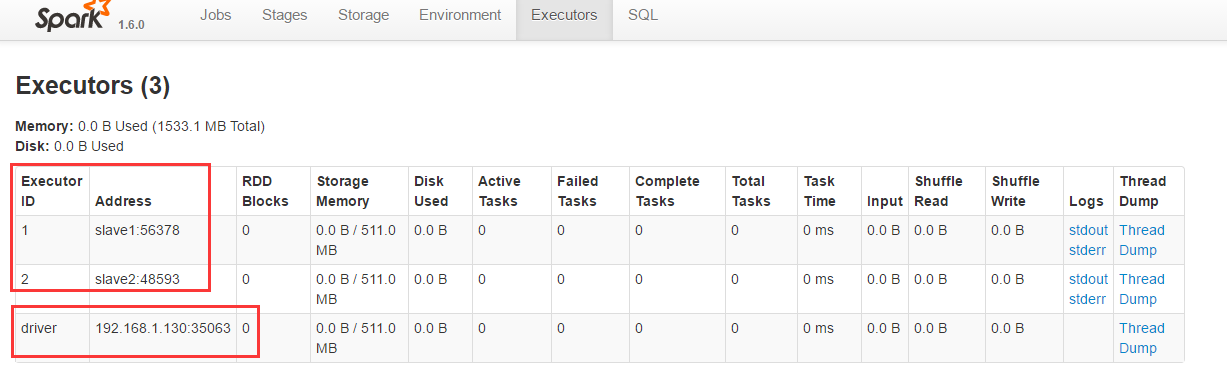
不同于Standalone或者Mosos。YARN的NM地址并没有在这里配置,而是从Hadoop的配置中提取,配置的文件夹通过HADOOP_CONF_DIR设置环境变量。
YARN cluster mode
在cluster模式下,用户的驱动程序(driver。下图的Spark Program)执行在YARN的Application Master进程中,使用该模式时,指定master的url相似:
spark-submit --master yarn-cluster ...其它參数。比如executor数量,jar包或者python文件,与client mode一样。
例如以下图所看到的,spark-submit客户端将启动一个YARN Application(step1通过请求NM),可是它不执行不论什么用户代码。Application Master在開始为executor申请资源(step4)之前将启动驱动程序(step3b)。其它的过程与client mode一样。
注意此时我们假设再訪问刚才的4040端口,发现页面自己主动跳转到YARN的应用程序管理界面了,url相似:
master:18088/proxy/application_1469461440579_0001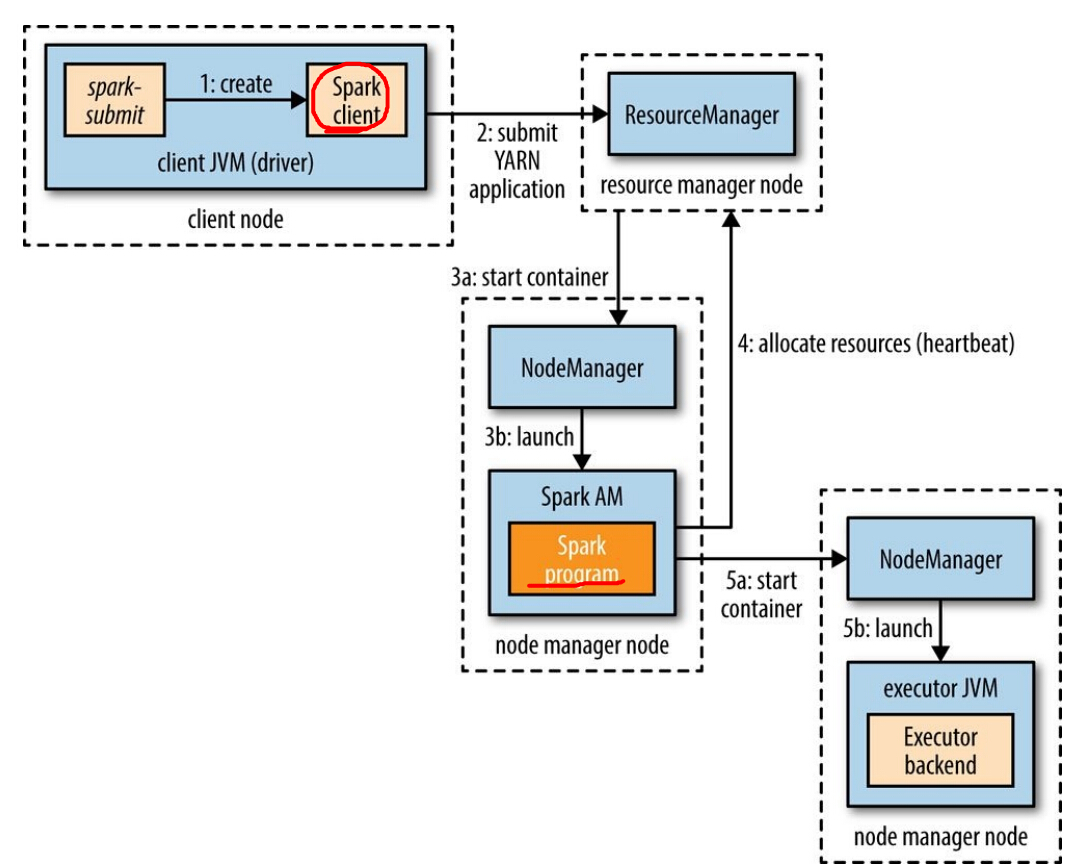
YARN的两种模式下。启动executor之前对于数据放在哪里(data locality)并不知道,所以启动的executor可能与所要处理的数据不在一个节点上(从而task的位置偏好无法得到满足)。
对于交互式的session来说,这个是比較easy接受的。由于在启动一个交互会话时,非常可能并不知道要处理哪些数据。
可是在生产环境中就不是这样了,所以Spark提供一种方式。当应用执行在cluster模式时,能够通过位置提示(placement hint)来提高data locality,这是通过构造SparkContext时传入位置偏好达到的。
构造SparkContext之前,我们能够使用InputFormatInfo这个工具类来获取位置偏好,比如对于文本文件,使用TextInputFormat。例如以下能够获取位置偏好:
val preferredLocations = InputFormatInfo.computePreferredLocations(
Seq(new InputFormatInfo(new Configuration(),classof[TextInputFormat],inputPath)))
val sc = new SparkContext(conf , preferredLocations)这些位置偏好信息在Application Master为executor申请资源的时候能够使用,眼下该特性的API还不是非常稳定。
最后我们提交一个Spark自带的样例到YARN集群执行:
export HADOOP_CONF_DIR=/home/hadoop-2.6.0/etc/hadoop/
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --executor-memory 2G --num-executors 6 /home/spark-1.6.0/lib/spark-examples-1.6.0-hadoop2.6.0.jar 1000执行结果:
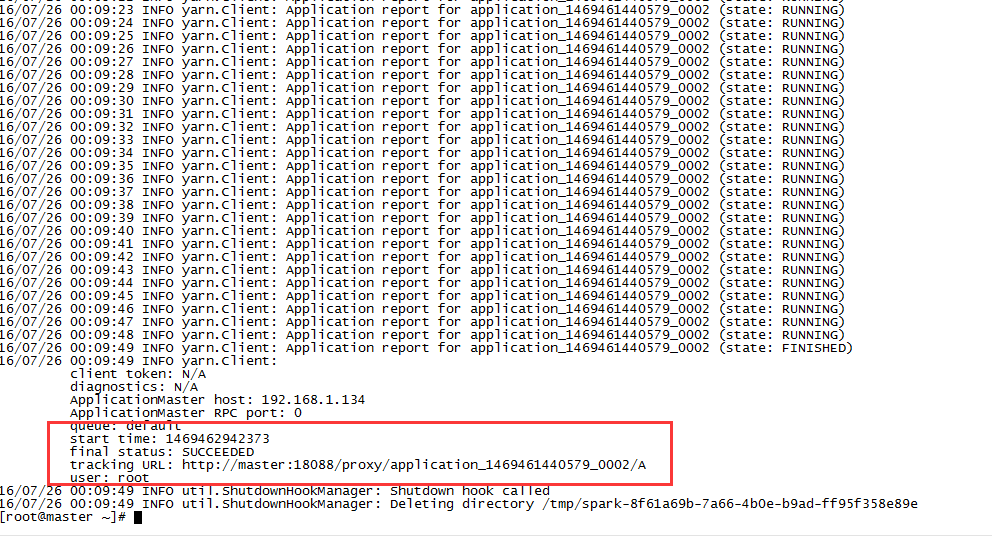
执行成功后在YARN管理界面能够看到这个Spark作业:

參考资料
大部分内容来自《Hadoop权威指南》第4版