在 Faster R-CNN 中,检测器使用了多个全连接层进行预测。如果有 2000 个 ROI,那么成本非常高。
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
class_scores, box = detector(patch) # Expensive!
class_probabilities = softmax(class_scores)
R-FCN 通过减少每个 ROI 所需的工作量实现加速。上面基于区域的特征图与 ROI 是独立的,可以在每个 ROI 之外单独计算。剩下的工作就比较简单了,因此 R-FCN 的速度比 Faster R-CNN 快。
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
score_maps = compute_score_map(feature_maps)
for ROI in ROIs
V = region_roi_pool(score_maps, ROI)
class_scores, box = average(V) # Much simpler!
class_probabilities = softmax(class_scores)现在我们来看一下 5 × 5 的特征图 M,内部包含一个蓝色方块。我们将方块平均分成 3 × 3 个区域。现在,我们在 M 中创建了一个新的特征图,来检测方块的左上角(TL)。这个新的特征图如下图(右)所示。只有黄色的网格单元 [2, 2] 处于激活状态。
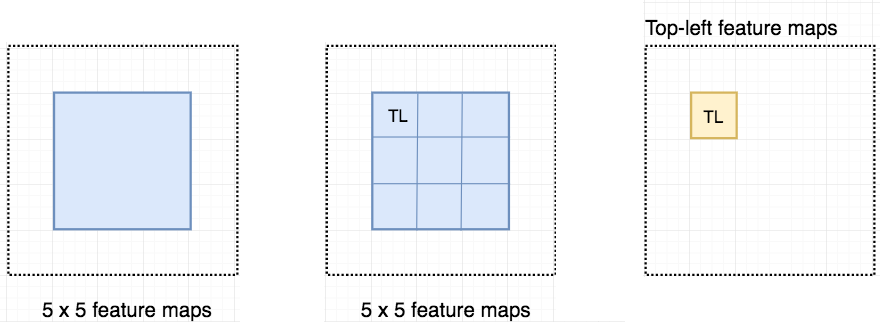
在左侧创建一个新的特征图,用于检测目标的左上角。
我们将方块分成 9 个部分,由此创建了 9 个特征图,每个用来检测对应的目标区域。这些特征图叫作位置敏感得分图(position-sensitive score map),因为每个图检测目标的子区域(计算其得分)。

生成 9 个得分图
下图中红色虚线矩形是建议的 ROI。我们将其分割成 3 × 3 个区域,并询问每个区域包含目标对应部分的概率是多少。例如,左上角 ROI 区域包含左眼的概率。我们将结果存储成 3 × 3 vote 数组,如下图(右)所示。例如,vote_array[0][0] 包含左上角区域是否包含目标对应部分的得分。

将 ROI 应用到特征图上,输出一个 3 x 3 数组。
将得分图和 ROI 映射到 vote 数组的过程叫作位置敏感 ROI 池化(position-sensitive ROI-pool)。该过程与前面讨论过的 ROI 池化非常接近。
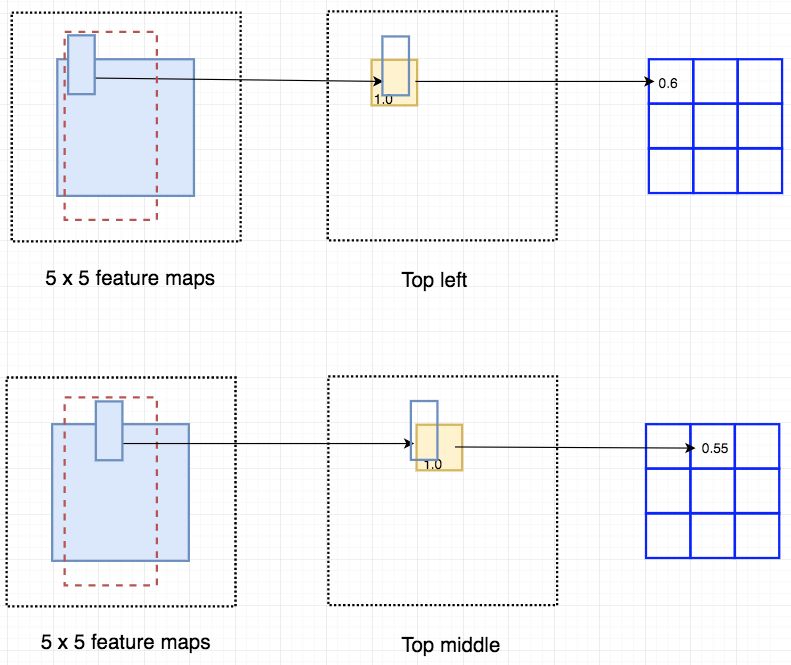
将 ROI 的一部分叠加到对应的得分图上,计算 V[i][j]。
在计算出位置敏感 ROI 池化的所有值后,类别得分是其所有元素得分的平均值。
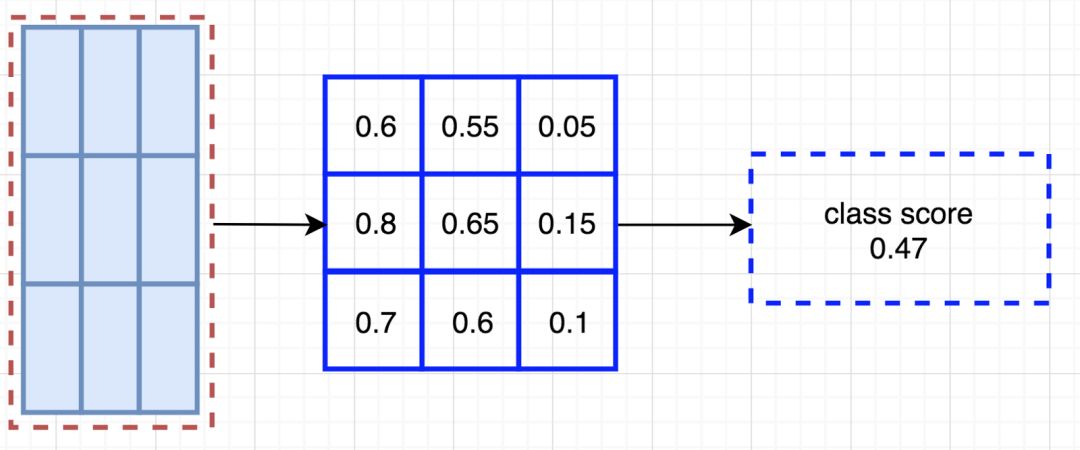
ROI 池化
假如我们有 C 个类别要检测。我们将其扩展为 C + 1 个类别,这样就为背景(非目标)增加了一个新的类别。每个类别有 3 × 3 个得分图,因此一共有 (C+1) × 3 × 3 个得分图。使用每个类别的得分图可以预测出该类别的类别得分。然后我们对这些得分应用 softmax 函数,计算出每个类别的概率。
以下是数据流图,在我们的案例中,k=3。
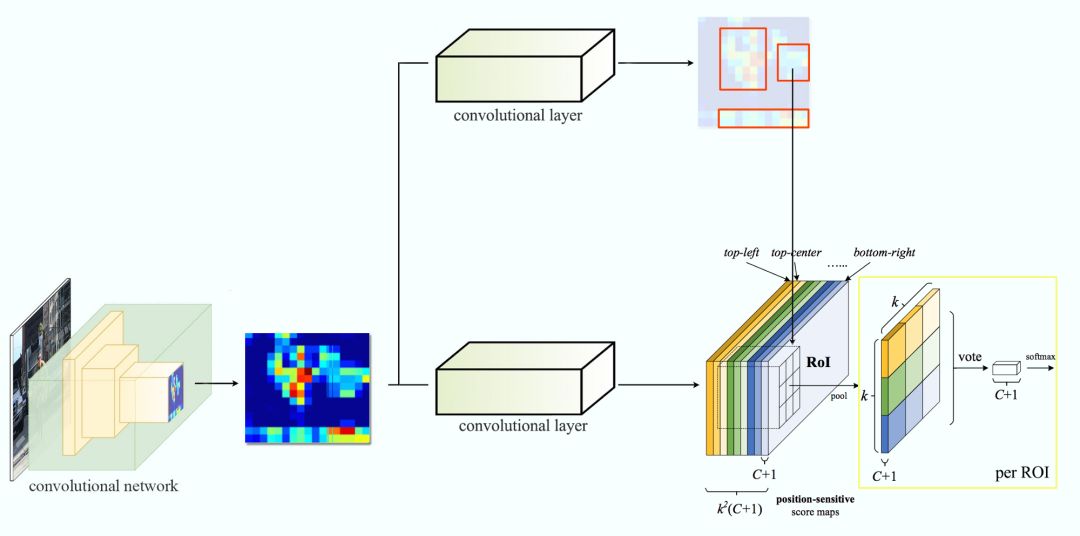
总结
我们首先了解了基础的滑动窗口算法:
for window in windows
patch = get_patch(image, window)
results = detector(patch)然后尝试减少窗口数量,尽可能减少 for 循环中的工作量。
ROIs = region_proposal(image)
for ROI in ROIs
patch = get_patch(image, ROI)
results = detector(patch)文章出处:https://mp.weixin.qq.com/s/5zE78EU_NdV5ZeW5t1yV7A