bean是Spring种最核心的东西 ,如果说Spring是个水桶的话,bean就是桶里面的水,桶里面没有水也就没有意义了。
public class MyTestBean { private String testStr="testStr"; public String getTestStr() { return testStr; } public void setTestStr(String testStr) { this.testStr = testStr; } }
Spring的目的就算让我们的Bean能成为一个纯粹的POJO(简单java对象,里面就是简单的set,get),这也是Spring所追求的。
配置文件
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id="myTestBean" class="com.lkeji.demo.MyTestBean"></bean> </beans>
@SuppressWarnings("deprecation")
public class BeanFactoryTest {
@Test
public void testSimpleLoad(){
MyTestBean bean = (MyTestBean) new XmlBeanFactory(new ClassPathResource("spring-config.xml")).getBean("myTestBean");
Assert.assertEquals("testStr",bean.getTestStr());
System.out.println(bean.getTestStr());
}
}

分析功能如何实现:
1、读取配置文件spring-config.xml
2、根据spring-config.xml中的配置找到对应的类的配置,并实例化
3、调用实例化后的实例
想完成我们预想的功能,至少需要3个类这是我从书里扣的图:
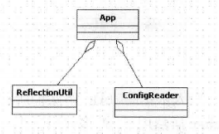
ConfigReader:
用于读取及验证配置文件,我们要用配置文件里面的东西,当然首先就是要做的就是读取,然后放置在内存中。
ReflectionUti:
用于根据配置文件中的配置进行反射实例化,比如在上例子中spring-config.xml出现的
<bean id="myTestBean" class="com.lkeji.demo.MyTestBean" ></bean>,我们就可根据
com.lkeji.demo.MyTestBean(类全名)进行实例化。
App:
用于完成整个逻辑的串联
看一下源码如何实现上面的简单功能:
首先看一下beans工程的源码结构
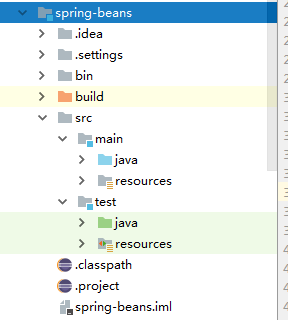
src/main/java :用于展现Spring的主要逻辑。
src/main/resources :用于存放系统的配置文件
src/test/java :用于对主要逻辑进行单元测试。
src/test/java :用于存放测试用的配置文件
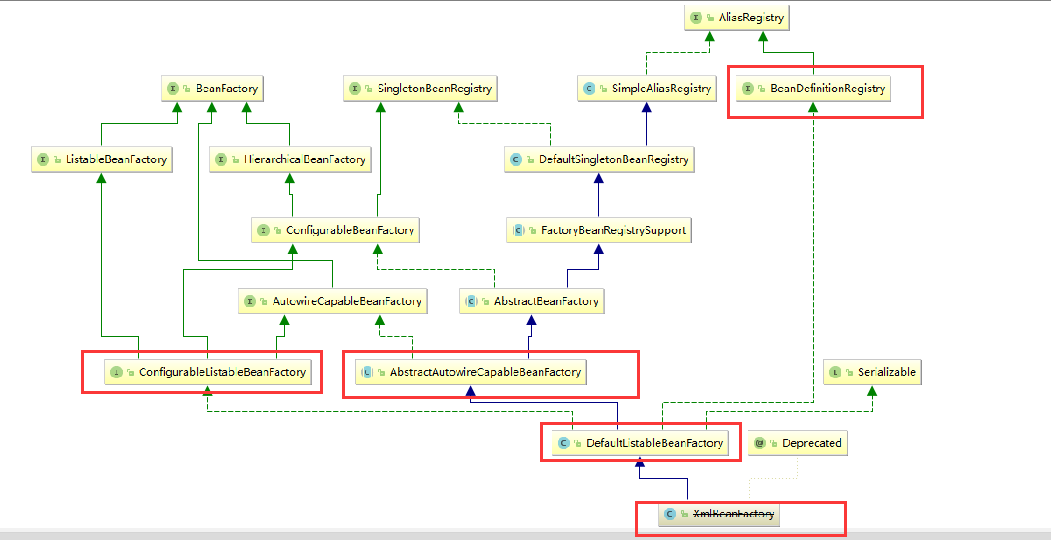
Spring中最核心的两个类:
DefaultListableBeanFactory:
XmlBeanFactory继承自DefaultListableBeanFactory,而DefaultListableBeanFactory是整个Bean加载的核心部分,是Spring注册及加载bean的默认实现,
而对于XmlBeanFactory与DefaultListableBeanFactory不同的地方其实是在XmlBeanFactory中使用了自定义的XML读取器XmlBeanDefinitionReader,实现了个性化的BeanDefinitionReader读取,
DefaultListableBeanFactory继承了AbstractAutowireCapableBeanFactory并实现了ConfigurableListableBeanFactory以及BeanDefinitionRegistry接口
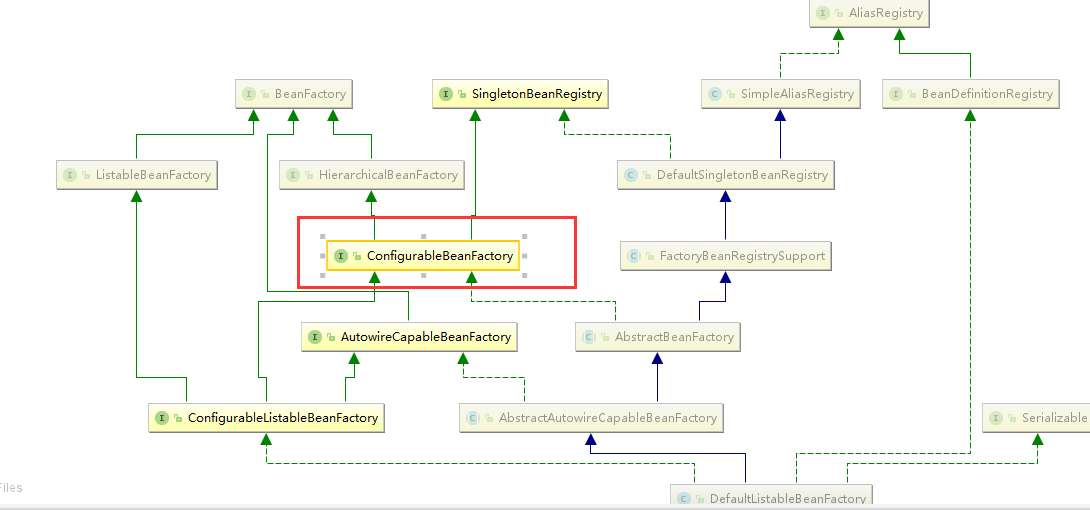
ConfigurableBeanFactory:提供配置Factory的各种方法
ListableBeanFactory:根据各种条件获取bean的配置清单

AbstractBeanFactory:综合FactoryBeanRegistrySupport和ConfigurableBeanFactory的功能
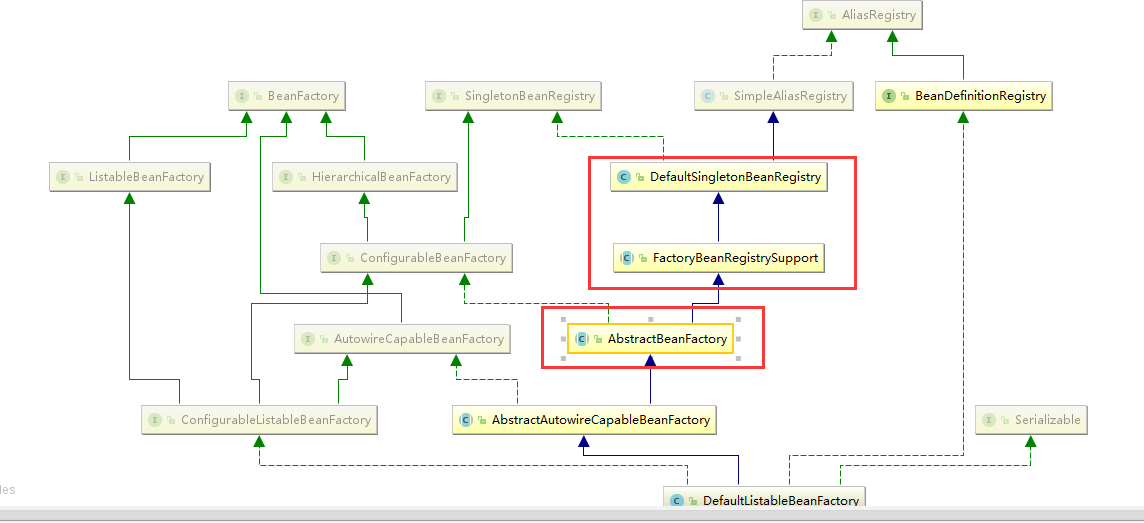 AutowireCapableBeanFactory:提供创建Bean,自动注入,初始化以及引用Bean的后处理器
AutowireCapableBeanFactory:提供创建Bean,自动注入,初始化以及引用Bean的后处理器
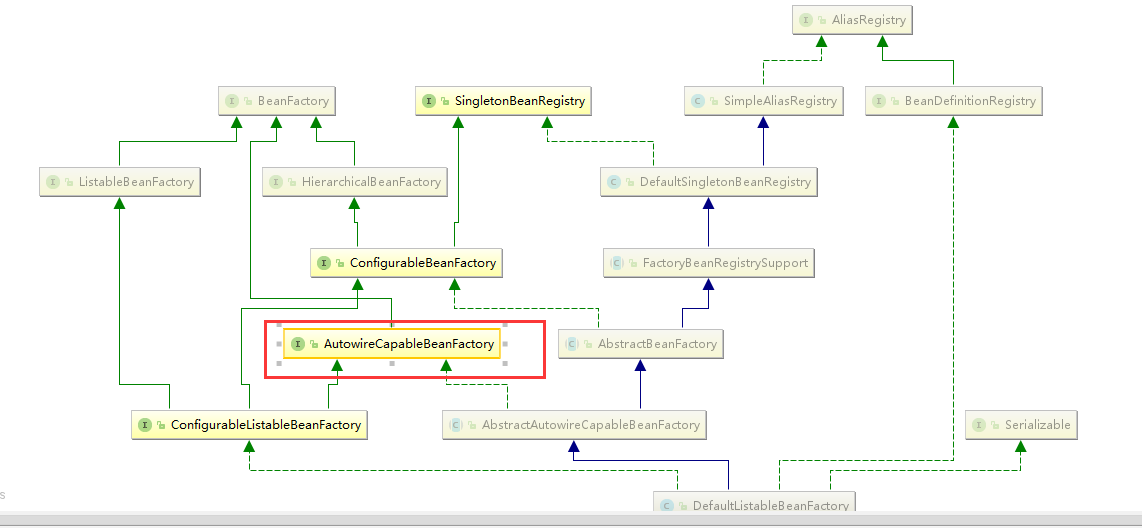 AbstractAutowireCapableBeanFactory:综合AbstractBeanFactory(抽象类)并对实现AutowireCapableBeanFactory接口
AbstractAutowireCapableBeanFactory:综合AbstractBeanFactory(抽象类)并对实现AutowireCapableBeanFactory接口
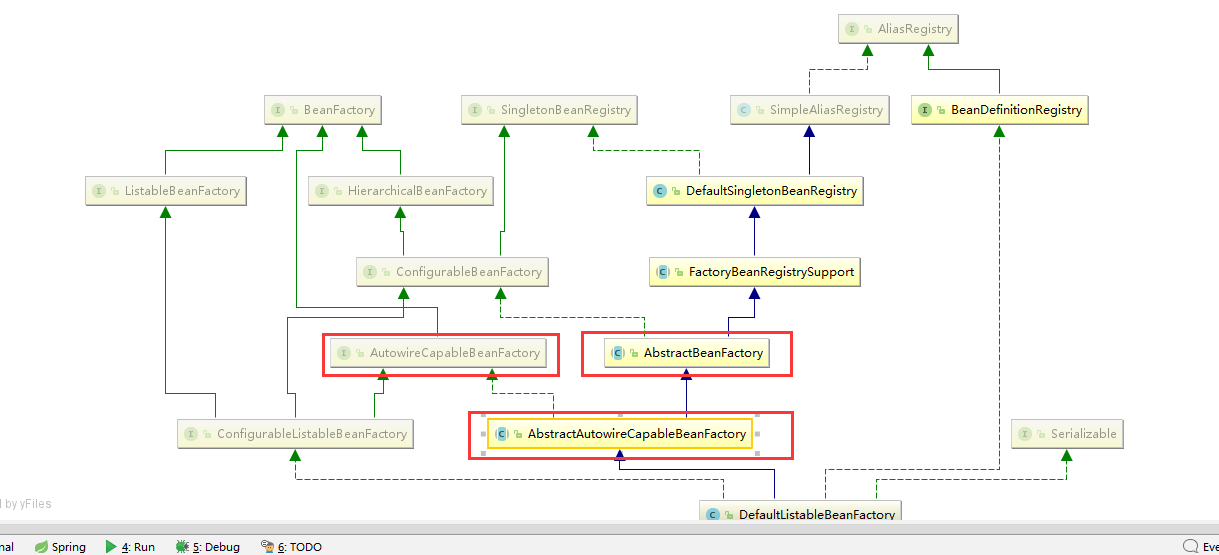
ConfigurableListableBeanFactory:BeanFactory配置清单,指定忽略类型及接口等。
 DefaultListableBeanFactory:综合上面所有功能,主要是对Bean注册后的处理,XmlBeanFactory对DefaultListableBeanFactory类进行了扩展,主要用于从XML文档中读取BeanDefinition,对于注册及获取Bean都是使用从父类DefaultListableBeanFactory继承的方法去实现,而唯独与父类不同的个性化实现就是新增了XmlBeanDefinitionReader类型的reader属性。在XmlBeanFactory中主要使用reader属性对资源文件进行读取和注册。
DefaultListableBeanFactory:综合上面所有功能,主要是对Bean注册后的处理,XmlBeanFactory对DefaultListableBeanFactory类进行了扩展,主要用于从XML文档中读取BeanDefinition,对于注册及获取Bean都是使用从父类DefaultListableBeanFactory继承的方法去实现,而唯独与父类不同的个性化实现就是新增了XmlBeanDefinitionReader类型的reader属性。在XmlBeanFactory中主要使用reader属性对资源文件进行读取和注册。
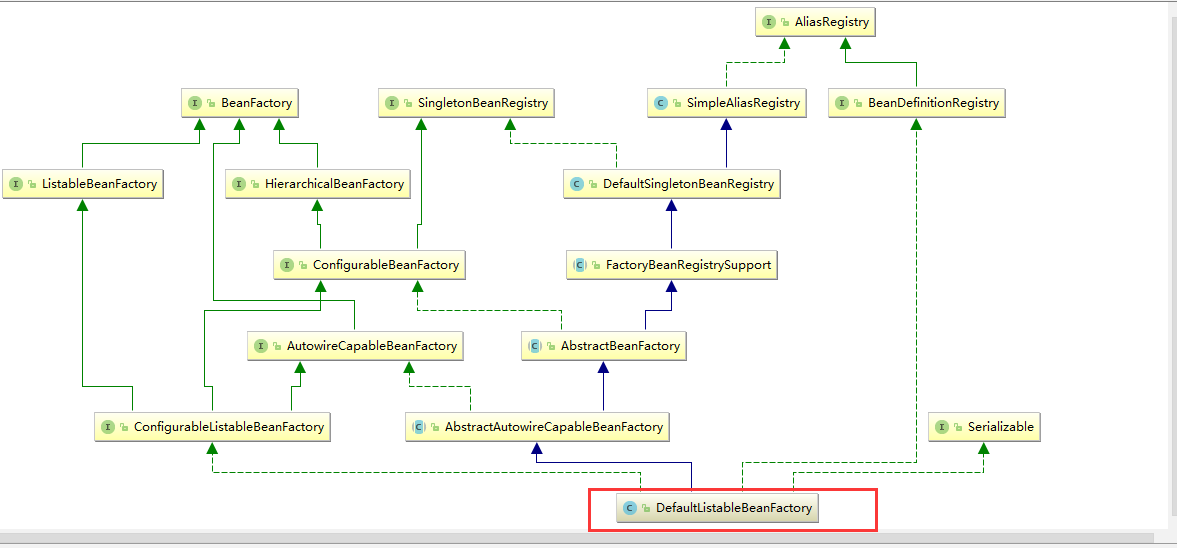
XmlBeanDefinitionReader(XML读取器):
XML配置文件是读取是Spring中重要的功能,因为Spring的大部分功能都是以配置作为切入点,我们可以从XmlBeanDefinitionReader中梳理一下资源文件读取,解析及注册的大致脉络
各个类的功能:
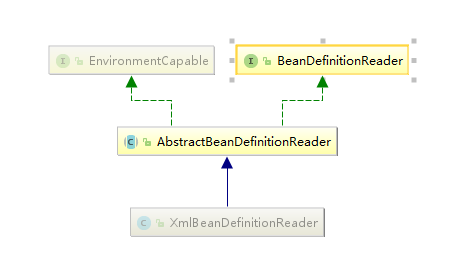
EnvironmentCapable:定义获取Environment方法
BeanDefinitionReader:主要定义资源文件读取并转换为BeanDefinition的各个功能
ResourceLoader:定义资源加载器,主要应用于根据给定的资源文件地址返回对应的Resource。
DocumentLoader:定义从资源文件加载到转换为Document的功能
AbstractBeanDefinitionReader:对EnvironmentCapable,BeanDefinitionReader类定义的功能进行实现
XML配置文件读取大致流程:
1、通过继承自AbstractBeanDefinitionReader中的方法,来使用ResourceLoader将资源文件路径转为对应的Resource文件
2、通过DocumentLoader对Resource文件进行转换,将Resource文件转换为Document文件
3、通过视BeanDefinitionDocumentReader的DefaultBeanDefinitionDocumentReader类对Document进行解析,并使用BeanDefinitionParserDelegate对Element进行解析
功能代码实现:
new XmlBeanFactory(new ClassPathResource("spring-config.xml"))
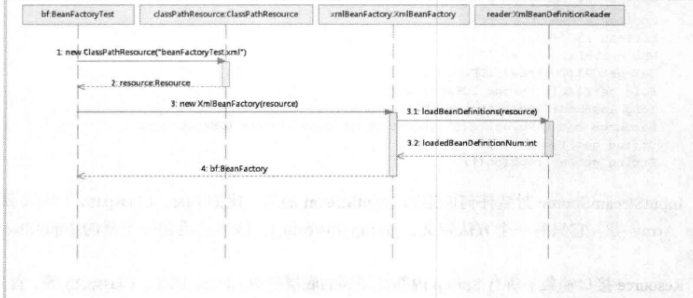
从时序图BeanFactoryTest测试类开始,通过时序图可以一目了然的看到整个逻辑处理顺序,在测试的BeanFactoryTest中首先调用ClassPathResource的构造函数来构造Resource资源文件的实例对象,这样后续的资源处理就可以用Resource提供的各种服务来操作了,当有了Resource后就可以进行XmlBeanFactory的初始化了,Resource资源是如何封装的呢?
配置文件封装
Spring的配置文件读取是通过ClassPathResource进行封装的,如new ClassPathResource("spring-config.xml"),那么ClassPathResource完成了什么功能呢?
在Java中,将不同来源的资源抽象成URL,通过注册不同的handler(URLStreamHandler)来处理不同来源的资源的读取逻辑,一般handler的类型使用不同前缀(协议,Protocol)来识别,如“file:”、“http:”、“jar:”、等,然而URL没有默认定义相同Classpath或ServletContext等资源的handler,虽然可以做注册自己的URLStreamHandler来解析特定的URL前缀(协议),比如“classpath:”,然而这需要了解URL的实现机制,而且URL也没有提供一些基本的方法,如检查当前资源是否存在,检查当前资源是否可读等方法,因而Spring对其内部使用到的资源实现了自己的抽象结构:Resource接口来封装底层资源。
InputStreamSource封装任何能返回InputStreamSource 的类,比如File,Classpath下的资源和Byte Array等。它只有一个方法定义:getInputStream(),
该方法返回一个新的InputStream对象
public interface InputStreamSource { InputStream getInputStream() throws IOException; }
Resource接口抽象了所有Spring内部使用到的底层资源:File,URL,Classpath等。首先它定义了3个判断的昂前资源状态的方法:存在性(exists)、可读性(isReadable),是否处于打开状态(isOpen)。另外,Resource接口还提供了不同资源到URL、URI、File类型的转换,以及获取获取lastModified属性、文件名(不带路径信息的文件名,getFilename())的方法。为了便于操作,Resource还提供了基于当前资源创建一个相对资源的方法:createRelative()。在错误处理中需要详细地打印错误的资源文件,因而Resource还提供了getDescription()方法用于在错误处理中的打印信息。
public interface Resource extends InputStreamSource {
//是否存在 boolean exists(); //是否可读性 boolean isReadable(); //是否处于打开状态 boolean isOpen(); URL getURL() throws IOException; URI getURI() throws IOException; File getFile() throws IOException; long contentLength() throws IOException; long lastModified() throws IOException; //基于当前资源创建一个相对资源的方法 Resource createRelative(String var1) throws IOException; //不带路径信息的文件名 String getFilename(); //错误处理中的打印信息 String getDescription(); }
对于不同来源的资源文件都有相应的Resource实现:
1、文件(FileSystemResource) 2、Classpath资源(ClassPathResource)3、URL资源(UrlResource)

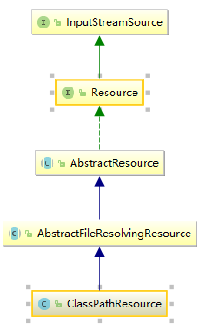
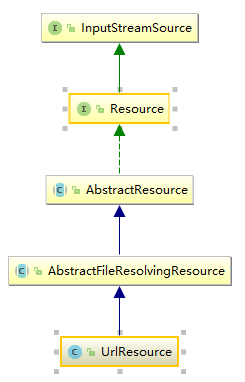
4、InputStream资源(InputStreamSource)
5、Byte数组(InputStreamSource)
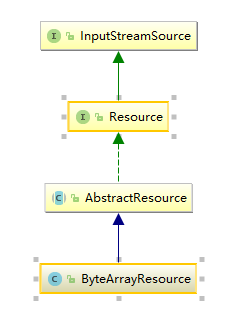
当通过Resource相关类完成了对配置文件进行装封后配置文件的读取工作就全权交给XmlBeanDefinitionReader来处理了。了解了Spring中将配置文件封装为Resource类型的实例方法后,继续看XmlBeanFactory的初始化,XmlBeanFactory的初始化有若干方法,Spring中提供了很多构造函数,在这里分析的是使用Resource实例作为构造方法参数的方法
public XmlBeanFactory(Resource resource) throws BeansException { this(resource, (BeanFactory)null); }
构造方法内部再调用内部构造方法
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException { super(parentBeanFactory); this.reader = new XmlBeanDefinitionReader(this); this.reader.loadBeanDefinitions(resource); }
上面方法中的代码:this.reader.loadBeanDefinitions(resource);才是真正的资源加载实现,时序图中提到的XmlBeanDefinitionReader加载数据就是在这里完成的
 XmlBeanDefinitionReader加载数据前还有一个调用父级构造方法初始化的过程,跟踪到父类的构造方法中
XmlBeanDefinitionReader加载数据前还有一个调用父级构造方法初始化的过程,跟踪到父类的构造方法中
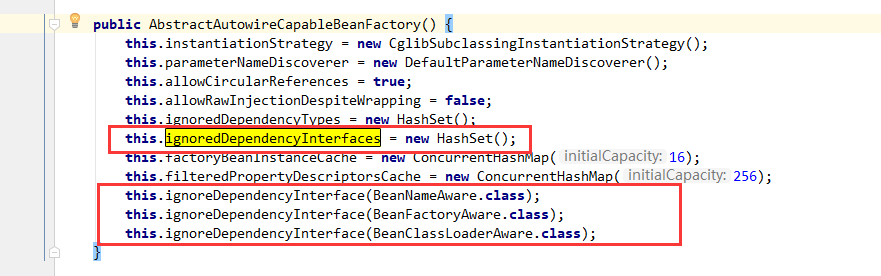 ignoredDependencyInterfaces主要功能是忽略给定接口的自动装配功能,这样做的目的是什么呢?会产生什么样的效果呢?
ignoredDependencyInterfaces主要功能是忽略给定接口的自动装配功能,这样做的目的是什么呢?会产生什么样的效果呢?
举个例子,当A中有属性B,那么当Spring在获取A的Bean的时候如果其属性B还没有初始化,那么Spring会自动初始化B,这也是Spring中提供的一个重要特性。但是某些情况下,B不会被初始化,其中一种情况就是B实现了BeanNameAware接口。Spring中是这样介绍的:自动装备时忽略给定的依赖接口,典型应用是通过其他方式解析,Application上下文注册依赖,类似于BeanFactory通过BeanFactoryAware进行注入或者ApplicationContext通过ApplicationContextAware进行注入
加载Bean
之前提到的在XmlBeanFactory构造方法中调用XmlBeanDefinitionReader类型的reader属性提供的方法this.reader.loadBeanDefinitions(resource),这行代码是整个资源加载的切入点。看一下时序图:
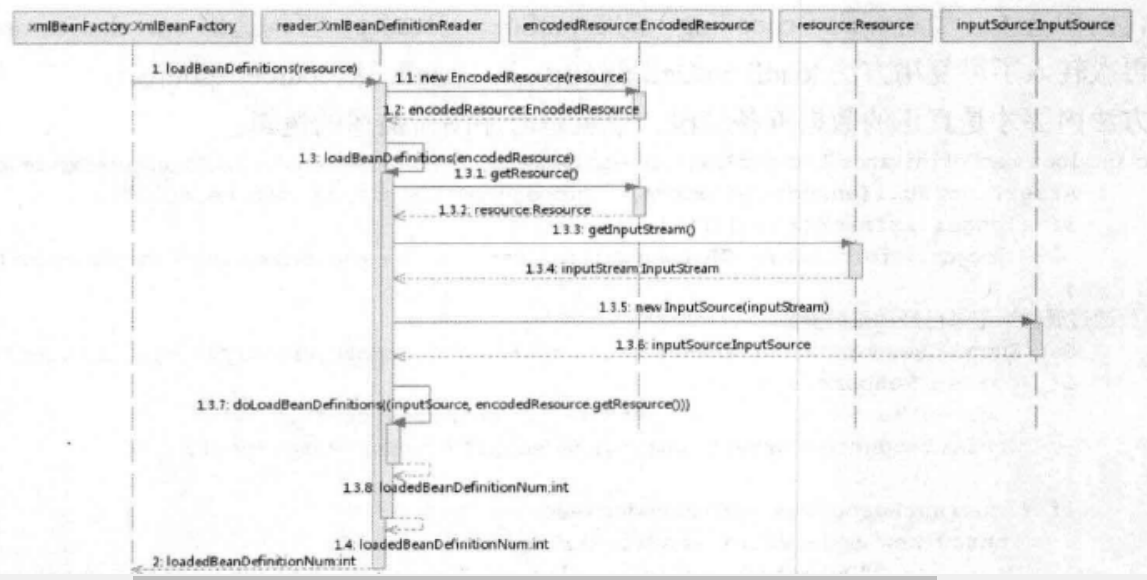
根据时序图进行梳理
1、封装资源文件。当进入XmlBeanDefinitionReader后,首先对参数Resource使用EncodedResource类进行封装

2、获取输入流,从Resource中获取对应的InputStream并构造inputSource。
3、通过构造的inputSource实例和Resource实例继续调用doLoadBeanDefinitions。看doLoadBeanDefinitions的具体实现
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource) throws BeanDefinitionStoreException { try { Document doc = this.doLoadDocument(inputSource, resource); return this.registerBeanDefinitions(doc, resource); } catch (BeanDefinitionStoreException var4) { throw var4; } catch (SAXParseException var5) { throw new XmlBeanDefinitionStoreException(resource.getDescription(), "Line " + var5.getLineNumber() + " in XML document from " + resource + " is invalid", var5); } catch (SAXException var6) { throw new XmlBeanDefinitionStoreException(resource.getDescription(), "XML document from " + resource + " is invalid", var6); } catch (ParserConfigurationException var7) { throw new BeanDefinitionStoreException(resource.getDescription(), "Parser configuration exception parsing XML from " + resource, var7); } catch (IOException var8) { throw new BeanDefinitionStoreException(resource.getDescription(), "IOException parsing XML document from " + resource, var8); } catch (Throwable var9) { throw new BeanDefinitionStoreException(resource.getDescription(), "Unexpected exception parsing XML document from " + resource, var9); } }
new EncodedResource 的作用是什么呢?通过名字,大致推断这个类主要用于对资源文件的编码进行处理,其中的主要逻辑体现在getReader()方法中,当设置了编码属性的时候Spring会使用相应的编码作为输入流的编码
public Reader getReader() throws IOException { if (this.charset != null) { return new InputStreamReader(this.resource.getInputStream(), this.charset); } else { return this.encoding != null ? new InputStreamReader(this.resource.getInputStream(), this.encoding) : new InputStreamReader(this.resource.getInputStream()); } }
上面代码构造了一个有编码(encoding)的InputStreamReader。当构造好encodedResource对象后,再次转入了可复用方法loadBeanDefinitions(new EncodedResource(resource))。
这个方法内部才是真正的数据准备阶段,也是时序图的逻辑顺序。
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException { Assert.notNull(encodedResource, "EncodedResource must not be null"); if (this.logger.isInfoEnabled()) { this.logger.info("Loading XML bean definitions from " + encodedResource.getResource()); } //通过属性来记录已经加载的资源 Set<EncodedResource> currentResources = (Set)this.resourcesCurrentlyBeingLoaded.get(); if (currentResources == null) { currentResources = new HashSet(4); this.resourcesCurrentlyBeingLoaded.set(currentResources); } if (!((Set)currentResources).add(encodedResource)) { throw new BeanDefinitionStoreException("Detected cyclic loading of " + encodedResource + " - check your import definitions!"); } else { int var5; try {
//从encodedResource中获取已经封装的Resource对象并再次从Resource中获取其中的inputStream InputStream inputStream = encodedResource.getResource().getInputStream(); try {
//InputSource这个类并不来自于Spring,它的全路径是org.xml.sax.InputSource InputSource inputSource = new InputSource(inputStream); if (encodedResource.getEncoding() != null) { inputSource.setEncoding(encodedResource.getEncoding()); } //真正进入了逻辑核心部分 var5 = this.doLoadBeanDefinitions(inputSource, encodedResource.getResource()); } finally {
//关闭输入流 inputStream.close(); } } catch (IOException var15) { throw new BeanDefinitionStoreException("IOException parsing XML document from " + encodedResource.getResource(), var15); } finally { ((Set)currentResources).remove(encodedResource); if (((Set)currentResources).isEmpty()) { this.resourcesCurrentlyBeingLoaded.remove(); } } return var5; } }
再次整理数据准备阶段逻辑,首先对传入的resource参数进行封装,目的是考虑到Resource可能存在编码要求的情况,其次通过SAX读取XML文件的方式来准备InputSource对象,最后将准备的数据通过参数传入真正的核心处理部分doLoadBeanDefinitions(inputSource, encodedResource.getResource());
在上面代码中如不考虑异常类的代码,其实就做了3件事,但是这3件事每件都必不可少
1、获取对XML文件的验证模式
2、加载XML文件,并得到对应的Document
3、根据返回的Document注册Bean信息。
这个3个步骤支撑着整个Spring容器部分的实现基础,尤其是第三步对配置文件的解析,逻辑非常复杂。下面对3个步骤分析:
1、获取XML的验证模式
XML文件的验证模式保证了XML文件的正确性,而比较常用的验证模式有两种DTD和XSD
DTD和XSD区别:
网上大佬的介绍:https://blog.csdn.net/ningguixin/article/details/8171581
验证模式的读取:
通过之前的分析锁定了Spring通过getValidationModeForResource方法来获取对应资源的验证模式
protected int getValidationModeForResource(Resource resource) { int validationModeToUse = this.getValidationMode();
//如果手动指定了验证模式则使用指定的验证模式 if (validationModeToUse != 1) { return validationModeToUse; } else {
//如果未指定则使用自动检测 int detectedMode = this.detectValidationMode(resource); return detectedMode != 1 ? detectedMode : 3; } }
如果设定了验证模式则使用设定的验证模式(可以通过对调用XmlBeanDefinitionReader的setValidationModeName()方法进行设定),否者使用自动检测的方式,而自动检测验证模式的功能是在方法detectValidationMode方法中实现,在detectValidationMode方法中又将自动检测验证模式的工作委托给专门的处理类XmlValidationModeDetector,调用了XmlValidationModeDetector的validationModeDetector方法:
protected int detectValidationMode(Resource resource) { if (resource.isOpen()) { throw new BeanDefinitionStoreException("Passed-in Resource [" + resource + "] contains an open stream: cannot determine validation mode automatically. Either pass in a Resource that is able to create fresh streams, or explicitly specify the validationMode on your XmlBeanDefinitionReader instance."); } else { InputStream inputStream; try { inputStream = resource.getInputStream(); } catch (IOException var5) { throw new BeanDefinitionStoreException("Unable to determine validation mode for [" + resource + "]: cannot open InputStream. Did you attempt to load directly from a SAX InputSource without specifying the validationMode on your XmlBeanDefinitionReader instance?", var5); } try { return this.validationModeDetector.detectValidationMode(inputStream); } catch (IOException var4) { throw new BeanDefinitionStoreException("Unable to determine validation mode for [" + resource + "]: an error occurred whilst reading from the InputStream.", var4); } } }
public int detectValidationMode(InputStream inputStream) throws IOException { BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream)); byte var4; try { boolean isDtdValidated = false; while(true) { String content; if ((content = reader.readLine()) != null) { content = this.consumeCommentTokens(content);
//如果读取的行是空或者是注释则略过 if (this.inComment || !StringUtils.hasText(content)) { continue; } if (this.hasDoctype(content)) { isDtdValidated = true;
//读取到<开始符号,验证模式一定会在开始符号之前 } else if (!this.hasOpeningTag(content)) { continue; } } int var5 = isDtdValidated ? 2 : 3; return var5; } } catch (CharConversionException var9) { var4 = 1; } finally { reader.close(); } return var4; }
Spring检测模式的办法就是判断是否包含DOCTYPE,如果包含就是DTD,否则就是XSD
private boolean hasDoctype(String content) { return content.contains("DOCTYPE"); }
2、获取Document
经过了验证模式准备的步骤就可以进行Document加载,委托给了DocumentLoader 去执行,这里的DocumentLoader是个接口,真正调用的是DefaultDocumentLoader:
首先创建DocumentBuilderFactory,再通过DocumentBuilderFactory创建DocumentBuilder,进而解析inputSource来返回Document对象。
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver, ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception { DocumentBuilderFactory factory = this.createDocumentBuilderFactory(validationMode, namespaceAware); if (logger.isDebugEnabled()) { logger.debug("Using JAXP provider [" + factory.getClass().getName() + "]"); } DocumentBuilder builder = this.createDocumentBuilder(factory, entityResolver, errorHandler); return builder.parse(inputSource); }
EntityResolver 类型的entityResolver参数,传入的是通过this.getEntityResolver()方法获取的返回值
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception { return this.documentLoader.loadDocument(inputSource, this.getEntityResolver(), this.errorHandler, this.getValidationModeForResource(resource), this.isNamespaceAware()); }
protected EntityResolver getEntityResolver() { if (this.entityResolver == null) { ResourceLoader resourceLoader = this.getResourceLoader(); if (resourceLoader != null) { this.entityResolver = new ResourceEntityResolver(resourceLoader); } else { this.entityResolver = new DelegatingEntityResolver(this.getBeanClassLoader()); } } return this.entityResolver; }
EntityResolver是做什么用的?
官网解释:如果SAX应用程序需要实现自定义处理外部实体,则必须实现此接口并使用setEntityResolver方法向SAX驱动器注册一个实例。
也就是说,对于解析一个XML,SAX首先读取该XML文件上的声明,根据声明去寻找相应的DTD定义,以便对文档进行一个验证。默认的寻找规则,
即通过网络(实现上就是声明的DTD的URL地址)来下载相应的DTD声明,并进行认证。下载过程是很漫长的过程,而且当网络中断或不可用时,这里会报错,
就是因为相应的DTD声明没有被找到的原因。
EntityResolver的作用是项目本身就可以提供一个如何寻找DTD声明的方法,即由程序来实现寻找DTD声明的过程,比如我们将DTD文件放到项目中某处,
在实现时直接将此文档读取并返回给SAX即可。这样就避免了通过网络来寻找相应的声明。
首先看EntityResolver接口声明,它接受2个参数publicId和systemId并返回一个InputSource对象
public abstract InputSource resolveEntity (String publicId,String systemId)throws SAXException, IOException;
这里我们以特定配置文件来进行讲解。
1、我们在解析验证模式为XSD的配置文件
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> </beans>
读取到一下2个参数:
publicId:null
systemId:http://www.springframework.org/schema/beans/spring-beans.xsd

验证文件默认的加载方式是通过URL进行网络下载获取,这样会造成延迟,用户体验不好,一般的做法都是将验证文件放置在自己的工程里,那么怎么做才能将这个URL转换为自己工程里对应的地址文件呢?根据之前Spring中通过this.getEntityResolver()对EntityResolver的获取,Spring中使用DelegatingEntityResolver类为entityResolver的实现类,resolveEntity实现方法:
public InputSource resolveEntity(String publicId, String systemId) throws SAXException, IOException { if (systemId != null) {
//解析DTD if (systemId.endsWith(".dtd")) { return this.dtdResolver.resolveEntity(publicId, systemId); } //解析XSD if (systemId.endsWith(".xsd")) { return this.schemaResolver.resolveEntity(publicId, systemId); } } return null; }
对不同的验证模式,Spring使用了不同的解析器解析,加载DTD类型的BeansDtdResolver的resolveEntity是直接截取systemId最后的xx.dtd然后去当前路径下寻找,而加载XSD类型的schemaResolver类的resolveEntity是默认到META-INF/Spring.schemas文件中找到systemid所应对的XSD文件并加载
public InputSource resolveEntity(String publicId, String systemId) throws IOException { if (logger.isTraceEnabled()) { logger.trace("Trying to resolve XML entity with public ID [" + publicId + "] and system ID [" + systemId + "]"); } if (systemId != null && systemId.endsWith(".dtd")) { int lastPathSeparator = systemId.lastIndexOf(47); int dtdNameStart = systemId.indexOf("spring-beans", lastPathSeparator); if (dtdNameStart != -1) { String dtdFile = "spring-beans-2.0.dtd"; if (logger.isTraceEnabled()) { logger.trace("Trying to locate [" + dtdFile + "] in Spring jar on classpath"); } try { Resource resource = new ClassPathResource(dtdFile, this.getClass()); InputSource source = new InputSource(resource.getInputStream()); source.setPublicId(publicId); source.setSystemId(systemId); if (logger.isDebugEnabled()) { logger.debug("Found beans DTD [" + systemId + "] in classpath: " + dtdFile); } return source; } catch (IOException var8) { if (logger.isDebugEnabled()) { logger.debug("Could not resolve beans DTD [" + systemId + "]: not found in classpath", var8); } } } } return null; }
3、解析及注册BeanDefintions
当把文件转为为Document后,当程序已经拥有XML文档文件的Document实例对象时,就会引入下面这个方法
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
//DefaultBeanDefinitionDocumentReader实例化BeanDefinitionDocumentReader
BeanDefinitionDocumentReader documentReader = this.createBeanDefinitionDocumentReader();
//在实例化BeanDefinitionDocumentReader时候会将BeanDefinitionRegistry传入,默认使用继承自DefaultListtableBeanFactory的子类
//记录统计前BeanDefinition的加载个数
int countBefore = this.getRegistry().getBeanDefinitionCount();
//加载及注册bean documentReader.registerBeanDefinitions(doc, this.createReaderContext(resource));
//记录本次加载的BeanDefinition个数 return this.getRegistry().getBeanDefinitionCount() - countBefore; }
其中的参数doc是通过上一节doLoadDocument加载转换出来的。

在这个方法中很好的应用了面向对象中单一职责的原则,将逻辑处理委托给单一的类进行处理,而这个逻辑处理类就是BeanDefinitionDocumentReader,BeanDefinitionDocumentReader是一个接口,而实例化的工作是在createBeanDefinitionDocumentReader()中完成的,而通过此方法,BeanDefinitionDocumentReader真正的类型其实已经是DefaultBeanDefinitionDocumentReader,进入DefaultBeanDefinitionDocumentReader后,发现这个方法的重要目的之一就是提取root,以便再次将root作为参数继续BeanDefinition的注册。
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) { this.readerContext = readerContext; this.logger.debug("Loading bean definitions"); Element root = doc.getDocumentElement(); this.doRegisterBeanDefinitions(root); }
核心部分:
protected void doRegisterBeanDefinitions(Element root) {
//专门处理解析 BeanDefinitionParserDelegate parent = this.delegate; this.delegate = this.createDelegate(this.getReaderContext(), root, parent); if (this.delegate.isDefaultNamespace(root)) { String profileSpec = root.getAttribute("profile");//处理profile属性 if (StringUtils.hasText(profileSpec)) { String[] specifiedProfiles = StringUtils.tokenizeToStringArray(profileSpec, ",; "); if (!this.getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) { if (this.logger.isInfoEnabled()) { this.logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec + "] not matching: " + this.getReaderContext().getResource()); } return; } } } //解析前处理,留给子类实现 this.preProcessXml(root); this.parseBeanDefinitions(root, this.delegate);
//解析后处理,留给子类实现 this.postProcessXml(root); this.delegate = parent; }
上面代码处理流程,首先是对profile的处理,然后开始解析,可是当我们跟进preProcessXml(root)或者postProcessXml(root)发现代码是空的,既然是空的写着还有什么用呢?就像面向对象设计方法学中常说的一句话,一个类要么是面向继承的设计的,要么就用final修饰,在DefaultBeanDefinitionDocumentReader中并没有用final修饰,所以它是面向继承而设计的。这两个方法正式为子类而设置的,这个是模板方法模式,如果继承自DefaultBeanDefinitionDocumentReader的子类需要在Bean解析前后做一些处理的话,那么只需要重写这两个方法即可。
profile属性并不是很常用,先了一下profile的用法

有了这个特性我们就可以同时在配置文件中部署两套配置来适用于生产环境和开发环境,这样就可以方便的进行切换,部署环境,最常用的就是更换不同的数据库。
了解了profile的使用再来分析代码会清晰得多,首先程序会获取beans节点是否定义了profile属性,如果定义了则会需要到环境变量中去寻找,所以这里首先断言environment不可能为空,因为profile是可以同时指定多个的,需要程序对其拆分,并解析每个profile都是符合环境变量中所定义的,不定义则不会浪费性能去解析。
解析并注册BeanDefinition
处理了profile后就可以进行XML的读取了,跟踪代码进入parseBeanDefinitions方法中
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) { if (delegate.isDefaultNamespace(root)) {//对beans的处理 NodeList nl = root.getChildNodes(); for(int i = 0; i < nl.getLength(); ++i) { Node node = nl.item(i); if (node instanceof Element) { Element ele = (Element)node; if (delegate.isDefaultNamespace(ele)) { this.parseDefaultElement(ele, delegate);//对bean的处理 } else { delegate.parseCustomElement(ele);//对bean的处理 } } } } else { delegate.parseCustomElement(root); } }
在Spring的XML配置有两大类Bean声明:
一个是默认的,如:<bean id="myTestBean" class="com.lkeji.demo.MyTestBean" ></bean>
一个是自定义,如:<tx:annotation-driven />
这两种的读取及解析差别是非常大的,如果采用Spring默认的配置,Spring当然知道该怎么做,如果是自定义的,那么需要用户实现一些接口及配置了,对于根结点或者子节点如果是默认命名空间的话则采用parseDefaultElement方法进行解析,否者使用delegate.parseCustomElement方法对自定义命名空间进行解析。而判断是否默认命名空间还是自定义命名空间的办法其实是使用node.getNamespaceURI()获取命名空间,并与Spring中固定的命名空间http://www.springframework.org/schema/beans进行对比,如果一致则认为是默认,否则就认为是自定义。而对于默认标签解析与自定义标签解析将在下一篇学习