Mysql和SQLyog安装见我的另外一篇博客https://www.cnblogs.com/ljy1227476113/p/11947066.html
爬虫思路基本是按照我的博客https://www.cnblogs.com/ljy1227476113/p/10913508.html
python中关于excel有两个基本的库
读取 xlrd
写入 xlwt
话不多说直接上代码
1 import xlrd#读取excel 2 import xlwt#写入excel 3 import MySQLdb 4 import requests 5 import linecache 6 import random 7 from bs4 import BeautifulSoup 8 9 if __name__=="__main__": 10 f = xlwt.Workbook(encoding='utf-8') #创建工作簿 11 sheet1 = f.add_sheet(u'sheet1') #创建sheet 12 row0 = [u'ID',u'name',u'tref',u'comment_num'] 13 #生成第一行 14 for i in range(0,len(row0)): 15 sheet1.write(0,i,row0[i]) 16 17 n=0#ID编号 18 target='https://www.cnblogs.com/'#博客园首页 19 user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36' 20 headers = {'User-Agent':user_agent} 21 22 req=requests.get(url=target) 23 html=req.text 24 html=html.replace('<br>',' ').replace('<br/>',' ').replace('/>','>') 25 bf=BeautifulSoup(html,"html.parser") 26 texts=bf.find_all('div',class_='post_item_body') 27 #texts_div=texts.find_all('div',class_='wz_content') 28 for item in texts: 29 n=n+1 30 item_name=item.find('a').text#标题 31 item_href=item.find('a')['href']#链接 32 item_refer2=item.find('span',class_='article_comment').text#评论数 33 print('{} {} {} '.format(item_name,item_href,item_refer2)) 34 mid=[n,item_name,item_href,item_refer2] 35 for i in range(4):#写入excel 36 sheet1.write(n,i,mid[i]) 37 print("Done!") 38 f.save('demo1.xls') #保存文件 39 40 book = xlrd.open_workbook("demo1.xls")#打开excel 41 sheet = book.sheet_by_name("sheet1") 42 #建立一个MySQL连接 43 database = MySQLdb.connect (host="localhost", user = "root", passwd = "111111", db = "mysql") 44 # 获得游标对象, 用于逐行遍历数据库数据 45 cursor = database.cursor() 46 # 创建插入SQL语句 47 query = """INSERT INTO mypython VALUES (%s, %s, %s, %s)""" 48 # 创建一个for循环迭代读取xls文件每行数据的, 从第二行开始是要跳过标题 49 for r in range(1, sheet.nrows): 50 product = sheet.cell(r,0).value 51 customer = sheet.cell(r,1).value.encode()#python3中string格式要encode() 52 rep = sheet.cell(r,2).value.encode() 53 date = sheet.cell(r,3).value.encode() 54 55 values = (0, customer, rep, date) 56 # 执行sql语句 57 cursor.execute(query, values) 58 # 关闭游标 59 cursor.close() 60 # 提交 61 database.commit() 62 # 关闭数据库连接 63 database.close() 64 # 打印结果 65 print("All Done! ")
接下来按照代码的顺序讲一下思路、遇到的问题和解决方案
在创建工作簿的sheet1(第11行时),名字必须与后续一致(第41行)
爬取博客园首页时,按照在网页内查找元素的方式
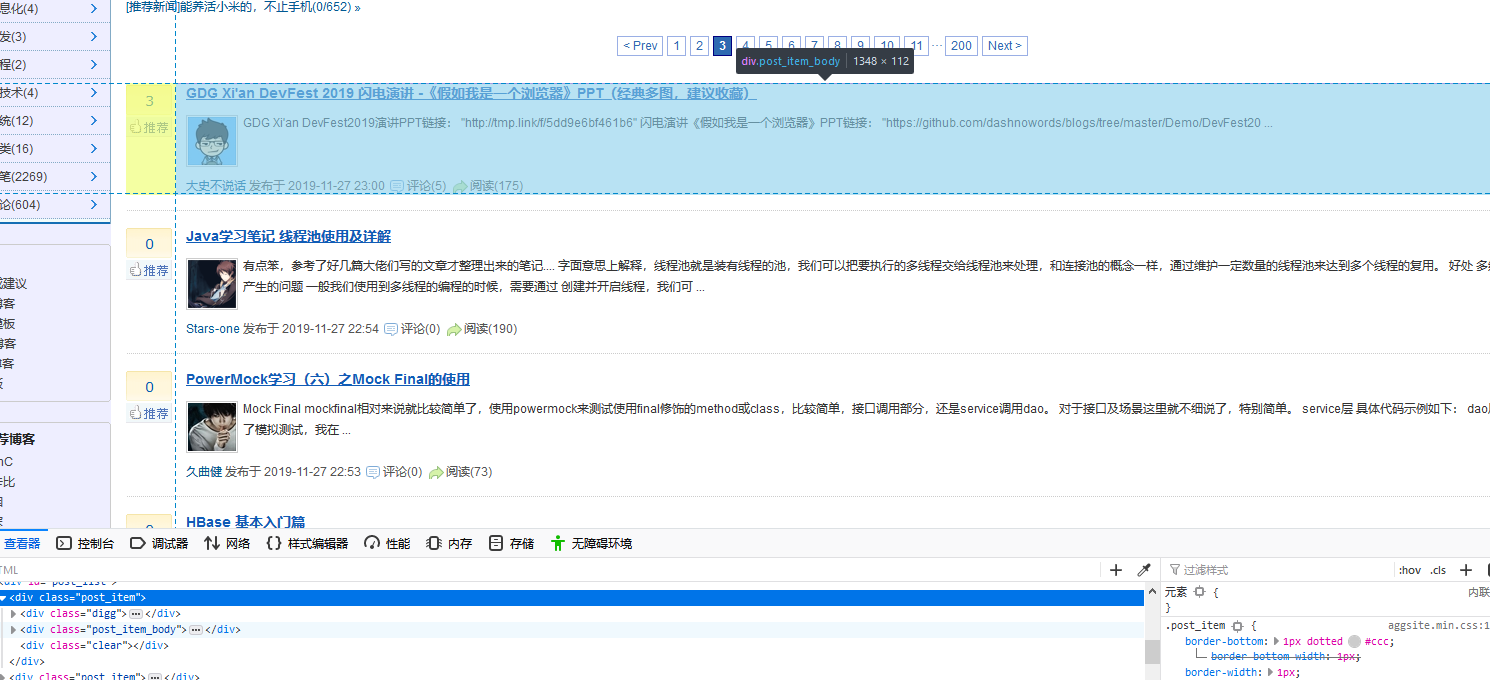
这就是第26行div的class属性值的来源
连接数据库(第43行)时,选择的数据库必须正确
同理第47行选择的表格也必须正确
我这里用的是“mysql”数据库,“mypython”表格
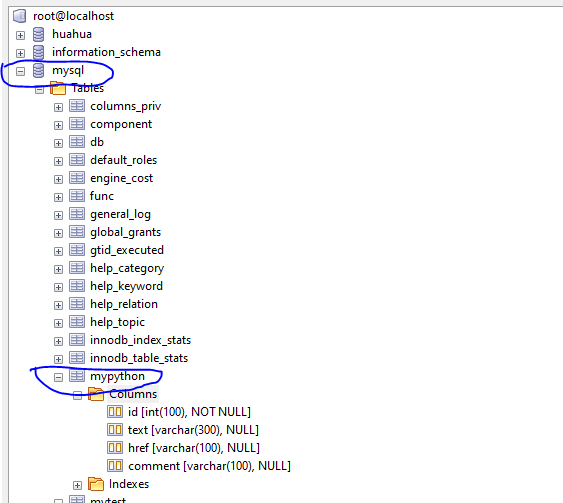
在mypython中键必须与爬取的值、excel表格中的行一一对应
这里我读取的是标题、链接和评论数,写入的多了一个ID值
在excel值用n自增的形式,mysql中用主键自增的形式

需要注意的是,在把excel表格中的值写入mysql中时要进行解码,而python3中的string默认是非解码形式
所以需要在string类型值的后面加个encode()

运行结果如图所示
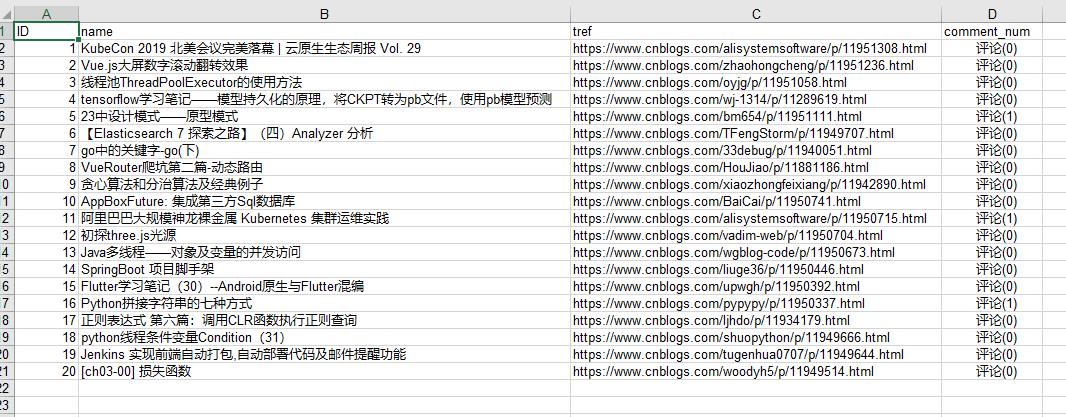
mysql中用SQLyog打开
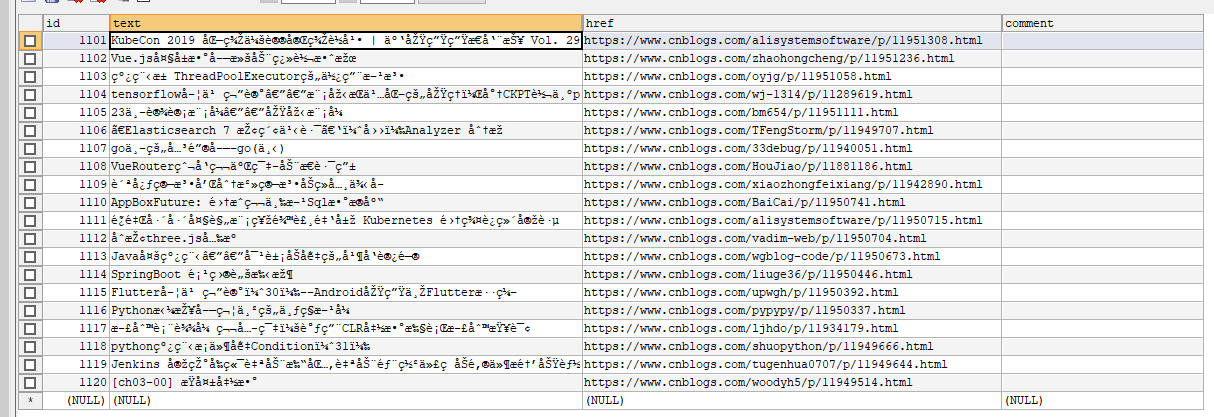
看这帅气的乱码
id从1101开始是因为id是主键自增,而我之前做测试已经爬取了1100条信息,删除之后主键还是从1101开始
要避免这种情况最快的当然是删除表格重新创建
顺便说一句sqlyog中批量删除行数据只要点击最左面那个小框,再按住shift点击要下拉的行小框就能批量删除

最后中文乱码的问题是本机问题
一般情况不会出现的···
END
python爬虫、tk界面编写参考资料:
Python3网络爬虫快速入门实战解析(一小时入门 Python 3 网络爬虫)_Python_u012662731的博客-CSDN博客
https://blog.csdn.net/u012662731/article/details/78537432
教你用Python写界面_python_流月的博客-CSDN博客
https://blog.csdn.net/qq_37482202/article/details/84201259
Python学习三: 爬虫高级技巧 与 模拟实战练习_Python_Alan-CSDN博客
https://blog.csdn.net/qq_33081367/article/details/81564373
Python-定向爬虫的简单使用 - 简书
https://www.jianshu.com/p/3f6a26ca6031
Python爬虫百度搜索标题_Python_疯狂程序员-CSDN博客
https://blog.csdn.net/wuzhilong277832060/article/details/80310450
Python GUI之tkinter窗口视窗教程大集合(看这篇就够了) - 洪卫 - 博客园
https://www.cnblogs.com/shwee/p/9427975.html
python开发_tkinter_修改tkinter窗口的红色图标'Tk' - Hongten - 博客园
https://www.cnblogs.com/hongten/p/hongten_tkinter_logo.html
Kr1s77/Python-crawler-tutorial-starts-from-zero: python爬虫教程,带你从零到一,包含js逆向,selenium, tesseract OCR识别,mongodb的使用,以及scrapy框架
https://github.com/Kr1s77/Python-crawler-tutorial-starts-from-zero