数据重塑通常使用reshape2包,reshape2包用于实现对宽数据及长数据之间的相互转换,由于reshape2包不在R的默认安装包列表中,在第一次使用之前,需要安装和引用:
install.packages("reshape2")
library(reshape2)
重塑数据,首先把宽数据融合(melt),以使每一行都只表示一个变量,然后把数据重塑(cast)为想要的任何形状。在重塑过程中,可以使用任何函数对数据进行整合,也可以把长格式转换为宽格式,这种操作类似于Excel的透视和逆透视。
一,认识宽数据
在同一行,标识变量(一列或多列)能够唯一标识两个或多个变量的值,这种数据显示叫做数据的宽格式,也叫做宽数据:

创建示例数据,ID和Time的组合是唯一的,X1和X2是该行的观测变量值,
> ID <- c(1,1,2,2)
> Time <- c(1,2,1,2)
> X1 <- c(5,3,6,2)
> X2 <-c(6,5,1,4)
> mydata <- data.frame(ID,Time,X1,X2)
如下所示宽格式的数据,ID和Time的组合是唯一的,同一行有两个变量X1和X2,通过ID和Time能够唯一确定变量X1和X2的值:
ID Time X1 X2 1 1 1 5 6 2 1 2 3 5 3 2 1 6 1 4 2 2 2 4
二,融合数据
数据的融合是指把数据集重塑为特定的格式,使得每个观测变量独占一行,每行都有唯一确定每个观测变量所需要的标识变量。融合之后的数据,称作长格式,也叫作长数据。
原始数据中,主键列唯一确定variable1和variable2的值,在融合之后,如下图所示,主键列和variable列(变量名)唯一确定value列的值。

在R语言中,使用melt()函数来融合数据:
melt(data,id.vars,measure.vars,variable.name='variable',...,na.rm=FALSE,value.name='value',factorAsStrings=TRUE)
参数注释:
- data:融合的数据框
- id.vars:由标识变量构成的向量,用于标识观测的变量
- measure.vars :由观测变量构成的向量
- variable.name:用于保存原始变量名的变量的名称
- value.name:用于保存原始值的名称
示例,标识变量是ID和Time,X1和X2作为观测变量:
md <- melt(mydata,id=c("ID","Time"),measure=c("X1","X2"))
数据融合之后,变成长数据,长数据的特征是 ID列(多列或单列)+ 变量名 唯一确定变量的值,并且每一行只能确定一个变量的值。
ID Time variable value 1 1 1 X1 5 2 1 2 X1 3 3 2 1 X1 6 4 2 2 X1 2 5 1 1 X2 6 6 1 2 X2 5 7 2 1 X2 1 8 2 2 X2 4
注意:必须指定唯一确定每个观测所需的变量(ID和Time),而表示观测变量名的变量(X1和X2)由程序自动创建,从结果中可以看出,函数自动创建了两个变量:variable和value,这两个变量名称是默认的,这可以在melt()函数中,通过参数 variable.name="new_variable_name"和 value.name="new_value_name"来自定义。
md <- melt(mydata,id=c("ID","Time"),measure=c("X1","X2"),variable.name = "MeasuredVariable",value.name = "IntValue")
三,重塑数据
dcast()函数用于读取已融合的数据框(d是指data frame),并使用formula和用于整合数据的函数把数据集重塑成任意形状:
dcast(data, formula, fun.aggregate = NULL, ..., margins = NULL,
subset = NULL, fill = NULL, drop = TRUE, value.var = guess_value(data))
参数注释:
- data:已融合的数据框
- formula:用于指定输出的结果集格式
- fun.aggregate:用于指定聚合函数,对已聚合的数据执行聚合运算
- margins:相当于透视表中的行总计和列总计
- subset:选取满足一些特定值的数据,相当于Excel透视表的筛选。例如, subset =.(variable ==“length”)
- fill:用于填充结构缺失的值,默认为将fun.aggregate应用于0长度向量的值
- value:value列的名称
参数formula的格式是:
rowvar1 + rowvar2 +... ~ colvar1 + colvar2 +...
在该公式中,rowvar 定义了保留的变量名,以唯一确定各行的内容;colvar定义了需要重塑的变量名,以确定各列的值。重塑的含义是:按照rowvar,展开colvar,对value进行聚合运算(当fun.aggregate为聚合函数时)。
1,展开colvar
展开colvar的过程,实际上是把列值转换为列名称的过程,这种展开操作是由formula参数决定的。
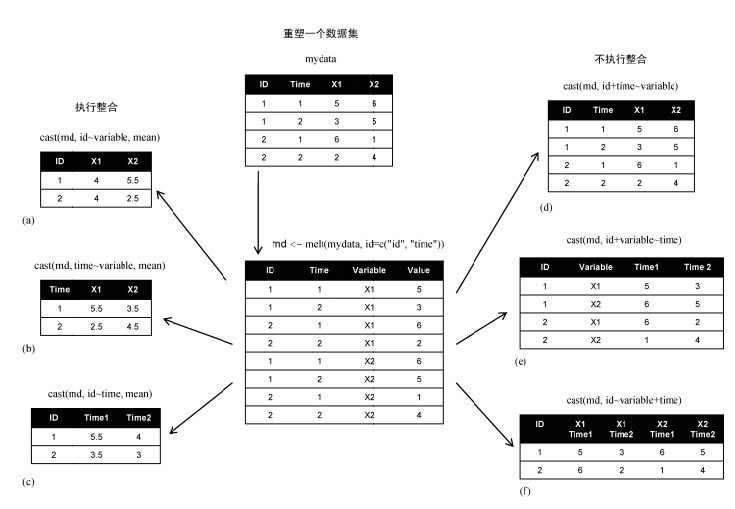
重塑操作中的特例是数据融合的逆操作,把数据的长格式转化为数据的宽格式,即,把已融合的数据转换为原始数据格式,对于这种操作,formula参数的格式是固定的:标识变量~variable。
> dcast(md,ID+Time~variable)
ID Time X1 X2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
2,对观测变量进行聚合运算
按照ID,计算观测变量的平均值:
> dcast(md,ID~variable,mean)
ID X1 X2
1 1 4 5.5
2 2 4 2.5
这种操作,类似于分组聚合:按照ID进行分组,分别计算变量X1和X2的聚合值。
3,添加总计列
计算按照ID分组的X1和X2的均值,并对重塑的结果按照ID计算各列均值,按照X1和X2计算各行的均值。
> dcast(md,ID~variable,mean,margins = c("ID","variable")) ID X1 X2 (all) 1 1 4 5.5 4.75 2 2 4 2.5 3.25 3 (all) 4 4.0 4.00
计算的过程是:
按照ID计算各列的均值: X1的值是(5.5+2.5)/2=4
按照变量计算各行的均值:第一行的均值是 (4+5.5)/2=4.75
示例图:
参考文档: