PowerBI报表是基于数据分析的引擎,数据真正的来源(Data Source)是数据库,文件等数据存储媒介,PowerBI支持的数据源类型多种多样。PowerBI Service(云端)有时不直接访问Data Source,而是直接从PowerBI Service创建的数据集(Dataset)中获取数据,数据集中存储的内容主要分为三部分:Data Source的数据(Data)、连接数据源的凭证(Credentials)、以及数据源的架构(Table Schema)等元数据(metadata)。PowerBI Service分析数据时,直接访问Dataset获取数据,执行聚合计算,以响应用户的查询请求。使用Dataset的好处是:PowerBI只需要维护统一的Data Store,不需要从众多不同的DataSource中读取数据,所需要的数据都能从单一的数据结构(Dataset)中读取。
PowerBI Service为每个发布的Report自动创建一个Dataset,每一个Dataset的大小的上限是1GB。在导入(Import)连接模式下,PowerBI把多个Data Source的数据导入到Dataset中,也就是说,Dataset存储的是多个数据源(Data Source)的快照。是否把数据源导入到Dataset,是由数据连接(Data Connection Model)决定的。
我的PowerBI开发系列的文章目录:PowerBI开发
一,数据连接模式
当使用“Get Data”连接到Data Source时,PowerBI 自动创建Dataset,把数据从多个Data Source加载到一个Dataset中,Dataset还包含连接Data Source的凭证(Credentials),以及数据的架构等元数据。PowerBI Service直接从Dataset中引用数据,而不是直接从Data Source中。PowerBI支持的连接模式有两种,分别是:Import,Live/DirectQuery。导入(Import)模式把Data Source的数据导入到PowerBI Service的Dataset中,而直接查询(DirectQuery)模式建立Data Source 和Dataset之间的直接连接。
1,导入(Import)模式
对于导入(Import)模式,云端的Dataset中存储的数据来源于内网(On-Premises)数据的副本,一旦加载数据源,查询定义的所有数据都会被加载到Dataset中。PowerBI从高度优化的Dataset中查询数据,查询性能高,能够快速响应用户的交互式查询。由于导入模式是把数据源快照复制到Dataset中,因此,底层数据源的改动不会实时更新到Dataset,这使得Dataset存储的数据是过时的,用户需要手动刷新或设置调度刷新,否则,Dataset的数据不会更新。数据的刷新是全量更新,而非增量。
导入模式的限制是:Dataset的最大Size是1GB。
2,直接查询(DirectQuery)模式
对于DirectQuery模式,PowerBI直接访问底层的数据源,因此数据始终是最新的。一旦加载数据,PowerBI Service不会向Dataset中加载任何数据(Data),这意味着,Dataset不存储任何数据(Data),但是,Dataset仍然会存储连接Data Source的凭证,以及数据源的元数据,用于访问底层数据源。在执行查询请求时,PowerBI Service直接把查询请求发送到原始的Data Source中去获取所需的数据。直接查询采用主动获取数据的方式,这意味着,底层数据的任何更新,不会立即反应到现有的报表展示中,用户需要刷新(Refresh)数据,但是,新的查询请求,都会使用最新的数据。
直接查询模式需要使用本地数据网管(On-Premises Data Gateway),PowerBI Service能够从云端向本地数据源(on-premises data sources)发送查询请求。当产生数据交互行为时,查询直接发送到数据库,Excel,Azure SQL DB/DW等,由于PowerBI和Data Source之间是直接连接,因此,不需要调度数据PowerBI Service的数据集(Dataset)。
Live/DirectQuery – This means there is a live connection between Power BI and the data source.
DirectQuery连接模式的好处是:
- 能够访问更大Size的Dataset:由于不需要把数据加载到Dataset中,DirectQuery模式能够从海量的数据源中加载数据;
- 直接访问数据源:在DirectQuery模式下,PowerBI使用的是最新的数据。
DirectQuery连接模式的调优:
在使用DirectQuery连接模式时,如果查询数据源的速度非常慢,以至于需要等待一段时间才能从基础数据表获得响应,那么可以在报表中设置Query reduction选项,向数据源发送更少的查询,使查询交互更快。
为了设置Query reduction选项,你需要点击 File 主菜单,点击菜单的路径是:File > Options and settings > Options,然后在CURRENT FILE目录下,选择 Query reduction 选项卡:
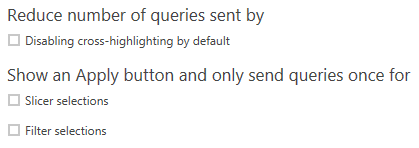
禁用默认的交叉高亮:在整个Report上禁用默认的交叉高亮显示,所谓交叉高亮,是指当用户点击Visualization上的某一行数据时,其他Visualization相关联的相关数据行也会高亮显示。在禁用交叉高亮之后,用户可以通过Visual interactions功能,手动为特定的Visual启用交叉高亮,默认情况下,是禁用交叉高亮。
在Slicer或Filer上显示一个Apply按钮:用户可以选中相应的选项,但是,只有在点击Apply按钮之后,用户选中的Slicer或Filer才会用于过滤数据。
二,数据刷新(Data Refresh)
PowerBI Service从Dataset中获取数据,用于数据分析和展示,用户可以通过"SCHEDULE REFRESH"和"REFRESH NOW"刷新Dataset的数据,把Dataset的数据更新到最新。用户刷新Dataset之前,必须配置内网数据网关(On-Premises Data Gateway),详细信息,请参考我的博文《PowerBI开发 第六章:数据网管》。PowerBI Service对数据Dataset的刷新是完整数据刷新,而不是增量数据刷新。
When you refresh data, you are updating the data in the dataset that is stored in Power BI from your data source. This refresh is a full refresh and not incremental.
当使用Import连接模式时,所有的数据都会从Data Source导入到PowerBI Service的缓存中,PowerBI的可视化控件都是从缓存中查询数据。一旦PowerBI文件发布到PowerBI Service中,PowerBI 将会创建一个Dataset,用于存储被导入的数据。设置调度,定时刷新Dataset,使得PowerBI呈现最新的分析数据,对于做出正确的决策是非常重要的。
三,连接模式的性能
推荐使用导入(Import)连接模式,这是因为PowerBI 使用内存的列式数据库 VertiPaq,用于对已发布的数据集(Dataset)进行数据压缩和快速处理,能够使PowerBI报表执行脱机访问,面向列的处理,高度优化对1:N关系的处理性能。导入模式非常适合聚合查询,特别是,当存在大量的关系时,PowerBI能够快速执行聚合运算。导入模式的缺点是Dataset的Size最大是1GB,需要调度刷新才能访问最新的数据。
直接查询(DirectQuery)模式,建立PowerBI和Data Source之间的直接连接,访问的数据始终是最新的,并且数据源的大小是无限制的。在直接查询模式下,PowerBI直接发送查询到Datasource中,以获取所需要的数据。当Data Source是关系型数据库时,PowerBI直接发送SQL查询语句到数据库中。直接查询模式的最大缺点是性能问题。
在直接查询模式下,所有的直接查询请求都直接发送到源数据库中,后端数据源响应查询请求的速度决定了直接查询的性能。虽然PowerBI尽可能的优化生成的SQL命令,但是,通过监控发现,PowerBI最终生成的SQL命令是非常低效的,特别是在查询海量的数据源时,后端(Back-end)数据源需要执行很长时间,才能返回结果。等待的时间超过30s,用户体检就很不理想了。当导入模式不能满足业务需求时,再考虑直接查询模式。
四,数据加载(并行和串行)
在设计PowerBI 报表时,我们使用两种方式来刷新数据,可以手动逐个地刷新Query,也可以点击Refresh按钮同时刷新所有的Query。当点击刷新全部(Refresh All)时,由于系统内存的限制,刷新操作可能会失败。PowerBI Desktop加载数据的方式可以是串行的,也可以是并行的,默认是并行的,以串行方式加载数据,不需要很大的内存就可以完成。当PowerBI需要刷新很多Query时,刷新全部可能会使PowerBI占用过多的系统内存而发生错误,此时,可以设置PowerBI,使其以串行的方式加载数据以解决这个问题。
设置串行加载数据的步骤是:点击File->Opions & Settings->Options,如下图所示,在CURRENT FILE选项卡中,打开"Data Load"分组,勾选“Enable parallel loading of tables”,启用PowerBI的串行加载数据模式。

然而,这种模式只是以串行的方式把数据加载到PowerBI的缓存中,当在数据模型中创建连接时发生异常,或者在等待数据源返回数据集时出现异常,

数据刷新仍然会失败。PowerBI的刷新全部数据(Refresh All)的工作流程类似于事务,只有当全部的数据集都刷新成功时,数据刷新才是成功的;只要有一个数据集刷新失败,整个刷新操作就失败。
当需要查询的数据集较多时,用户体验非常差。如果PowerBI不能解决大量数据集的刷新问题,那么其功能是不完善的,期待PowerBI 团队后续的更新会修复这个异常。
参考文档: