pandas的pivot和pivot_table 用于表格数据的行列互换,而melt用于unpivot 表格数据。
1,pivot
有如下数据集:
import pandas as pd import numpy as np table = {"Item":['Item0','Item0','Item1','Item1'], "CType":['Gold','Bronze','Gold','Silver'], "USD":[1,2,3,4], "EU":[5,6,7,8]} d = pd.DataFrame(table)
pivot 函数只有三个参数:index 用于指定索引,columns用于指定列,values用于指定透视的数值:
DataFrame.pivot(index=None, columns=None, values=None)
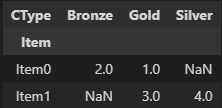
对d进行透视得到的结果如下图所示,其中CType是column name,Bronze、Gold和Silver是列值。
d.pivot(index='Item', columns='CType', values='USD')
2,pivot_table
pivot_table的功能跟pivot相似,但是pivot不能处理index和columns组合是重复的数据,但是pivot_table可以处理:
DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)
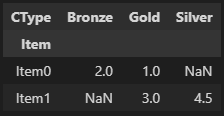
有如下数据,使用pivot函数会报错,只能使用pivot_table,对于重复的数据,可以使用aggfunc函数聚合,可以理解为:index 和columns构成的组合是分组列,在分组内部应用aggfunc函数计算聚合值。
import pandas as pd import numpy as np table2 = {"Item":['Item0','Item0','Item1','Item1','Item1'], "CType":['Gold','Bronze','Gold','Silver','Silver'], "USD":[1,2,3,4,5], "EU":[5,6,7,8,9]} d2 = pd.DataFrame(table2)
对数据使用pivot_table:
d2.pivot_table(index='Item',columns='CType',values='USD', aggfunc=np.mean)
3,melt
融合数据,参数id_vars表示ID变量,value_vars表示值变量,var_name用于指定id变量的列名,value_name用于指定值变量的列名。
DataFrame.melt(id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)
有如下数据,该数据是宽格式的数据:
df = pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}})
df
A B C
0 a 1 2
1 b 3 4
2 c 5 6
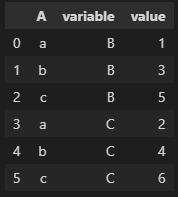
对数据进行融合,把宽格式转换为长格式:
df.melt(id_vars=['A'], value_vars=['B','C'])
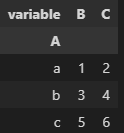
对长格式的数据调用pivot_table,可以把长格式的数据还原为宽格式:
md=df.melt(id_vars=['A'], value_vars=['B','C']) md.pivot_table(values='value',columns='variable',index='A')
参考文档: