在使用pandas进行数据整理时,经常会用到stack和unstack两个函数。stack直译过来是堆叠,堆积,unstack是展开,解释为把列索引和行索引的互换,如下图所示,stack用于把列索引转换为行索引,而unstack用于把行索引转换为列索引。因此,可以把stack和unstack的功能解释为行索引和列索引的互换。
stack和unstack作用的对象是索引,pandas有多级索引(MultiIndex)结构,通过把列索引转换为行索引,那么行索引由单级索引(Index)结构转换为多级索引(MultiIndex)结构,数据不变,只不过索引变了。
- stack():从列到行堆叠,把列索引转换为行索引
- unstack():从行到列展开,把行索引转换为列索引

1,创建数据集
import numpy as np import pandas as pd data=pd.DataFrame(np.arange(12).reshape((3,4))+100, index=pd.Index(['date1','date2','date3']), columns=pd.Index(['store1','store2','store3','store4']) )

2,堆叠数据,把列转换为行
data2=data.stack()
使用stack函数,将data的列['store1','store2','store3’,'store4’]转变成列索引(第二层),便得到了一个层次化的Series(data2),如下所示:

输出到本地以后,可以变成这样:
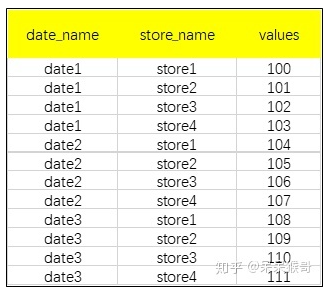
查看data2的索引,是一个多层索引的结构:
data2.index MultiIndex([('date1', 'store1'), ('date1', 'store2'), ('date1', 'store3'), ('date1', 'store4'), ('date2', 'store1'), ('date2', 'store2'), ('date2', 'store3'), ('date2', 'store4'), ('date3', 'store1'), ('date3', 'store2'), ('date3', 'store3'), ('date3', 'store4')], )
3、展开数据,把行转换为列
使用unstack函数,将data2的第二层列索引转变成行索引(默认的,可以改变),便又得到了DataFrame(data3)
data3=data2.unstack()
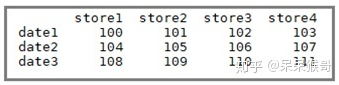
而data3的索引是普通的单级索引:
Index(['date1', 'date2', 'date3'], dtype='object')
参考文档: