自动存在是 DAX 中内置的一项技术,其唯一的目标是避免无用计算,换句话说,它是 DAX 的过滤机制使用的一种优化技术,目的是减少计算值的工作量。
例如,假设有人构建了一份按大陆和国家/地区划分的报告。 在一个数据库中,一个人可能有两大洲和五个国家:

在这些数据上,可以运行一个简单的查询,如下所示:
EVALUATE
SUMMARIZECOLUMNS (
Geography[Continent],
Geography[Country]
)
引擎如何执行这个查询? 有几个选项可供选择:
检索 Continent 的所有可能值,Country 的所有可能值,然后生成两者的笛卡尔积。 在我们的示例中,它将返回 10 行。
检索 Continent 和 Country 对的现有值,仅返回现有值。 在我们的示例中,它将返回 5 行。
第一个选项似乎不是很聪明。 因为意大利在欧洲,所以返回一个不存在的组合 <Italy, North America> 是没有意义的。 因此,DAX 使用第二个选项,它通过一个称为自动存在(auto-exist)的机制来实现。
1,自存在启动的条件
当同一个表的两个或多个列被过滤在一起时,自动存在机制就会启动。 SUMMARIZECOLUMNS 不把列作为单独的过滤器,而是仅生成一个过滤器,该过滤器仅过滤具有现有值组合的所有列。因此,引擎不会扫描所有可能的组合(在我们的示例中,这意味着 5 个城市乘以 2 个大陆,总共 10 个组合),引擎只扫描五个现有组合。大多数情况下,这正是用户所要求的,只是检索得更快。此外,有一个不常见的情况,如果想要检索所有组合,可以使用其他表函数(如 CROSSJOIN)生成不存在的值组合。
然而,在某些情况下,自动存在可能会产生令人惊讶的结果。即使是经验丰富的 DAX 编码人员也可能落入自动存在的陷阱,他们可能认为正在处理一个错误,而不会想到这只是自动存在弄乱了计算。
为了可视化这个问题,我们使用了一个只有几行的非常小的数据模型,该模型包含一个有 9 行的表:
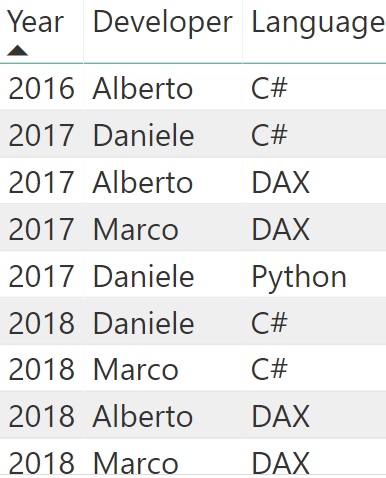
在过去的几年里,我们有三位开发人员开发了不同语言的项目。基于此表,我们生成了一个数据透视表用于检查在不同年份里使用了多少种语言:
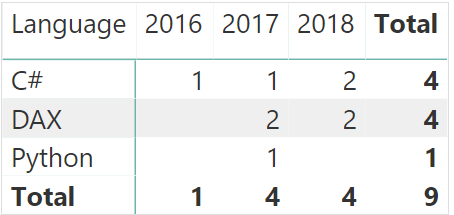
# Projects = COUNTROWS ( Projects ) # Projects All Time = CALCULATE ( [# Projects], ALL ( Projects[Year] ) )
最后,我们在仪表板中使用这个度量,让用户选择年份和语言,并快速查看我们在选定年份开发的项目数量与项目总数的对比:
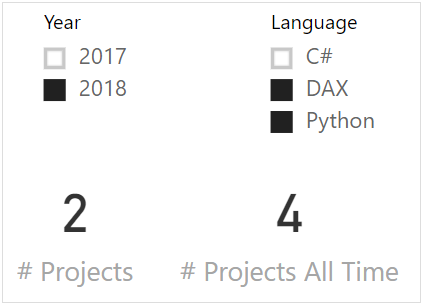
#Project=2,这是正确的,但是,#Projects All Time=4 是一个不准确的值,应该是五个。 这怎么可能? 这不是错误。 这是自动存在的,打乱了计算。了解如何需要您注意一些细节。
清理后,为检索 #Projects All Time 所执行的查询如下所示:
EVALUATE SUMMARIZECOLUMNS ( TREATAS ( { "DAX", "Python" }, 'Projects'[Language] ), TREATAS ( { 2018 }, 'Projects'[Year] ), "Result", [# Projects All Time] )
这两个切片器会生成两个过滤器:一个针对Language,另一个针对Year。请注意这个细节:它们是 Power BI 中的两个切片器,但在查询中被转换,它们会合并为对 SUMMARIZECOLUMNS 的单个调用。因此,SUMMARIZECOLUMNS 在同一个表的列上接收两个过滤器,这是自动存在开始的时候。作为同一个表的列,它们被合并到一个过滤器中,该过滤器包含两个列并且只过滤现有值。不幸的是,2018 年没有 Python 行。因此,生成的过滤器仅包含 (2018, DAX)。
当度量开始时,它使用 ALL 从Year中删除过滤器。尽管如此,删除年份的过滤器并不会显示 Python。过滤器上下文将仅包含 DAX,因为 Python 被自动存在删除,而过滤器的执行顺序早于度量,也就是说,度量是在SUMMARIZECOLUMNS 的筛选上下文中执行的。另一种看待它的方式是说 SUMMARIZECOLUMNS 收到的两个过滤器被合并,就好像查询是这样表达的:
EVALUATE SUMMARIZECOLUMNS ( CALCULATETABLE ( SUMMARIZE ( Projects, 'Projects'[Language], 'Projects'[Year] ), TREATAS ( { "DAX", "Python" }, 'Projects'[Language] ), TREATAS ( { 2018 }, 'Projects'[Year] ) ), "Result", [# Projects All Time] )
2,如果多个列位于不同的表,那么使用cross join
仅当同一表中的多个列用作过滤器时,才会使用自动存在。如果过滤器中的列不属于同一个表,那么 SUMMARIZECOLUMNS 使用交叉连接操作而不是自动存在。 这显然会降低性能。 例如,我们可以构建一个常规的星型模式,而不是使用单个表,如下图所示:
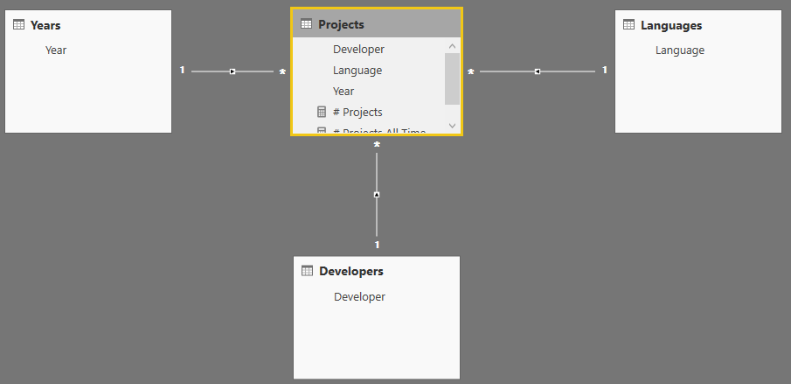
这个小的改动完全改变了 SUMMARIZECOLUMNS 的工作方式,首先,我们需要更新度量的代码:
# Projects All Time = CALCULATE (
[# Projects],
ALL ( Years[Year] )
)
然后,我们不使用 Projects 表中的列进行过滤,而是使用维度表,这会把查询转换为以下内容:
EVALUATE SUMMARIZECOLUMNS ( TREATAS ( { "DAX", "Python" }, 'Languages'[Language] ), TREATAS ( { 2018 }, 'Years'[Year] ), "Result", [# Projects All Time] )
尽管查询看起来与前一个相同,但您应该注意到现在过滤发生在两个表上:Languages 和 Years。 因为这些列现在属于不同的表,所以不会使用自动存在,# Projects All Time 正如结果如预期的那样,是5。
值得注意的是,自动存在是由 SUMMARIZECOLUMNS 执行的,而不是由 CALCULATETABLE 执行的。
CALCULATETABLE 不执行自动存在,相反,它完全按照预期生成过滤器,而无需自动存在步骤。 以下查询# Projects All Time返回的值是5,这是因为内层的CALCULATE函数把外层CALCULATETABLE 的筛选上下文覆盖了。
EVALUATE CALCULATETABLE ( { [# Projects All Time] }, TREATAS ( { "DAX", "Python" }, 'Projects'[Language] ), TREATAS ( { 2018 }, 'Projects'[Year] ) )
有人可能想知道为什么 SUMMARIZECOLUMNS 会有这种行为?原因是 SUMMARIZECOLUMNS 针对查询进行了优化,并且自动存在大大减少了引擎需要扫描以产生结果的空间。在常规星型模式中,维度链接到事实表,自动存在仅对维度进行操作,而且由于模型通常会扫描事实表中的值,因此不会产生任何问题。
在只有一个表的数据模型中,可能会遇到自动存在的问题。如果发生这种情况,最简单的解决方案是避免使用单个表,而是构建适当的星型模式。数据建模的黄金法则始终相同:始终使用星型模式。如果必须使用列进行切片和切块,则它需要属于一个维度。另一方面,要聚合的数字存储在事实表中。
参考文档: