插补法可以在一定程度上减少偏差,常用的插补法是热卡插补、拟合插补和多重插补。拟合插补,要求变量间存在强的相关性;多重插补(MCMC法),是在高缺失率下的首选插补方法,优点是考虑了缺失值的不确定性。
一,热卡插补
热卡填充(Hot deck imputation)也叫就近补齐,对于一个包含空值的对象,热卡填充法在完整数据中找到一个与它最相似的对象,然后用这个相似对象的值来进行填充。通常会找到超出一个的相似对象,在所有匹配对象中没有最好的,而是从中随机的挑选一个作为填充值。这个问题关键是不同的问题可能会选用不同的标准来对相似进行判定,以及如何制定这个判定标准。该方法概念上很简单,且利用了数据间的关系来进行空值估计,但缺点在于难以定义相似标准,主观因素较多。
二,拟合插补
拟合插补法则是利用有监督的机器学习方法,比如回归、最邻近、随机森林、支持向量机等模型,对缺失值作预测,其优势在于预测的准确性高,缺点是需要大量的计算,导致缺失值的处理速度大打折扣。虽然替换法思想简单、效率高效,但是其替换的值往往不具有很高的准确性,于是出现了插补方法。
1,回归插补
基于完整的数据集,建立回归方程。对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充。当变量不是线性相关时会导致有偏差的估计。缺失值是连续的,即定量的类型,才可以使用回归来预测。
2,最邻近填充
利用knn算法填充,其实是把目标列当做目标标量,利用非缺失的数据进行knn算法拟合,最后对目标列缺失进行预测。(对于连续特征一般是加权平均,对于离散特征一般是加权投票)
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor def knn_filled_func(x_train, y_train, test, k = 3, dispersed = True): # params: x_train 为目标列不含缺失值的数据(不包括目标列) # params: y_train 为不含缺失值的目标列 # params: test 为目标列为缺失值的数据(不包括目标列) if dispersed: knn= KNeighborsClassifier(n_neighbors = k, weights = "distance") else: knn= KNeighborsRegressor(n_neighbors = k, weights = "distance") knn.fit(x_train, y_train)
3,随机森林插补
随机森林算法填充的思想和knn填充是类似的,即利用已有数据拟合模型,对缺失变量进行预测。
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier def knn_filled_func(x_train, y_train, test, k = 3, dispersed = True): # params: x_train 为目标列不含缺失值的数据(不包括目标列) # params: y_train 为不含缺失值的目标列 # params: test 为目标列为缺失值的数据(不包括目标列) if dispersed: rf= RandomForestRegressor() else: rf= RandomForestClassifier() rf.fit(x_train, y_train) return test.index, rf.predict(test)
三,多重插补
多重插补(Mutiple imputation,MI)的思想来源于贝叶斯估计,认为待插补的值是随机的,它的值来自于已观测到的值。具体实践上通常是估计出待插补的值,然后再加上不同的噪声,形成多组可选插补值。根据某种选择依据,选取最合适的插补值。
对于拟合插补和均值替换等处理缺失值的方法都是单一的插补方法,而多重插补弥补了单一插补的缺陷,它并没有试图去通过模拟值去估计每个缺失值,而是提出缺失数据值的一个随机样本(这些样本可以是不同的模型拟合结果的组合)。这种程序的实施恰当地反映了由于缺失值引起的不确定性,使得统计推断有效。
注:使用多重插补要求数据缺失值为随机性缺失,一般重复次数20-50次精准度很高,但是计算也很复杂,需要大量计算。
1,多重插补的实现
多重插补是一种基于重复模拟的用于处理缺失值的方法,它从一个包含缺失值的数据集中生成一组数据完整的数据集(即不包含缺失值的数据集,通常是3-10个)。每个完整数据集都是通过对原始数据中的缺失数据进行插补而生成的。在每个完整的数据集上引用标准的统计方法,最后,把这些单独的分析结果整合为一组结果。
多重插补法大致分为三步:
- 为每个空值产生一套可能的插补值,这些值反映了模型的不确定性;每个值都被用来插补数据集中的缺失值,产生若干个完整数据集合。
- 每个插补数据集合都用针对完整数据集的统计方法进行统计分析。
- 对来自各个插补数据集的结果进行整合,产生最终的统计推断,这一推断考虑到了由于数据插补而产生的不确定性。该方法将空缺值视为随机样本,这样计算出来的统计推断可能受到空缺值的不确定性的影响。
2,MICE简介
通过链式方程进行的多元插补(MICE,Multiple Imputation by Chained Equations),与单个插补(例如均值)相比,创建多个插补可解决缺失值的不确定性。MICE假定缺失的数据是随机(MAR)的,这意味着,一个值丢失概率上观测值仅取决于并且可以使用它们来预测。通过为每个变量指定插补模型,可以按变量插补数据。
例如:假设我们有X1,X2….Xk变量。如果X1缺少值,那么它将在其他变量X2到Xk上回归。然后,将X1中的缺失值替换为获得的预测值。同样,如果X2缺少值,则X1,X3至Xk变量将在预测模型中用作自变量。稍后,缺失值将被替换为预测值。
默认情况下,线性回归用于预测连续缺失值。Logistic回归用于分类缺失值。一旦完成此循环,就会生成多个数据集。这些数据集仅在估算的缺失值上有所不同。通常,将这些数据集分别构建模型并组合其结果被认为是一个好习惯。
本文使用R语言中的mice包来执行这些操作,首先我们来看mice包的操作思路:
首先,mice()函数从一个包含缺失数据的数据框开始,返回一个包含多个(默认为5个)完整数据集的对象。每个完整数据集都是通过对原始数据框中的缺失数据进行插补而生成的。由于插补有随机的成分,因此每个完整数据集都略有不同。
然后,with()函数可依次对每个完整的数据集应用统计模型(如线性模型或广义线性模型)。
最后,pool()函数把这些单独的分析结果整合为一组结果。
最终模型的标准差和p值都准确地反映出由于缺失值和多重插补而产生的不确定性。
缺失值的插补法通过Gibbs抽样完成,每个包含缺失值的变量都默认可通过数据集中的其他变量预测的来,于是这些预测方程便可用于预测数据的有效值。该方程不断迭代直到所有的缺失值都收敛为止。默认情况下,预测的均值用于替换连续性变量中的缺失数据。
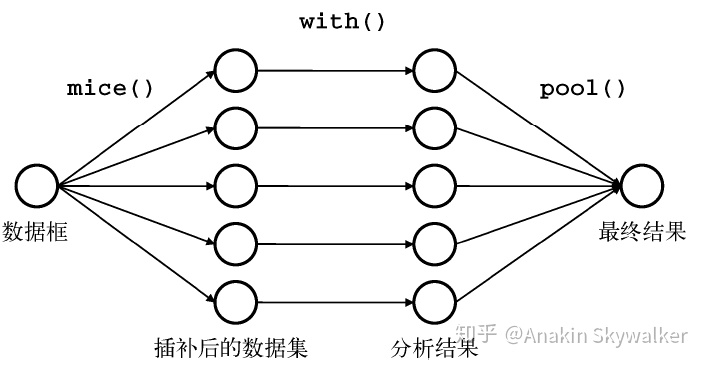
3,基于R的mice包的分析过程
library(mice) imp <- mice(data, m) fit <- with(imp, analysis) pooled <- pool(fit) summary(pooled)
data:包含缺失值的矩阵或数据框;
imp:一个包含m个插补数据集的列表对象,同时还含有完成插补过程的信息。默认为5。
analysis:用来设定应用于m个插补数据集的统计分析方法。比如线性回归模型的lm()函数,举个例子lm(Dream ~ Span + Gest),表达式在函数的括号中,~左边是因变量,右边是自变量,用+符号分隔开。这个例子中Dream是因变量,Span和Gest是自变量;
fit:一个包含m个单独统计分析结果的列表对象;
pooled:一个包含m个统计分析平均结果的列表对象。
四,Python的MICE算法
在处理缺失值时,可以通过链式方程的多重插补(MICE,Multiple Imputation by Chained Equations)估算缺失值,从技术上讲,任何能够推理的预测模型都可以用于MICE。 在本文中,我们使用miceforest Python库估算了数据集,该库使用随机森林。 出于以下几个原因,随机森林可与MICE算法配合使用:
- 不需要太多的超参数调整
- 轻松处理数据中的非线性关系
- 可以廉价地返回OOB性能
- 几乎可以并行化
- 可以返回功能重要性以进行诊断
使用miceForest来插补缺失值的示例代码如下:
import miceforest as mf from sklearn.datasets import load_iris import pandas as pd # Load and format data iris = pd.concat(load_iris(as_frame=True,return_X_y=True),axis=1) iris.rename(columns = {'target':'species'}, inplace = True) iris['species'] = iris['species'].astype('category') # Introduce missing values iris_amp = mf.ampute_data(iris,perc=0.25,random_state=1991) # Create kernels kernel = mf.MultipleImputedKernel( data=iris_amp, save_all_iterations=True, random_state=1991 ) # Run the MICE algorithm for 3 iterations on each of the datasets kernel.mice(3,verbose=True) # Our new dataset new_data = iris_amp.iloc[range(50)] # Make a multiple imputed dataset with our new data new_data_imputed = kernel.impute_new_data(new_data) # Return a completed dataset new_completed_data = new_data_imputed.complete_data(0) # check how well the imputations compare to the original data acclist = [] for iteration in range(kernel.iteration_count()+1): target_na_count = kernel.na_counts['target'] compdat = kernel.complete_data(dataset=0,iteration=iteration) # Record the accuract of the imputations of target. acclist.append( round(1-sum(compdat['target'] != iris['target'])/target_na_count,2) ) # acclist shows the accuracy of the imputations over the iterations. print(acclist)
关于miceForest包的详细用法,请阅读官方手册:miceforest 2.0.3
参考文档:
处理缺失值之多重插补(Multiple Imputation)