Azure Data Factory 系列博客:
- ADF 第一篇:Azure Data Factory介绍
- ADF 第二篇:使用UI创建数据工厂
- ADF 第三篇:Integration runtime和 Linked Service
- ADF 第四篇:管道的执行和触发器
- ADF 第五篇:转换数据
- ADF 第六篇:Copy Data Activity详解
- ADF 第七篇:控制流概述
- ADF 第八篇:传递参数(Pipeline的Parameter和Variable,Activity的output)和应用表达式
映射数据流(Mapping Data Flow)的核心功能是转换数据,数据流的结构分为Source、转换和Sink(也就是Destination),这种结构非常类似于SSIS的数据流。
在数据流中,数据就像流水(stream)一样,从上一个组件,流向下一个组件。组件之间有graph相连接,把各个组件连接为一个转换流(transformation stream),在数据流面板中,graph显示为一根线,用于表示数据从一个组件流向另一个组件的路径。
转换组件是数据流的核心组件,每一个转换组件都有输入和输出,接收上一个路径上的组件输入的数据,并向下一个路径上的组件输出数据。
一,创建映射数据流面板
打开一个数据工厂,切换到Author面板中,从“Factory Resources”中选择“Data flows”,从后面的“...” (Actions)中选择“New mapping dataflow”,新建数据流面板:
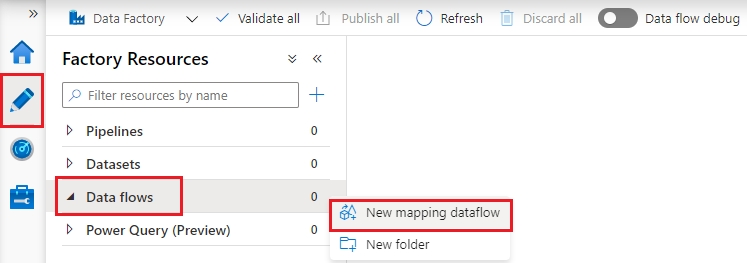
初始的数据流面板如下图所示,dataflow1是数据流面板的名称,面板的中央是画布,可以向画布中添加Source、转换组件和Sink(destination)。
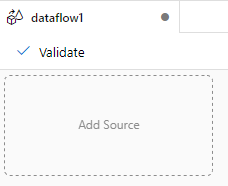
二,为数据流组件添加Source
从dataflow的面板中点击“Add Source”为数据流添加源, 添加数据源之后,source1是源的名称,右下方有一个“+”号,表示为源添加转换功能。
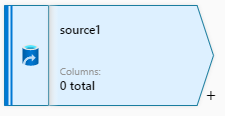
在选中Source之后,面板中央的下方区域显示为Source的属性面板,
1,Source setting 面板
Source settings 用于设置Source的属性,常用的Source属性是Source type(源类型),最常用的类型是Dataset,表示从Dataset中获取数据。
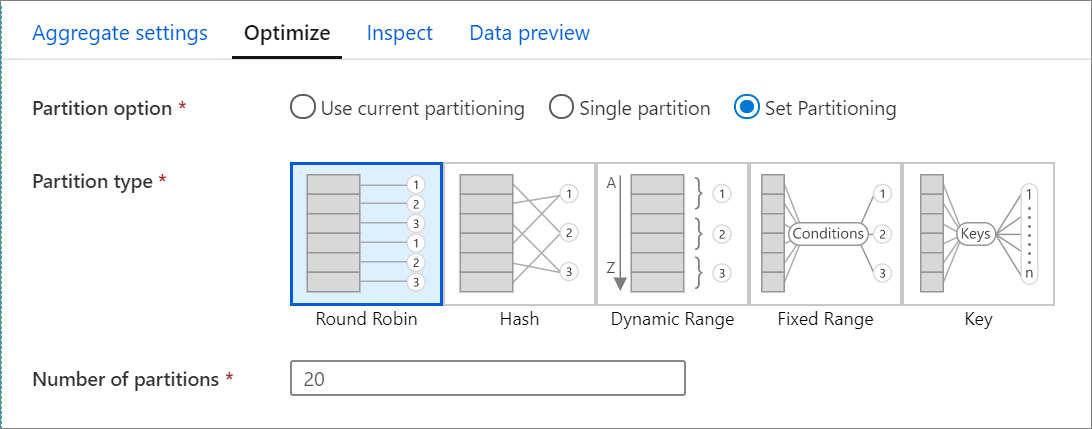
2,Optimize 面板
Optimize 选项卡 用于设置分区架构,可以设置Partition option、Partition type和 Number of partitions,分区会优化数据流的性能。
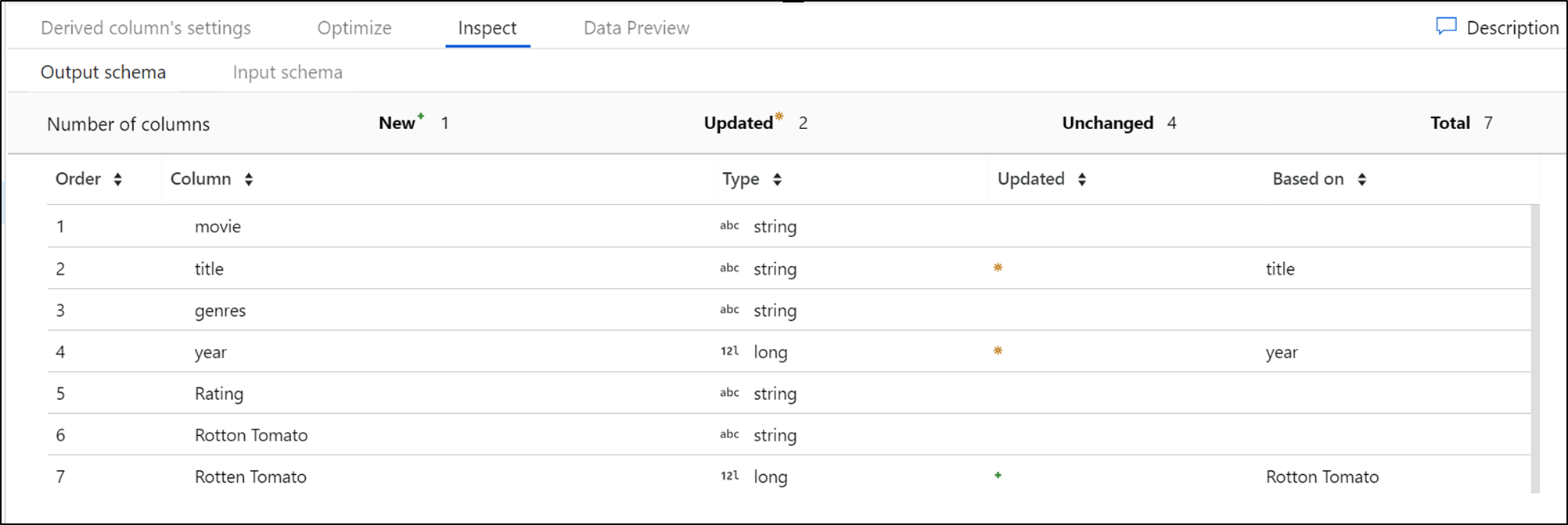
3,Inspect面板
Inspect 选项卡用于显示数据流的元数据,该选项卡是一个只读的视图,从该选项卡中可以看到数据流的列数量(column counts),列变化、增加的列、类的数据类型、列的顺序等。
三,添加转换功能
点击Source右小角的“+”号,为源添加转换功能,这是数据流的核心功能,常用的转换功能分为四组:Multiple inputs/outputs、Schema modifier、Row modifier和Destination。
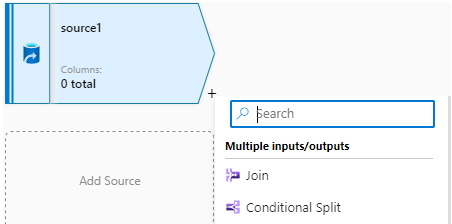
1,多输入/输出(Multiple inputs/outputs)
- Join:用于表示连接,把多个Source(Input)连接成一个输出流
- Conditional Split:条件拆分,把一个Source 按照条件拆分成多个输出流
- Exists:需要两个输入Left stream和Right stream,按照指定的条件和Exist type输出数据,如果Exist type是Exists,那么表示输出Left Stream存在于Right stream的数据;如果Exist type是Doesn't exist,那么表示输出Left stream不存在于Right stream的数据。
- Union:把多个输入合并
- Lookup:需要两个输入,Primary stream和Lookup stream,把Primary stream中存在于Lookup stream中的数据输出。
2,Schema Modifier
对列进行修改:
- Derive Column:派生列
- Select:选择列
- Aggregate:对源中的数据进行聚合运算
- SurrogateKey:根据源的主键生成代理主键
- Pivot和Unpivot:透视和逆透视
- Windows:定义数据流中基于窗口的列的聚合
- Flatten:平展数据,例如,把JSON字段平展,生成多个字段
- Rank:排名
3,Row Moifier
对行进行修改:
- Filter:过滤行
- Sort:对行进行排序
- Alter Row:修改行,设置针对行的插入、删除、更新和更新插入(upsert)策略
4,Destination
Sink:用于设置数据存储的目标
四,运行和监控数据流
数据流实际上是Pipeline中的一个Activity,只有在Pipeline中创建数据流Activity,才能开始Debug,并设置触发器。
1,调式数据流
在发布(publish)之前,需要对数据流进行调试,把数据流的“Data flow debug”设置为启用:

调试完成之后,发布数据流,就可以把数据流保存到数据工厂中。
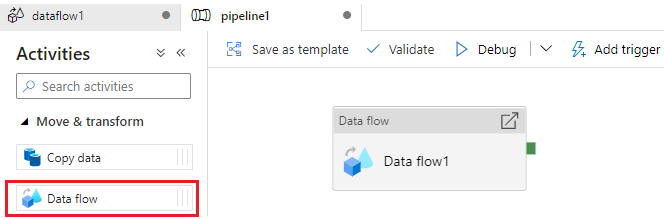
2,添加数据流Activity
在Pipeline中面板中添加Data flow 活动,
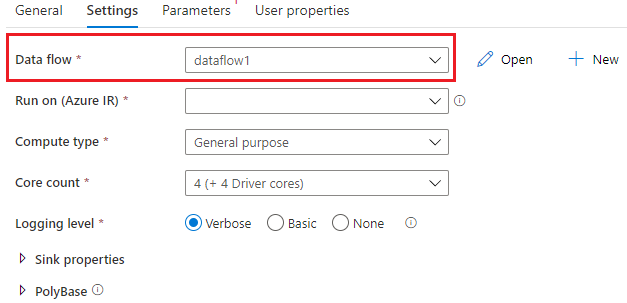
在Data flow活动的Settings选项卡中,在“Data flow”中设置引用的数据流,Run on (Azure IR) 用于设置IR,并可以设置日志级别(Logging Level),Verbose是默认选项,表示记录详细的日志。
3,监控数据路
监控数据流其实就是在Pipeline runs中查看管道执行的情况
参考文档: