Azure Data Factory(简写 ADF)是Azure的云ETL服务,简单的说,就是云上的SSIS。ADF是基于云的ETL,用于数据集成和数据转换,不需要代码,直接通过UI(code-free UI)来设计,可进行直观监控和管理。用户还可以把现有的SSIS packages部署到Azure,并和ADF完全兼容地运行。
一,ADF适用的场景
在大数据的世界中,原始的、无结构的数据通常存在在关系型、非关系型和其他存储系统中,由于原始数据没有适当的上下文含义,无法被数据分析师、数据科学家提供有意义的insights。
ADF能够处理海量的数据,对这些原始数据进行处理和提炼,获得有用的信息和洞察。Azure Data Factory 创建Pineline,从不同的数据源(如:Azuer Storage,File, SQL DataBase,Azure Data Lake等)中提取数据,对数据进行加工处理和复杂计算后,把这些有价值的数据存储到不同的目标存储(如:Azuer Storage,File, SQL DataBase,Azure Data Lake等)上,供数据分析师或数据科学家进行分析。

Azure 数据工厂是基于云的数据集成服务,用于在云中创建数据驱动型工作流,以便协调和自动完成数据移动和数据转换。 使用 Azure 数据工厂可执行以下任务:
- 创建管道(Pipeline),以便从不同的数据存储中提取数据。
- 处理和转换原始数据,获得一个结构化的数据。
- 把处理之后的数据发布到数据存储(例如 Azure Synapse Analytics),供商业智能 (BI) 应用程序使用。
二,ADF的工作原理
ADF 包含一系列的相互连接组件,为数据工程师提供完整的端到端(end-to-end)的平台。Azure 数据工厂中的管道(数据驱动型工作流)通常执行以下三个步骤:

1,连接和收集
企业有不同类型的数据,这些数据位于不同的源中,比如on-permises,云上的,有结构的、无结构的,并且以不同的间隔和速度到达。构建信息生成系统的第一步是连接到所有必需的数据源,对数据进行处理,这些源包括:SaaS 服务、文件共享、FTP、Web 服务,然后,把需要的数据移到中心位置进行后续处理和分析。
如果没有ADF,那么企业就必须创建自定义的数据移动组件或编写自定义的服务,以便集成这些数据源并进行处理。集成和维护此类系统既昂贵又困难,这些系统通常还缺乏企业级监视、警报和控制,而这些功能是完全托管的服务能够提供的。但是借助ADF,用户可以在pipeline中使用“Copy Activity”,把数据从本地和云的源数据存储转移到云上的集中数据存储,进行进一步的分析。
2,转换和扩充
把数据集中到云上的数据存储以后,使用ADF映射数据流处理或转换数据,数据流使数据工程师能够构建和维护数据转换,而无需了解Spark集群或Spart变成。如果用户喜欢手工编码转换,那么ADF支持外部活动(External Activity),以在HDInsight Hadoop,Spark,Data Lake Analytics和Machine Learning等计算服务上执行转换。
3,发布
ADF使用Azure DevOps和GitHub全面支持Pipeline,在发布最终版本之前进行迭代式的开发。把原始数据精炼成可用于商业分析的数据之后,用户可以把转换的数据从云上的存储传送到本地源(例如 SQL Server),也可将其保留在云存储源中,供 BI 和分析工具及其他应用程序使用。
4,Source Control 和 Monitor
ADF内置监控器,用于监控ADF中的活动(Activity)和Pipeline的成功率和失败率。
V2版本的ADF具有GitHub和DevOps的source control功能。
三,ADF的关键组件
ADF 由下面4个关键组件构成:
- Pipelines
- Activities
- Datasets
- 连接(Linked services和Integration runtimes)
ADF的4个关键组件之间的关系:
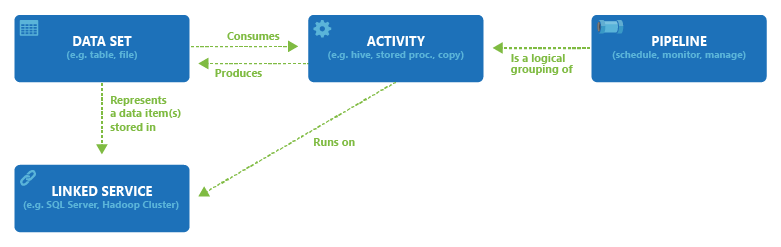
1,管道(Pipeline)
数据工厂包含一个或多个Pipeline,管道是Activity的逻辑分组,一个管道作为一个工作单元,管道中的Activity作为一个整体来执行任务。管道中的Activity对数据执行动作。
管道使用户可以把多个Activity作为一个整体进行管理,而不必单独管理每个Activity,管道中的Activity可以连接在一起按照顺序串联执行,也可以单独以并发方式执行。
2,活动(Activity)
管道可以包含一个或多个活动,活动定义对数据执行的操作,是Pipeline中的一个步骤。 例如,用户可以使用Copy Activity把数据从一个数据存储复制到另一个数据存储。ADF支持三种类型的活动:数据移动活动、数据转换活动和控制流活动。
- 数据移动活动:用于把数据从源数据存储赋值到接收数据存储,来自任何源的数据都可以写入到任何接收器。
- 数据转换活动:用户对数据进行转换处理
- 控制流活动:控制流负责对管道活动进行控制,包含按照顺序连接活动、在管道级别定义参数、进行循环控制等。
3,数据集(Datasets)
数据集代码数据存储中的数据结构,这些结构指向或引用在活动中使用的数据(输入或输出),也就是说,一个活动使用零个或多个数据集作为输入,使用一个或多个数据集作为输出。
数据集(Dataset)类似于数据的视图,只是简单地指向或引用在活动中用作输入的数据源或者用作输出的数据目标。在创建Dataset之前,必须创建Linked Service,把数据连接到数据工厂。Linked Service 就像连接字符串,定义数据工厂如何和外部资源进行连接。而Dataset代表的是数据的结构(Schema),而Linked Service定义如何连接到数据。
4,连接(Connection)
连接有两种类型:Linked services 和 Integration runtimes,Linked services 是基于Integration runtimes的连接服务。
Integration runtime(IR) 是Azure 数据工厂在不同的网络环境中进行数据集成的组件,
连接服务(Linked services )类似于连接字符串,用于定义ADF连接到外部资源时所需要的连接信息,连接服务定义如何连接到外部数据源,而数据集代表外部源数据的结构。
5,映射数据流(Mapped Data Flow)
在ADF V2版本中,新增了映射数据流组件,映射数据流用于数据转换,数据流作为Activity在管道中执行。 数据流使数据工程师无需编写代码即可开发数据转换逻辑。
6,其他组件
参数(Parameters)是一个只读的Key-Value对,参数定义在管道中,在管道执行时,参数传递到管道中的Activity中。
变量(Variable)用于在管道中存储临时值,并可以接收参数的值,把值传递到其他管道、数据流和Activity中。
参考文档: