###生产者消费者关系###
- 主要是解耦(高内聚,低耦合),借助队列来实现生产者消费者 模型
- 栈:先进后出(First In Last Out 简称:FILO)
- 队列:先进先出(First In First Out 简称:FIFO)
- import queue .............不能进行多进程之间的数据传输
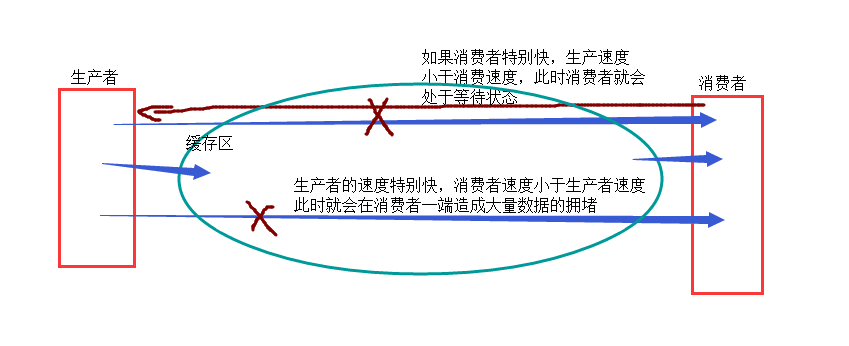
1,队列:from multiprocessing import Queue借助Queue来解决生产者消费者模型,队列是安全的
- 1.1>q = Queue(num)也只能是数据一次次的放,一次次的拿(一进一出)
- num:队列的最大长度(表示对列里能刚的最多数据,当数据量较大时就会阻塞,等待进入到队列中)
- q .get():表示获取队列中的数据,如果队列中有数据是直接获取,此时就没有阻塞等待这么一说了,当队列没有数据时,它就会在这阻塞等获取数据.
- q.put():表示向管道里发送数据,当管道数据未满,(管道里被获取数据的速度大于发送的速度时,)这时就可以直接放到队列里,如果管道数据满(管道获里被获取数据的速度小于发送的速度时)发送端(生成者)这时就会处于阻塞状态
- q.get_nowait():不阻塞:队列里有数据时就直接获取,没有时就会直接报错(比较敏感,不能容忍)
- q.put_nowait():,不阻塞:,如果可以继续往队列中放数据,就直接放,不能就会报错(比较敏感,不能容忍)
- 1.2>JoinableQueue###可连接的队列
- from multiprocessing import JoinableQueue是继承了Queue,所以可以使用Queue中的方法
- 并且JoinableQueue又多了两个方法
- q.join():用于生产者.表示等待消费者q.task_done返回一个标识(ack),生产者就能获得消费者当前消费了多少个数据
- q.task_done()#用于消费者,是指每个消费队列中的一个数据,就给join返回一个标识
###第一种方法###是在生产者q.put(None)来给消费者提示队列的数据被消费完.(是子进程与子进程之间的通信)
from multiprocessing import Process,Queue # 导入队列的模块Queue def consumer(q): # .定义消费者函数来生成在消费者的子进程 num = q.get() # .通过q.get()来获取队列里的数据 if num == None # 判断当num的数据是None的时候就执行下边的代码 print("队列空了...") else: # 当条件不成立的时候就打印这个数 print(num) def producer(q): # 定义来生成生产者的子进程 for i in range(10): # 连续生产10个数 num = i+1 q.put(num) # 把生产出来的数放到队列里 q.put(None) # 当数据生产完毕,就在队列里放一个None if __name__ == "__main__": q = Queue() # .实例化一个队列的对象,括号里可以放数,表示队列可以放多少数据 con = Process(target=consumer,args=(q,)) pro = Process(target=producer,args=(q,)) con.start() pro.start()
###第二种方法###在主程序q.put(None)来控制消费者是否全部去到了生产者的数据(主进程和子进程之间的通信)
from multiprocessing import Queue,Process import time def consumer(q,name,color): while 1: info = q.get() if info: print('%s %s 拿走了%s �33[0m'%(color,name,info)) else:# 当消费者获得队列中数据时,如果获得的是None,就是获得到了生产者不再生产数据的标识 break# 此时消费者结束即可 # 消费者如何判断,生产者是没来得及生产数据,还是生产者不再生产数据了? # 如果你尝试用get_nowait() + try 的方式去尝试获得生产者不再生产数据,此时是有问题的。 def producer(q,product): for i in range(20): info = product + '的娃娃%s号'%str(i) q.put(info) if __name__ == '__main__': q = Queue(10) p_pro1 = Process(target=producer,args=(q,'岛国米饭保你爱')) p_pro2 = Process(target=producer,args=(q,'苍老师版')) p_pro3 = Process(target=producer,args=(q,'波多多版')) p_con1 = Process(target=consumer,args=(q,'alex','�33[31m')) p_con2 = Process(target=consumer,args=(q,'wusir','�33[32m')) p_l = [p_con1,p_con2,p_pro1,p_pro2,p_pro3] [i.start() for i in p_l] # 父进程如何感知到生产者子进程不再生产数据了? p_pro1.join() p_pro2.join() p_pro3.join() q.put(None)# 几个消费者就要接受几个结束标识 q.put(None)
###第三种方法###是通过JoinableQueue来实现子进程和子进程和主进程之间相互通信
from multiprocessing import JoinableQueue,Process # 导入一个新模块JoinableQueue def consumer(q): num = q.get() print(num) q.task_done() # task_done是没get()到一个值就会返回给join(生产者)一个标识 def producer(q): for i in range(10): num = i +1 q.put(num) q.join() # 等待全部接受完task_done生产者才完完全全结束(此时是阻塞等待) if __name__ == "__main__": q = JoinableQueue() con = Process(target=consumer,args=(q,)) pro = Process(target=producer,args=(q,)) con.daemon = True con.start() pro.start() pro.join()
- 等到生产者的代码执行完毕,再开始执行主程序的代码,当主程序执行完毕就会把设置成守护进程停止,这时会强制关停守护进程的的while循环.
###主程序等待生产者程序只想完毕再执行,生产者程序会等待消费者程序执行完毕才执行完毕,这时主城序的执行完毕,又会将消费者程序强制停止,形成一个关系作用环
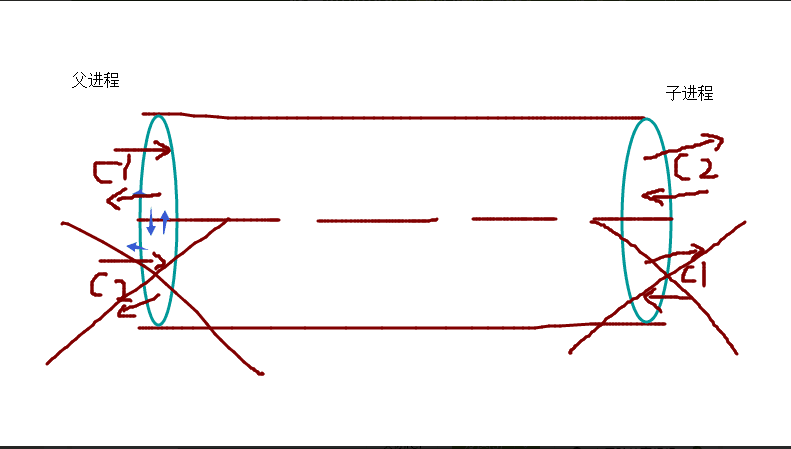
2,管道
2.1>单进程下的管道
from multiprocessing import Pipe con1,con2 = Pipe() con1.send("liangxue") print(con2.recv()) # .此时打印的是abc,con1发送的只能是con2接收 con2.send([1,2,3]) print(con1.recv()) # 此时打印的是[1,2,3]con2发送只能是con1发送

###不能con1发送,con1接收时不会包错,发送端不能做为接收端###
- 2.2>多进程下的管道(管道都有2端,一端接收,一端发送)
from multiprocessing import Process,Pipe # 导入Process模块和Pipe模块 def func(con1,con2): # 定义一个创建子进程的函数 con1.close() # .如果用con2发送,就把con1关掉,要不然会一直处于阻塞状态 while 1: try: # 是用抛异常机制来从管道取东西 print(con2.recv()) except EOFError: con2.close() # 取完数据数据以后就把con2关掉 ,要不然会一直处于阻塞状态 break # 跳出循环,要不然会一直死循环 if __name__ == "__main__": con1,con2 = Pipe() # 实例化的管道得到的是2个对象(管道的特性) p = Process(target=func,args=(con1,con2)) p.start() con2.close() # 这个其实不用去关,不会处于阻塞状态,但为了代码的严谨,要关掉 for i in range(10): con1.send(i) con1.close() # 这个必须关掉,要不接受端一直处于阻塞状态.
3,多进程之间的内存资源共享
from multiprocessing import Process, Manager # 导入Manager模块 def func(): # .定义一个创建 子程序的函数 num[0] -= 1 # 把可迭代对象(列表)的第0项数字减一 print("子进程中的num的值是",num) if __name__ == "__main__": m = Manager() # 实例化Manager这个对象 num = m.list([1,2,3]) # 共有资源列表,固定写法:m.数据类型() p = Process(target=func,args=(num,)) p.start() p.join() # 等子进程把共有的资源修改完再执行下一步操作,要不然会报错,数据容易混乱 print("父进程中的num的值是",num)

4,进程池:一个存放有一定数量进程的池子,这些进程一直处于待命状态,一旦有任务来,马上就有进程去处理.因为在实际业务中,任务量是有多有少的,如果任务量特别的多,不可能要开对应的进程,第一,开启进程需要大量 的时间让操作系统来为你管理它,其次还需要消耗大量时间让cpu帮你调度
进程池的优点:会帮助程序员去管理进程池中的进程池
进程池的最佳开启数量:核数+1,核数可以由os模块去get到,进程池的进程均为子进程,不用.start(),进程池会帮你开启进程池
- from multiprocessing import pool
- p = Pool(os.cpu_count() + 1)
- 4.1>map方法:map(function,iterable)
- function:进程池中的进程执行的任务函数
- iterable:可迭代对象,是把可迭代对象中的每个元素依次传给任务函数当参数
from multiprocessing import Pool # 导入Pool这个数据池 def func(num): num = num + 1 # 把map中可迭代对象的每一个值传过来做处理 print(num) return num # 此时return的每一个值(经过处理后)都会在此放到列表中 if __name__ == "__main__": p = Pool(5) # 实例化5个进程的数据池 ret = p.map(func,[i for i in range(10)]).这的可迭代对象会把每一个数据作为参数传给函数 p.close() # 关闭进程池的大门,不允许其他任务再进入到进程池,防止进程处理混乱 p.join() # 等待进程池中的数据处理完毕再执行主进程代码 print("主进程中的map的返回值是",ret)
- 4.2>apply(function,args=()):表示同步的效率,也就是说进程池中的内容一个一个的去执行
- function:进程池中的进程执行的任务函数,args:可迭代对象的参数,是传给任务函数的参数
- 同步处理任务时,不需要close()和join
- 同步处理任务时,进程池中的所有进程是普通进程(主进程需要等待其执行结束)
- appy_async(func,args=(),callback=None):表示异步的效率,也就是说进程池中的进程一次性都去执行任务
- func:进程池中的进程执行的任务函数
- args:可迭代对象的参数,是传给任务函数的参数
- callback:回调函数,就是说没当进程池中有进程处理完了,返回的结果可以交给回调函数,由回调函数进行进一步的处理,回调函数只有异步有,同步是没有的
- 异步处理任务时,进程池中的所有进程是守护进程(主进程代码执行完毕守护进程就结束)
- 异步处理任务时,必须加上close和join
- 回调函数的使用:
- 进程的任务函数的返回值,被当成回电函数的形参接收到,以此进行进一步的处理操作
- 回调函数是由主进程调用到的,而不是子进程,子进程值负责把结果传递给回调函数
- 4.2.1>apply同步效率(结果是一个一个出的,因此效率比较低下,比较耗时)
from multiprocessing import Pool import time def func(num): time.sleep(0.5) num += 1 print(num) if __name__ == "__main": p = Pool(5) # 实例化一个5个进程的进程池(这5个进程池都是普通子进程) for i in range(10): p.apply(func,args=(i,)) # p.apply(上边的执行函数,是可迭代对象的参数) p.close() p.join()
- 当加上p.close()时,在p.join()上边还好,不会报错,因为关闭了进程池的大门,所以join与不join每没有太大区别,当p.close()在p.join()的下一道程序,就会报错(程序执行到最后一个值的时候)报一个断言的错误,按时代码会执行完
- 4.2.2>异步的效率(异步是因为同时进行进程中的几条进程,所以耗时少,效率较高)
from multiprocessing import Pool import time def func(num): time.sleep(0.5) num += 1 print(num) if __name__ == "__main__": p = Pool(5) # 实例化一个放5个进程的进程池(实守护进程例化的进程是) for i in range(10): p.apply_async(func,args=(i,)) # p.apply_async(上边执行的函数,可迭代对象的参数) p.close() # 这必须有了,对于进程池的进程和数据比较安全 p.join() # join主,因为开启的子进程都是守护进程,不join主,守护进程就不会执行了
这时的close和join就必须得加上了, 且顺序不能乱,,要么包一个断言的错误,要么就是代码执行完,每有打印任何结果,
- 2.2.3>回调函数(进程的任务函数返回值,被当做是参数返回给回调函数,当做回调函数的参数)来进一步处理
from multiprocessing import Pool # 导入Pool进程池 def func(num): # 定义一个进程的任务函数 num += 1 # .操作进程处理来的数据 return num # 此时返回给回调函数,并做为回调函数的参数 def cal_back(num): # 定义回调函数 num = num + 10 # 操作进程任务函数返回来的参数 print(num) if __name__ == "__main__": p = Pool(5) # .实例化一个存放有5个进程的进程池 for i in range(10): # 传原始数据 p.apply_async(func,args=(i,),callback=cal_back) # 三个参数:进程的任务函数,穿的原始参数, 回调函数 p.close() p.join()
- 进程池异步处理(一次性处理进程池里的相应数量的进程)时间利用率较高,而同步处理即使进程池里有一定数量的进程,也是一条一条的去执行,因此时间利用率相对较低