数据的变换
- 数据变换主要是对数据进行规范化处理,将数据转换成"适当的"形式,以适用于挖掘任务及算法的需求.
- 简单的函数变换:是对原始数据进行某些函数变换,常用的变换包括平方,开方,取对数,差分运算等
- 简单的函数变换常用来将不具有正太分布的数据变换成具有正太分布的数据.在时间序列分析中,有时简单的对数变换或者差分运算就可以将非平稳序列转换成平稳序列,在数据挖掘中,简单的函数变换可能更有必要,比如个人年收入的取值范围10000元到10亿元,这是一个很大的区间,使用对数变换对其进行压缩是常用的一种变换处理方法.
- 规范化
- 数据规范化(归一化)吹数据是数据挖掘的一箱基础工作,不同的评价指标往往具有不同的量纲,数据间差别可能很大,不进行处理可能会影响到数据处理的结果,为了消除指标间的量纲和取值范围差异的影响,,需要进行标准化处理,将数据按照比例进行缩放,使之落入一个特定的区域,便于进行综合分析.
- 数据规范化对于基于距离的挖掘算法尤为重要
- 最小-最大规范化
- 最小-最大化也称为离差标准化,是对原始数据的线性变化,将数值映射到[0.1]之间,其转换公式如下:
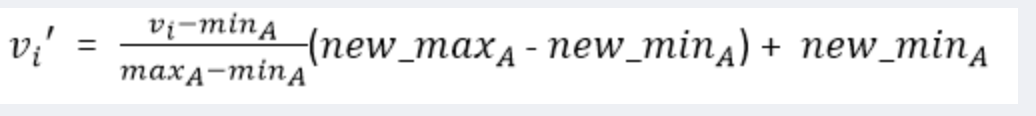
- 其中,max为样本数据的最大化,min为样本数据的最小值,max-min为极差.离差标准化保留了原来数据中存在的关系,是消除量纲和数据取值范围影响最简单方法.这种方法的缺点是若数值集中且某个数值很大,则规范化后各值会接近于0,并且将会相差不大.若将来遇到超过目前属性[min,max]取值范围,会引起系统出错,需要重新确定min和max
- 零-均值规范化
- 零-均值规范化也称标准差标准化,经过处理的数据均值为0,标准差为1,转化公式为:

- 其中分母为原始数据的标准差,分子为每一个数据与均值的差,这一方法是当前用的最多的数据标准化方法.
- 小数定标规范化
- 通过移动属性值的小数位数,将属性值映射到[-1,1]之间,移动的小数位取决于属性值绝对值的最大值.其公式如下
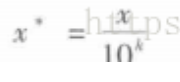
- 最小-最大规范化
- 连续属性离散化
-
- 一些数据挖掘的算法,特别是某些分类算法(如ID3算法,Apriori算法等),要求数据是分类属性形式,这样,常常需要将连续属性变换成分类属性,即连续属性离散化.
- 离散化的过程:
- 连续离散化就是再数据的取值范围内设定若干离散的划分点,将取值范围划分为一些离散化区间,最后用不同的符号或整数值代表落在每个子区间中的数据值.所以离散化涉及两个子任务:确定分类以及如何将连续属性值映射到这些分类值
- 常用的离散化方法
- 常用的离散化方法又等宽法,等频法,基于聚类分析的方法
- 等宽法:
- 将属性的值域分成具有等宽的区间,区间的个数数据本身的特点决定,或者由用户指定,类似于制作频率分布表
- 等频法:
- 将相同数量的记录放进每个区间
- 这两种方法简单,易于操作,但都需要人为地规定划分区间个数.同时,等宽法的缺点在于它对离群点比较敏感,倾向于不均匀地把属性值分布到各个区间.有些区间包含许多数据,而另外一些区间的数据极少,这样会严重损坏建立的决策模型.等频法虽然避免了上述产生的问题,却可能将相同的数据值分到不同的区间以满足每个区间中固定的数据个数
- 基于聚类分析的方法:
- 一维聚类分析的方法包括两个步骤,首先将连续属性的值用聚类算法(K-Means算法)进行聚类,然后再将聚类得到的簇进行处理,合并到一个簇的连续属性值并做同一标记.聚类分析的离散化方法也需要用户指定簇的个数,从而决定产生的区间数
-
import pandas as pd data = pd.read_csv("./discretization_data.csv") # data.describe(percentiles=) print data data = data["coefficient"].copy() k = 4 # k等于4是什么意思啊? d1 = pd.cut(data, k, labels=range(k)) # 等宽离散化,各个类比依次命名为0,1,2,3 # 等频率离散化 w = [1.0 * i/k for i in range(k+1)] w = data.describe(percentiles=w)[4:4+k+1] # 使用describe函数自动计算分位数 w[0] = w[0]*(1-1e-10) d2 = pd.cut(data,w,labels=range(k)) from sklearn.cluster import KMeans kmodel = KMeans(n_clusters=k, n_jobs=4) # 建立模型,n_jobs是并行数,一般等于cpu数较好 kmodel.fit(data.reshape((len(data), 1))) # 训练模型 c = pd.DataFrame(kmodel.cluster_centers_).sort(0) # 输出聚类中心,并且排序(默认是随机序的) w = pd.rolling_mean(c,2).iloc[1:] # 相邻两项求中点,作为边界点 w = [0] + list(w[0]) + [data.max()] # 把首末边界点加上 d3 = pd.cut(data, w, labels=range(k)) def cluster_plot(d,k): # 自定义作图函数来显示聚类结果 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示符号 plt.figure(figsize=(8,3)) for j in range(0, k): plt.plot(data[d==j], [j for i in d[d==j]], 'o') plt.ylim(-0.5, k-0.5) return plt cluster_plot(d1, k).show() cluster_plot(d2, k).show() cluster_plot(d3, k).show()
- 属性构造
- 在数据挖掘的过程中,为了提取更有用的信息,挖掘更多深层次的模式,提高挖掘结果的精度,我们需要利用已有的属性集构造出新的属性,并加入到现有的集合属性中.
- 小波变换
- 小波变换是一种新型的数据分析工具,是近年来兴起的信号分析手段.小波分析的理论和方法在信号处理,图像处理,语音识别,模式识别,量子物理等领域得到越来越广泛的应用,它被认为是近年来再工具及方法上的重大突破.小波变换具有多分辨率的特点,再时域和频率都具有表征信号局部特征的能力,通过伸缩和平移等运算过程对信号进行多尺度聚焦分析,提供了一种非平稳信号的时频分析手段,可以由粗及细的逐步观察信号,从中提取有用信息.
- 基于小波变换的特征提取方法
- 基于小波变换提取方法主要有:基于小波变换的多尺度空间能量分布特征提取,基于小波变换的多尺度空间的模极大值特征提取,基于小波包变换的特征提取,基于适应性小波神经网络的特征提取
-
基于小波变换的特征提取方法方法描述
基于小波包变换的特征提取方法 利用小波分解,可将时域随机信号序列映射为尺度域各子空间内的随机系数序列,按小波分解得到的最佳子空间内随机系数序列的不确定型程度最低.将最佳子空间的熵值及最佳子空间在完整二叉树中的位置参数作为特征量,可疑用于目标识别 基于小波变换的多尺度空间的模式极大值特征提取方法 利用小波变换的信号局域化分析能力,求解小波变换的模极大值特性来检测信号的局部奇异性,将小波变换模极大值特性来检测信号的局部奇异性,将小波变换模极大值的尺度参数s,平移参数t及其幅值作为目标的特征量 基于小波变换的多尺度空间能量分布特征提取方法 各尺度空间内的平滑信号和细节信号能提供原始信号的时频局域信息,特别时能提供不同频段上信号的构成信息.把不同频段上的信号的构成信息.把不同分解尺度上信号的能量求解出来,就可以将这些能量尺度顺序排列,形成特征向量供识别用 基于适应性小波神经网络的特征提取方法 基于适应性小波神经网络的特征提取方法可疑通过分析小波拟合表示进行特征提取.
-
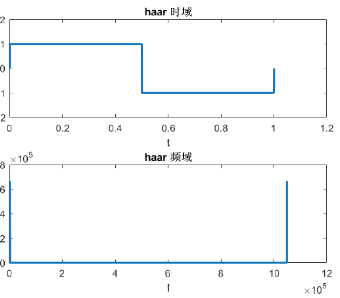
小波基函数
- 小波基函数是一种具有局部支集的函数,并且平均值为0,小波基函数满足φ(0) = ∫φ(t)dt = 0.常用的小波基有Haar小波基,db系列小波基等
-
- 小波变换
- 对小波基函数进行伸缩和平移变换:
- 基于小波变换的多尺度空间能量分布特征提取方法
- 应用小波分析技术可以把信号再各频率波段中的特征提取出来,基于小波变换的多尺度空间能量分布特征提取方法时对信号进行频带分析,再分别以计算所得的各个频带的能量作为特征向量
- 信号ft的二进小波分解可表示为:
- f(t) = Aj + ∑Dj
其中A时近似信号,为低频信号部分;D时细节信号,为高频部分.- 信号的总能量为:
- E = EAj + ∑EDj
- 选择第j层的近似信号和各层的细节信号的能量作为特征,构造特征向量:
- F = [EAj, ED1, ED2, ... EDj]
- 利用小波变换可以对声波信号进行特征提取,提取出可以代表声波信号的向量的数据,即完成从声波信号到特征向量数据的变换.本例利用小波函数对声波信号数据进行分解,得到5各层次的小波系数.利用这些小波系数求得各个能量值,这些能量值即可作为声波信号得特征数据
- 小波变换
-