数据的预处理
- 数据预处理的主要内容包括数据的清洗,数据的集成,数据的变换,数据的规约.
- 数据清洗:数据的清洗主要是删除原始数据集中的无关数据,重复数据,平滑噪声数据,筛选掉与挖掘主体无关的数据,处理缺失值,异常值.
- 缺失值的处理:缺失值的处理分为3种方式:删除记录,数据补差,和不处理
- 数据补插方式:
-
使用固定值 将缺失值的属性值,用一个常量替换.如广州一个工厂普通外来务工人员的"基本工资"属性的空缺值可以用2015年广州市普通外来务工人员工资标准1895元/月,该方法就是使用固定值来填补 回归方法 对带有缺失值的变量,根据已有的数据和其他的有关的其他变量(因变量)的数据建立拟合模型来预测缺失值的属性值 均值/中位数/众数补插 根据属性值的类型,用该属性取值的平均数/中位数/众数进行插补 插值法 插值法是利用已知点建立合适的插值函数f(x),未知值由对应点xi求出的函数值,f(xi)近似代替 最近邻插补 在记录中找到缺失值与却只样本最接近的样本的该属性值插补 - 拉格朗日插值法:
- 根据数学知识,对于平面上已知的n个点(无两点在一条直线上)(那我觉的菏泽市一个散点图吧)可以找到一个n-1次多项式y=a0+a1x+a2x2+...+an-1xn-1次多项式:使这多项式曲线过这n个点
- 已知过n个点的n-1次多项式:y = a0 + a1x + a2x2 + ...+an-1xn-1
- 将n个点的坐标(x1,y1),(x2,y2)...(xn,yn)代入多项式函数,得
- 1 = a0 + a1x1 + a2x1 + ... + an-1x1n-1
- y2 = a0 + a1x1 + a2x22+ ... + an-1x2n-1
- ....
- yn = a0 + a1xn + a2xn2 + ... + an-1xnn-1
- 终极公式:
- 将缺失的函数值对应的点x代入插值多项式得到缺失值的近似值L(x).拉格朗日插值公式结果紧凑,在理论分析中很方便,但是当插值节点增减时,插值多项式就会随之变化,这在实际计算中时很不方便的,为了克服这一缺点,提出了牛顿插值法.
- 牛顿插值法
- 求已知的n个点对(x1,y1),(x2,y2)...(xnyn)的所有阶差商公式
- 差商:差商既均差,指导数的近似值,对等步长(h)的离散函数f(x),其n阶差商就是它的n阶差分与其步长n次幂的比值.例如n=1时,若差分取向前的或向后的,所得一阶差商就是函数导数的一阶近似,若差分取中心的则所得一阶差商时导数的二阶近似
- 拉格朗日插值实例:
-
import pandas as pd # 导入数据分析库pandas from scipy.interpolate import lagrange # 导入拉个朗日插值函数 data = pd.read_csv("./restaurant_sale.csv") # 读入数据 print data print data["sales"] data["sales"][(data["sales"] < 400) | (data["sales"] > 5000)] = None # 过滤异常值,将其变为空值 # 自定义列向量插值函数 # s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5 def ployinterp_column(s, n, k=5): y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] # 取数 y = y[y.notnull()] # 剔除空值 return lagrange(y.index, list(y))(n) # 插值并返回插值结果 # 逐个元素判断是否需要插值 for i in data.columns: print i # 拿到的是表格的title for j in range(len(data)): print j # 拿到的是每一个title对应的数据 if (data[i].isnull())[j]: # 如果为空即插值 print data[i] data[i][j] = ployinterp_column(data[i], j) # 执行自定义的拉格朗日插值函数 # 输出结果到文件中 data.to_csv("./sales.csv")
- 异常值处理
- 在数据预处理时,异常值是否剔除,需视具体情况而定,因为有些异常可能蕴含着有用信息
- 异常值处理常用方法
-
异常值处理方法方法描述
不处理 直接在具有异常值的数据集上进行挖掘建模 删除含有异常值的记录 直接将含有异常值的记录删除 平均值修正 可用前后两个观测值的平均值修正该异常值 视为缺失值 将异常值视为缺失值,利用缺失值处理的方法进行处理
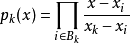
数据集成
- 数据挖掘需要的数据往往分布在不同的数据源中,数据集成就是将多个数据源合并存放在一个一致的数据存储(如数据仓库)中的过程,在数据集成时,来自多个数据源的现实世界实体的表达形式是不一样的,有可能不匹配,要考虑实体识别问题和属性冗余问题,从而将源数据在最底层上加以转换,提炼和集成.
- 实体识别:
- 实体识别:实体识别时指从不同数据源识别出现实世界的实体,它的任务是统一不同源数据的矛盾之处
- 同名异义:数据源A中的属性ID和数据源B中的属性ID分别描述的是菜品编号和订单号,即描述的是不同的实体(不同事物具有相同的属性,但描述的分别是对应实体的属性)
- 异名同义:数据源A中的sales_dt和数据源B中的sales_date都是描述销售日期,即A.sales_dt=B.sales_date.(实体之间属性的命名不同,但都是表示同一个东西,eg:供货商的出货日期=经销商的进货日期)
- 单位不统一:描述同一个实体分别用国际单位和中国的传统单位.
- 检测和解决这些冲突就是实体识别的任务
- 实体识别:实体识别时指从不同数据源识别出现实世界的实体,它的任务是统一不同源数据的矛盾之处
- 冗余属性识别:
- 数据集成往往导致数据冗余.
- 同一属性多次出现;
- 同一属性命名不一致导致重复
- 仔细整合不同数据源能减少甚至避免数据冗余与不一致,从而提高数据挖掘的速度和质量.对于冗余性要先分析,检测到后再将其删除
- 有些冗余属性可以用相关性分析检测,给定两个数值型的属性A和B,根据其属性值,用相关系数度量一个属性在多大程度上蕴含来那个一个属性.
- 数据集成往往导致数据冗余.