一:urllib库:
- urllib是Python自带的一个用于爬虫的库,器主要作用就是可以通过代码模拟浏览器发送请求.其被用到子模块在Python3中的urllib.request和urllib.parse,在Python2中是urllib和urllib2.
二,有易到难的爬虫程序:
- 爬取到百度页面所有的数据值
import urllib.request
import urllib.parse
if __name__ == '__main__':
# 指定爬取的网页url
url = "http://www.baidu.com"
# 通过urlopen含少数向指定的url发送请求,返回响应对象
response = urllib.request.urlopen(url=url)
# 通过调用响应对象中的read函数,返回响应客户端的数据值(爬取到的数据)
# data = response.read() # 返回的是byte类型,并非字符串
print(response) # <http.client.HTTPResponse object at 0x0000015ACAC57E80>
print(response.headers)
print(response.getcode()) # 200
print(response.geturl()) # http://www.baidu.com
# 补充说明
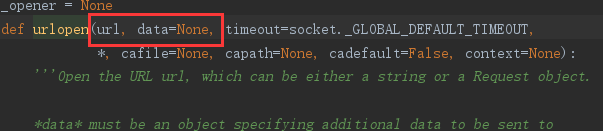
urlopen函数的原型:urllib.request.urlopen(),具体参数见下图
url参数:指定向那个url发起请求
data参数:可以将post请求中携带的参数封装成字典的形式传递给该参数
urlopen函数的响应对象,相关函数的调用介绍
response.headers: 获取响应头信息
response.getcode(): 获取响应状态码
response.geturl(): 获取请求的url
response.read(): 获取响应的数据(字节类型)
- 将爬取到的百度新闻首页的数据值写入文件进行存储
# -*- coding:utf-8 -*-
from urllib import request
import urllib.parse
if __name__ == '__main__':
url = "https://news.baidu.com/"
response = request.urlopen(url=url)
# decode()作用是是将响应中的字节(byte)类型的数据值转化成字符串类型
data = response.read().decode()
# 使用IO操作将data表示的数据值以"w"权限的方式写入到news.html
with open("./news.html","w") as fp:
fp.write(data)
print("写入完毕!!!") # 写出的文字不识别,是乱码!!!,编码有问题, 在文件开头申明的编码也不好使
- 爬取网络上某张图片数据u,存储到本地
#爬取网络上的图片
from urllib import request
# 下边这两行代码表示忽略https证书,因为下面请求的url为https协议的请求,如果请求不是https则该两行代码可不用 .
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
if __name__ == '__main__':
# url 是存放https协议的
url = "https://image.baidu.com/search/detail?ct=503316480&z=0&ipn=false&word=%E5%AE%8B%E6%85%A7%E4%B9%94&step_word=&hs=2&pn=20&spn=0&di=195362068990&pi=0&rn=1&tn=baiduimagedetail&is=0%2C0&istype=0&ie=utf-8&oe=utf-8&in=&cl=2&lm=-1&st=undefined&cs=2995972207%2C2611875489&os=366366976%2C3885463767&simid=3393796370%2C191512008&adpicid=0&lpn=0&ln=3750&fr=&fmq=1548471365943_R&fm=&ic=undefined&s=undefined&hd=undefined&latest=undefined©right=undefined&se=&sme=&tab=0&width=undefined&height=undefined&face=undefined&ist=&jit=&cg=star&bdtype=0&oriquery=&objurl=http%3A%2F%2Fpic.makepolo.net%2Fnews%2Fallimg%2F20161225%2F1482604638984064.jpg&fromurl=ippr_z2C%24qAzdH3FAzdH3Fgjof_z%26e3B4whjr5s5_z%26e3Bv54AzdH3Fmlcblld_z%26e3Bip4s&gsm=0&rpstart=0&rpnum=0&islist=&querylist=&force=undefined"
response = request.urlopen(url=url)
data = response.read() # 因为图片的数据值(二进制数据),则无需使用decode进行类型转换
# 存储到本地
with open("./xf.jpg", "wb") as fp:
fp.write(data)
print("写入完毕!!!")
三,url的特性:url必须为ASCII编码的数据值.所以我们在爬虫代码中编写url的时候,如果url中存在ASCII编码的数据值,则必须对其进行ASCII编码后,该url方可被使用
from urllib import request
from urllib import parse
if __name__ == '__main__':
# 原始url中存在ASCII编码的值,则该url无法被使用
# url = "http://www.baidu.com/s?ie=utf-8&kw=周杰伦"
# 处理url中存在的非ASCII数据值
url = "https://www.baidu.com/s?"
# 将带有非ASCII的数据封装到字典中,url中非ASCII的数据往往都是"?"后面键值参数的请求
param = {
"ie": "utf-8",
"wd": "周杰伦",
}
# 使用parse子模块中的urlencode函数将封装好的字典中存在的非ASCII的数值进行ASCII编码
param = parse.urlencode(param)
# 将编码后的数据和url进行整合拼接成一个完整可用的url
url = url + param
print(url)
# https://www.baidu.com/s?ie=utf-8&wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
response = request.urlopen(url=url)
data = response.read()
with open("./周杰伦.html", "wb") as fp:
fp.write(data)
print("写入完毕!!!")
五,通过自定义请求对象,用于伪装爬虫程序请求的身份
在请求头信息中有User-Agent参数,简称UA,该参数的作用是用于表名本次请求载体的身份表示.乳沟我们通过浏览器发起请求,则该请求的载体wi当前浏览器,则UA参数的值表名是当前浏览器的一种标识表示宜春数据,如果我们用爬虫程序发起一个请求,则该请求的载体为爬虫程序,那么该请求的UA爬虫程序的身份标识表示一串数据.有些网站会通过辨别请求的UA来判断请求载体是否为爬虫程序,如果为爬虫程序,则不会给该请求返回响应值,那么我们的爬虫程序无法通过发起请求爬取到该网站的数据,这也是反爬虫的一种初级手段.那么为了防止该问题的出现.则我们可以给爬虫程序的UA进行伪装,伪装成某款浏览器的身份标识
import urllib.request
import urllib.parse
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
if __name__ == "__main__":
#原始url中存在非ASCII编码的值,则该url无法被使用。
#url = 'http://www.baidu.com/s?ie=utf-8&kw=周杰伦'
#处理url中存在的非ASCII数据值
url = 'http://www.baidu.com/s?'
#将带有非ASCII的数据封装到字典中,url中非ASCII的数据往往都是'?'后面键值形式的请求参数
param = {
'ie':'utf-8',
'wd':'周杰伦'
}
#使用parse子模块中的urlencode函数将封装好的字典中存在的非ASCII的数值进行ASCII编码
param = urllib.parse.urlencode(param)
#将编码后的数据和url进行整合拼接成一个完整可用的url
url = url + param
#将浏览器的UA数据获取,封装到一个字典中。该UA值可以通过抓包工具或者浏览器自带的开发者工具中获取某请求,从中获取UA的值
headers={
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
#自定义一个请求对象
#参数:url为请求的url。headers为UA的值。data为post请求的请求参数(后面讲)
request = urllib.request.Request(url=url,headers=headers)
#发送我们自定义的请求(该请求的UA已经进行了伪装)
response = urllib.request.urlopen(request)
data=response.read()
with open('./周杰伦.html','wb') as fp:
fp.write(data)
print('写入数据完毕')