1,分页:分页DRF提供三种 分页方式:
- /////?page=1&size=5分页
- 限制的那种limit/offset分页
- 油表分页,默认有上一页和下一页
2,PageNumberPagination的源码如下:
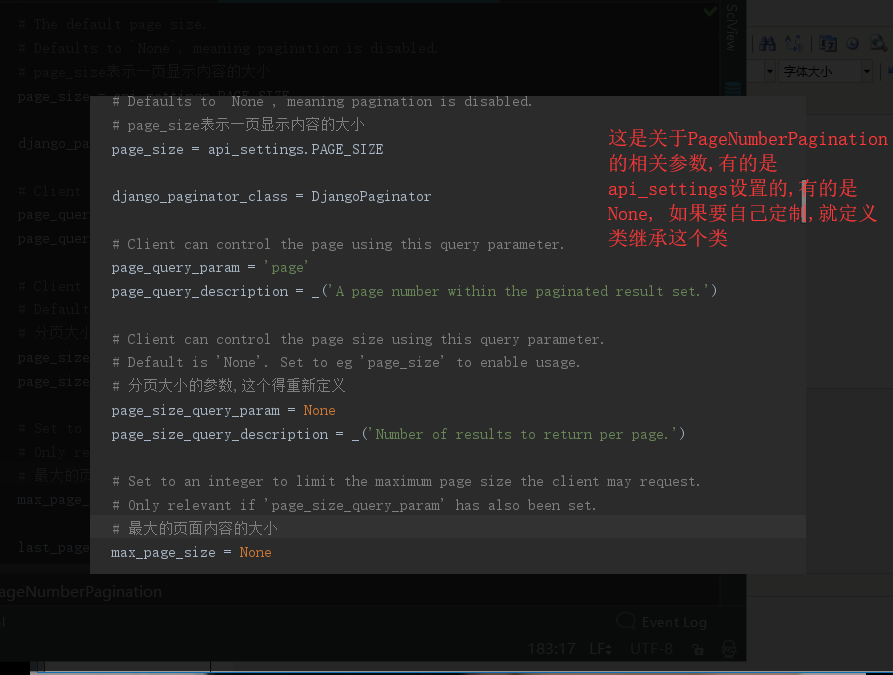
3,LimitOffsetPagination分页器的源码:

4,cursorPaginator油表的源码:

5,分页器的代码:
from rest_framework import pagination
# 第一种是page/size分页
class MyPaginator(pagination.PageNumberPagination):
# 设定一页显示多少内容
page_size = 2
page_query_param = "page"
page_size_query_param = "size"
max_page_size = 3
# 第二种是限制的那种方法limit/offset分页
class LimitOffsetPaginator(pagination.LimitOffsetPagination):
# 默认限制的是1
default_limit = 1
# limit查询的参数一页显示的内容是多少
limit_query_param = "limit"
# 一条数据显示多少内容.
offset_query_param = "offset"
# 游标分页,默认有上一页和下一页
class CursorPaginator(pagination.CursorPagination):
cursor_query_param = "cursor"
ordering = "id"
page_size = 2
6,三种分页方法都有一个共同的方法


7,分页的view的代码:
from utils.pagination import MyPaginator, LimitOffsetPaginator, CursorPaginator
# 写一个终极版本就三行
class BookModelView(viewsets.ModelViewSet):
# 获取用户匹配的对象
# 获取序列化器
queryset = Book.objects.all()
serializer_class = BookSerializer
# 实例化分页器的对象
pagination_class = MyPaginator # 不加括号,源码里边加了
# 这是page和size分页的方式
class PageBookView(APIView):
# 写一个get方法
def get(self, request):
# 获取到数据库中所有的数据
queryset = Book.objects.all()
# 实例化分页器
page_obj = MyPaginator()
# 用自己写好的分页器进行分页,在源码中会提供paginate_queryset的方法
page_data = page_obj.paginate_queryset(queryset, request)
# 将分页后的数据序列化
ser_obj = BookSerializer(page_data, many=True)
# 给相应填加上一页和下一页
# 实例化paginator的对象会提供一个get_paginated_response的方法就会有上一页和下一页的显示
return page_obj.get_paginated_response(ser_obj.data)
# 这是limit和offset的分页
class LimitBookView(APIView):
# 写一个get方法
def get(self, request):
# 获取数据库中的所有数据
queryset = Book.objects.all()
# 实例化分页器的对象,就会有分页器的所有属性和方法
page_obj = LimitOffsetPaginator()
# 用自己写好的分页器进行分页,在源码中会提供paginate_queryset的方法
page_data = page_obj.paginate_queryset(queryset, request)
# 将分页后的数据序列化
ser_obj = BookSerializer(page_data, many=True)
# 给相应添加上一页和下一页
# 实例化的分页器的对象会提供一个get_paginated_response的方法会提供上一页和下一页
return page_obj.get_paginated_response(ser_obj.data)
# 油表的那种分页,默认有上一页和下一页
class CursorBookView(APIView):
# 手写一个get方法
def get(self, request):
# 从数据库中获取书籍的对象
queryset = Book.objects.all()
# 实例化分页器对象,就会有分页器的所有属性和方法
page_obj = CursorPaginator()
# 将获取到的数据进行分页处理(第一个是要分页的数据, 第二个是请求request)
page_data = page_obj.paginate_queryset(queryset, request)
# 将分页后的数据序列化
ser_obj = BookSerializer(page_data, many=True)
# 给相应的加上上一页和下一页
# 实例化的分页器的对象会提供一个get_paginated_response的方法会提供上一页和下一页
return page_obj.get_paginated_response(ser_obj.data)
8,解析器:
- Django的解析器:当请求进来的时候,请求体在request.body中,那也就证明,解析器会把解析好的数据放入request,body中,我们在视图中可以打印request的类型,能够知道request是WSGIRequest这个类,源码分析如下:
from django.core.handlers.wsgi import WSGIRequest

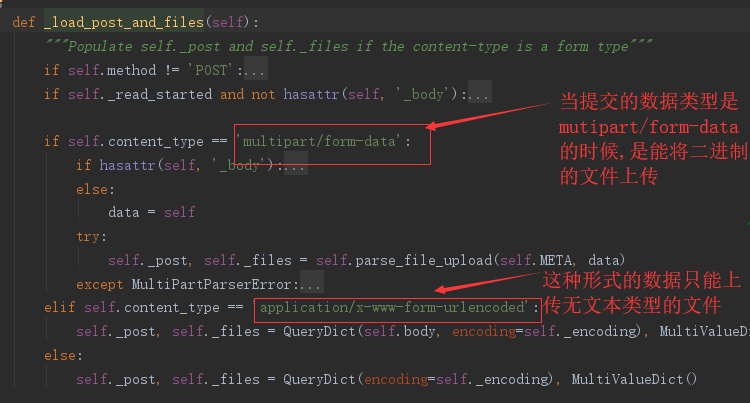
这样就能实现多种类型的文件上传
一个解析到request.POST中,一个解析到request.FILES中,也就是说我们之前能在request中能得到各种数据是因为用了不同的数据解析器
9,DRF的解析器
解析器,顾名思义是将请求提交的数据进行解析,因此解析数据只能存在于request,data提交数据的时候
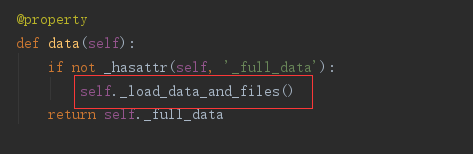
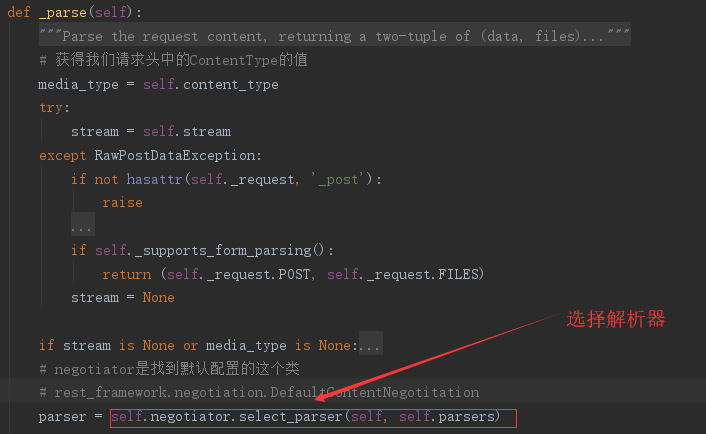
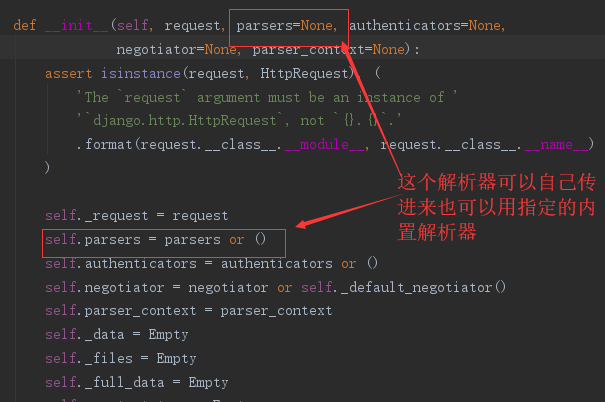

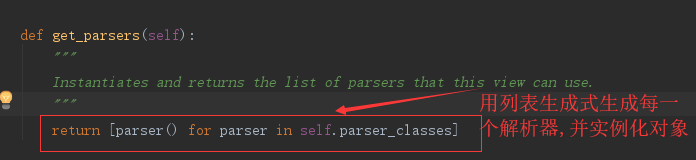

from rest_framework.negotiation import DefaultContentNegotiation
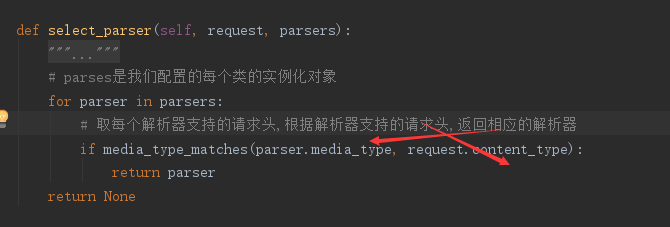
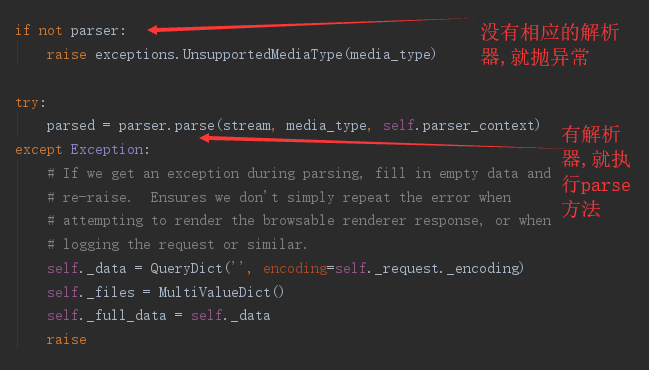
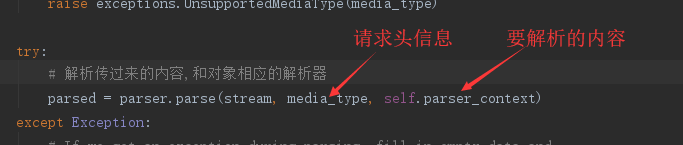
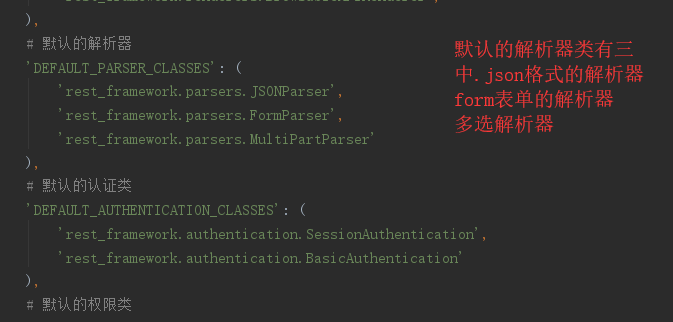
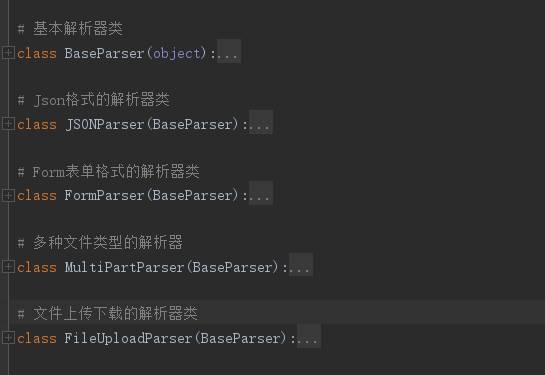
自己配置视图的解析器

10,DRF的渲染器

我们在浏览器中展示的DRF测试页面,就是通过浏览器的渲染器来做到的