Hadoop运行环境选择
搭建一个虚拟机,然后再在这个虚拟机上直接安转部署Linux操作系统来实现Linux运行环境。(windows不安全)
虚拟机(虚拟化软件)的介绍:
vmware,virtualbox--------查看相关安装教程https://zhuanlan.zhihu.com/p/34798226
vmware:安装linux相关软件(centos,ubuntu,小红帽基于此可以实现linux操作系统)
Xshell相关操作:
1.sudo:权限问题----当进行某些操作时,在操作前加上sudo即可,无需转换到root用户-------输入visudo
2.主机名修改:永久-----vi /etc/sysconfig/network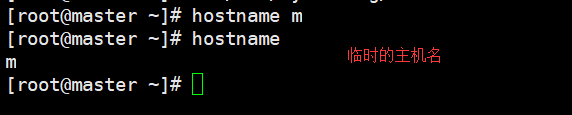

3.网络配置
4.防火墙:a、是什么:对服务器的保护 b、为什么:但是会妨碍集群之间的通信c、如何关闭:通过命令行进行关闭
5.ssh(secureshell):a.是什么:在应用程序中提供通信的一个安全协议,通过ssh可以进行网络数据的安全传输,原理是非对称加密,
b.为什么配置:Hadoop的目的是在主节点启动进程或者关闭时,从节点可以自动做相关操作,使用免密码登陆从节点
c.如何配置:首先明确为哪一个用户配置免密码登陆-----创建文件夹,生成密钥对,拷贝进入认证文件,赋予权限
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://test:9000</value> </property> <property>
<--io文件缓存大小,作用:缓存大提供更高的数据传输效率,但也意味着更大的内存消耗。一般为默认值(4096)的整数倍(以字节为单位)--> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/data/tmp</value> </property> <property>
<--权限--> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> </configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dfs/data</value>
<final>true</final>
</property>
<property>
<--datanode数量要大于副本数量-->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
,<--dfs进行操作时,不进行权限检查,举例:这样可以显示目录对应的子目录-->
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
<configuration> <property>
<--新版本的运行框架名称****老版本是jobtracker&&&&&由此需要配置yarn配置文件--> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property>
<--aux辅助--> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
slaves------配置的是datanode节点
test
搭建三个节点的改变
1、datanode的变化------在slaves中增加datanode主机名
2、其他节点进行克隆------日常记得进行虚拟机的快照,记住克隆时的虚拟机状态(记得创建完整克隆)
#java export JAVA_HOME=/home/hadoop/app/jdk1.7.0_79 export JAVA_JRE=JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/lib export PATH=$PATH:$JAVA_HOME/bin #hadoop export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile 使全局变量生效,其他不需要
4、格式化namenode----a、为什么要格式化namenode------在Hadoop的HDFS部署好了之后并不能马上使用,要进行格式化,要对hdfs文件系统中的datanode进行分块,因为hdfs启动时要明确有哪些datenode,并且datanode要向namenode注册,在写文件是才知道数据在向哪些datanode写的,在此之前要建立nn和dn对应关系,原始的数据要存储在namenode中,因此需要进行格式化,在namenode中开辟命名空间。
b、格式化多少次 ------仅格式化一次即可
c、多次出现格式会出现什么问题(如何解决)导致命名空间的id不一样--------解决方式1、修改命名空间的id 2、删除缓存目录,重新格式化
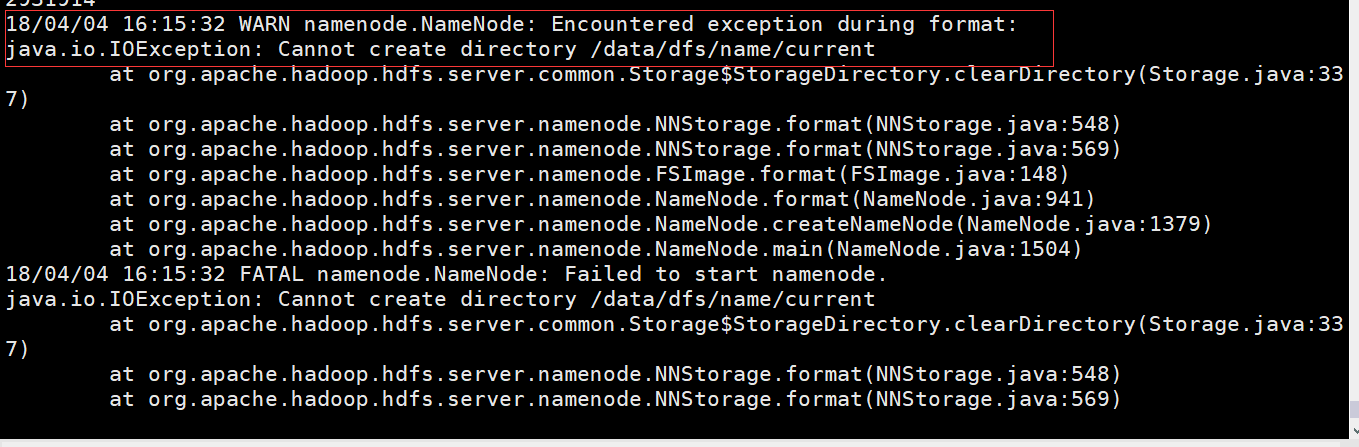
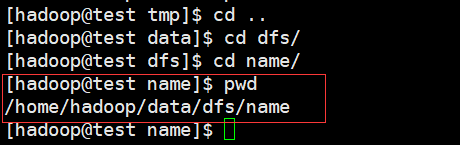
格式化时出现以上问题,请检查core-site.xml,hdfs-site.xml这两个配置文件中关于dfs.namenode.name.dir***dfs.datanode.data.dir****hadoop.tmp.dir路径与本机文件路径(pwd查看是否一致)是否一致,即可解决,
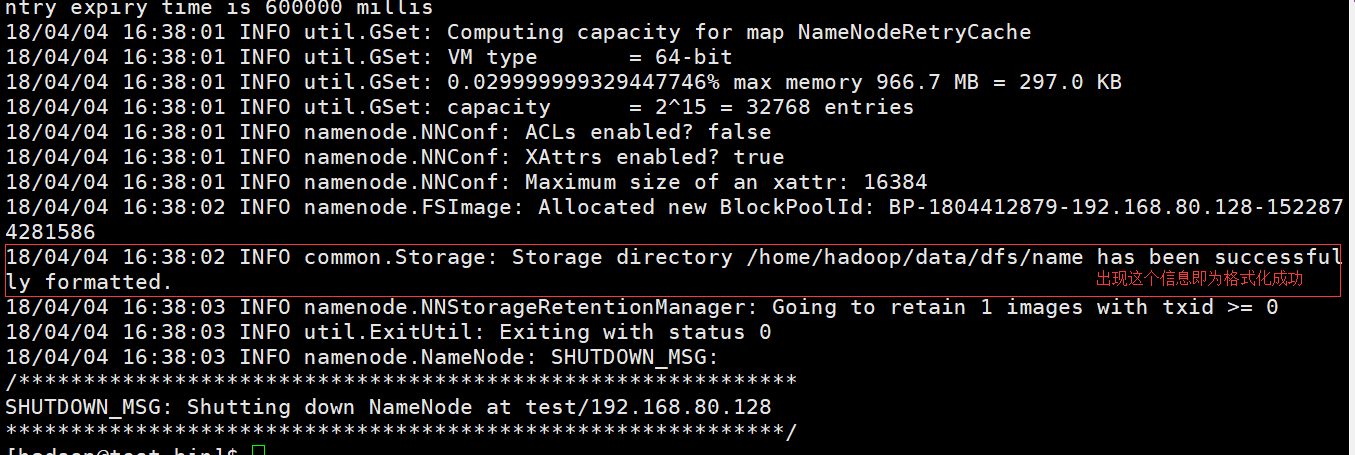
或者另外两种方式:(未实验,仅供参考)
解法一:帮 /home/hadoop 加入其他使用者也可以写入的权限
sudo chmod -R a+w /home/hadoop/tmp
解法二:改用 user 身份可以写入的路径 hadoop.tmp.dir 的路径 - 修改 core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value>
</property>
5.启动集群
目录:/home/hadoop/app/hadoop-2.6.0/sbin
命令:./start-all.sh
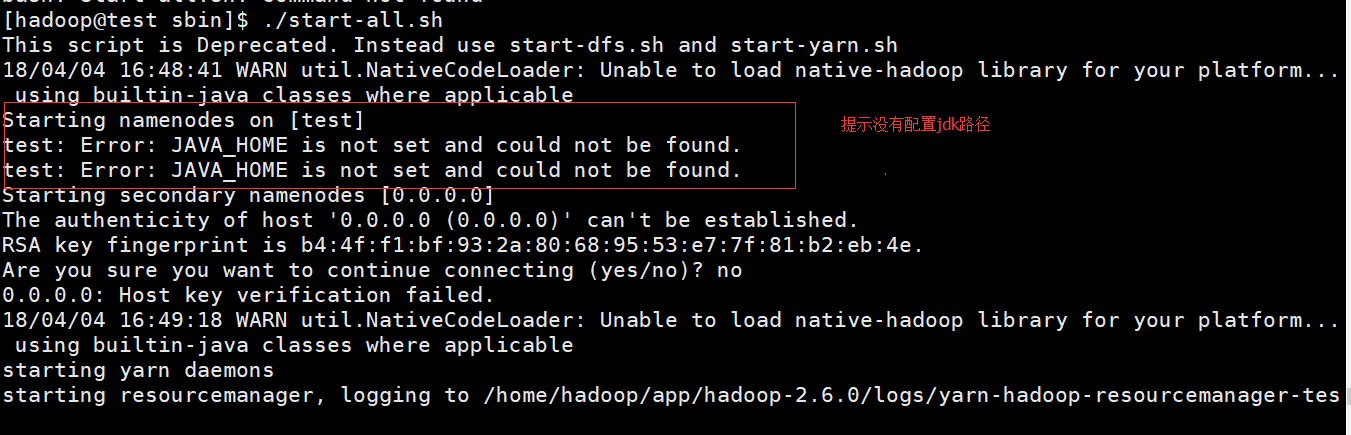
解决措施:在配置文件hadoop-env.sh中加入jdk路径

重新启动,输入jps显示成功,出现以下进程
[hadoop@test sbin]$ ./start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh 18/04/04 16:50:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [test] test: starting namenode, logging to /home/hadoop/app/hadoop-2.6.0/logs/hadoop-hadoop-namenode-test.out test: starting datanode, logging to /home/hadoop/app/hadoop-2.6.0/logs/hadoop-hadoop-datanode-test.out Starting secondary namenodes [0.0.0.0] The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established. RSA key fingerprint is b4:4f:f1:bf:93:2a:80:68:95:53:e7:7f:81:b2:eb:4e. Are you sure you want to continue connecting (yes/no)? yes 0.0.0.0: Warning: Permanently added '0.0.0.0' (RSA) to the list of known hosts. 0.0.0.0: starting secondarynamenode, logging to /home/hadoop/app/hadoop-2.6.0/logs/hadoop-hadoop-secondarynamenode-test.out 18/04/04 16:52:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable starting yarn daemons resourcemanager running as process 2216. Stop it first. test: starting nodemanager, logging to /home/hadoop/app/hadoop-2.6.0/logs/yarn-hadoop-nodemanager-test.out [hadoop@test sbin]$ jps 2672 DataNode 2216 ResourceManager 2594 NameNode 2848 SecondaryNameNode 3039 NodeManager 3069 Jps
接下来运行hadoop自带的程序wordcount来测试,类似于java中的hello word程序,此处不再重复。
本文欢迎补充为什么初次部署hadoop集群要格式化namenode原因,要通俗,百度的答案就不要写了。