Hadoop HA 如何实现?简述过程
HA:High Available(高可用)
说明1:Hadoop的高可用是hadoop2.X版本及以上的特性;hadoop HA通过zookeeper来实现namenode的高可用;
过程:现在hadoop集群里面搭建了一个zookeeper的集群,同时这个zookeeper的共享池通过多个其他的节点来实现,然后通过在另一个机架服务器上已经配好了一个standby的namenode,然后整个hadoop的集群现在有一个处于active的namenode,通过zookeeper告诉client和从节点有这样一个standby的namenode,然后active-namenode定期产生的edits会交互到这个共享池里面,如果active-namenode宕机,则standby-namenode通过共享池里面的edits进行热备份立马恢复所有的fsimage,最终成为新的active-namenode。
自动切换:通过使用zookeeper来实现NameNode自动切换。通过
执行命令hdfszkfc -formatZK来启动ZKFailoverController组件,并格式化ZooKeeper,如果之前没有在Standby同步元数据还需要同步元数据。
ZKFailoverController主要用于总体控制主备的切换,在启动过程中会初始化HealthMonitor和ActiveStandbyElector组件,并且向这两个组件注册回调函数。
HealthMonitor: 主要是监控NameNode的健康状态,一旦检测到NameNode发生变化,就会回调ZKFailoverController的方法进行主备选举
ActiveStandbyElector: 主要是进行自动的主备选举,内部封装了ZK的逻辑,一旦ZK主备选举完成,就会调用ZKFailoverController方法进行主备切换。
主备切换流程图示:
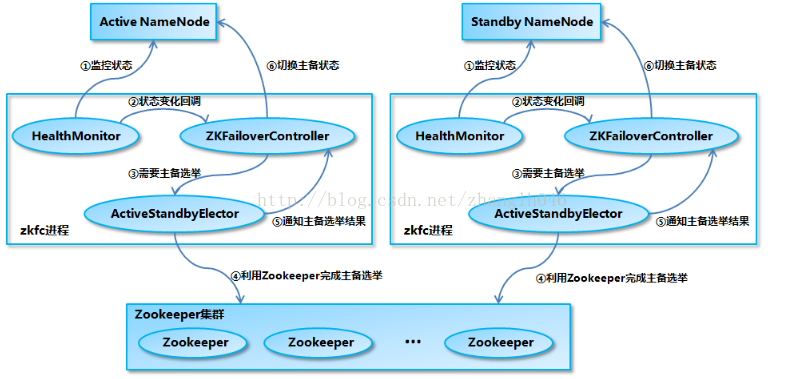
总结:高可用:active、standby被zookeeper的zkfc进程的healthMonitor监控,状态改变是,使用ZKFailoverController进行主备选举(选举通过zk实现),选举后使用ZKFailoverController进行状态切换。切换通过zk共享池中的edits进行热备份立马恢复所有的fsimage,最终成为新的active-namenode。
SecondaryNameNode就是来帮助解决edit logs在namenode启动时,将edit logs合并到fsimage中,使其有一个最新的时间快照保存,但是当edit logs过大时,合并时间久,且会造成namenode启动慢,所以SecondaryNameNode它的职责是合并NameNode的edit logs到fsimage文件中。
https://blog.csdn.net/m0_37461645/article/details/84929891
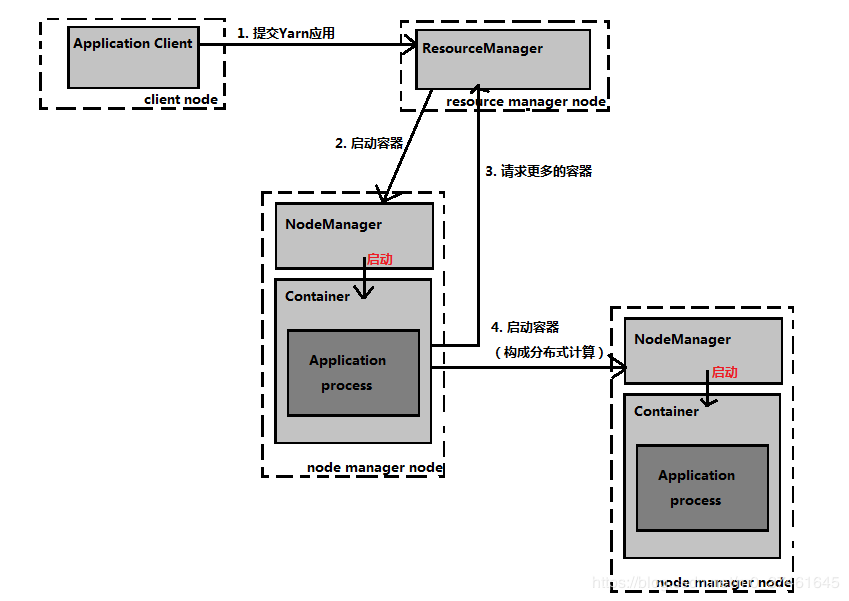
1、Yarn的大致结构
Resource Manager(RM,资源管理器):负责整个系统的资源管理和分配,并且由Scheduler和Application Manager组成;
Scheduler(调度器):根据容量、队列等,将系统中资源分配给各个正在运行的应用程序;
Application Manager(ASM,应用程序管理器):负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动Application Master、监控Application Master运行状态并在失败时重新启动它等;
Application Master(AM)用户提交的每个应用程序均包含一个AM,主要功能包括:与RM协商以获取资源(用Container表示)、与NM通信启动或停止任务、监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务;
Node Manager(NM,节点管理器):是每个节点的资源和任务管理器。一方面,定时地向RM汇报本节点上的资源使用情况和各个container的运行状态;另一方面,接受并处理来自AM的Container通信;
Container:是Yarn上的资源抽象,封装了某个节点上的内存、CPU资源,当AM向RM申请资源时,RM为AM返回的资源便是使用Container表示。一个任务对应一个Container。
2、RM(ResourceManager)和NM(NodeManager)的交互
RM负责找到一个能够在容器中启动application master的NM-节点管理器;
NM会定时的向RM汇报本节点上的资源使用情况和各个container的运行状态。
3、Yarn是如何分配任务的?
首先,客户端联系资源管理器,要求它运行一个Application Master进程;然后,资源管理器找到一个能够在容器中启动Application Master的节点管理器。之后可能只是做一个简单的运算,也有可能需要向资源管理器请求更多的容器,用以完成一个分布式计算。
4、Yarn中的调度器(具体内容建议翻阅《Hadoop权威指南》)
三种调度器:FIFO Scheduler、Capacity Scheduler、Fair Scheduler
1)FIFO调度器:将应用放置在一个队列中,然后按照提交的顺序(先进先出)运行应用;
2)容量调度器:允许多个组织共享一个集群资源,一个组织被配置一个专门的队列,在每个队列中,使用FIFO调度策略对应用进行调度;
3)公平调度器:在同一个队列中的应用会得到相同的资源运行。
5、Yarn的优势
可扩展性(Scalability):根据《Hadoop权威指南》所说,利用其资源管理器和application master分离的架构优点,可以扩展到面向近万个节点和近十万个任务;
可用性(Avaliability):相比较之前JobTracker的高可用,Yarn将其分而治之:先为资源管理器提供高可用性,再为Yarn应用(针对每个应用)提供高可用性;
利用率(Utilization):一个节点管理器管理一个资源池,对资源是精细化管理的;
多租户(Multitenancy):MapReduce只是Yarn应用中的一个。