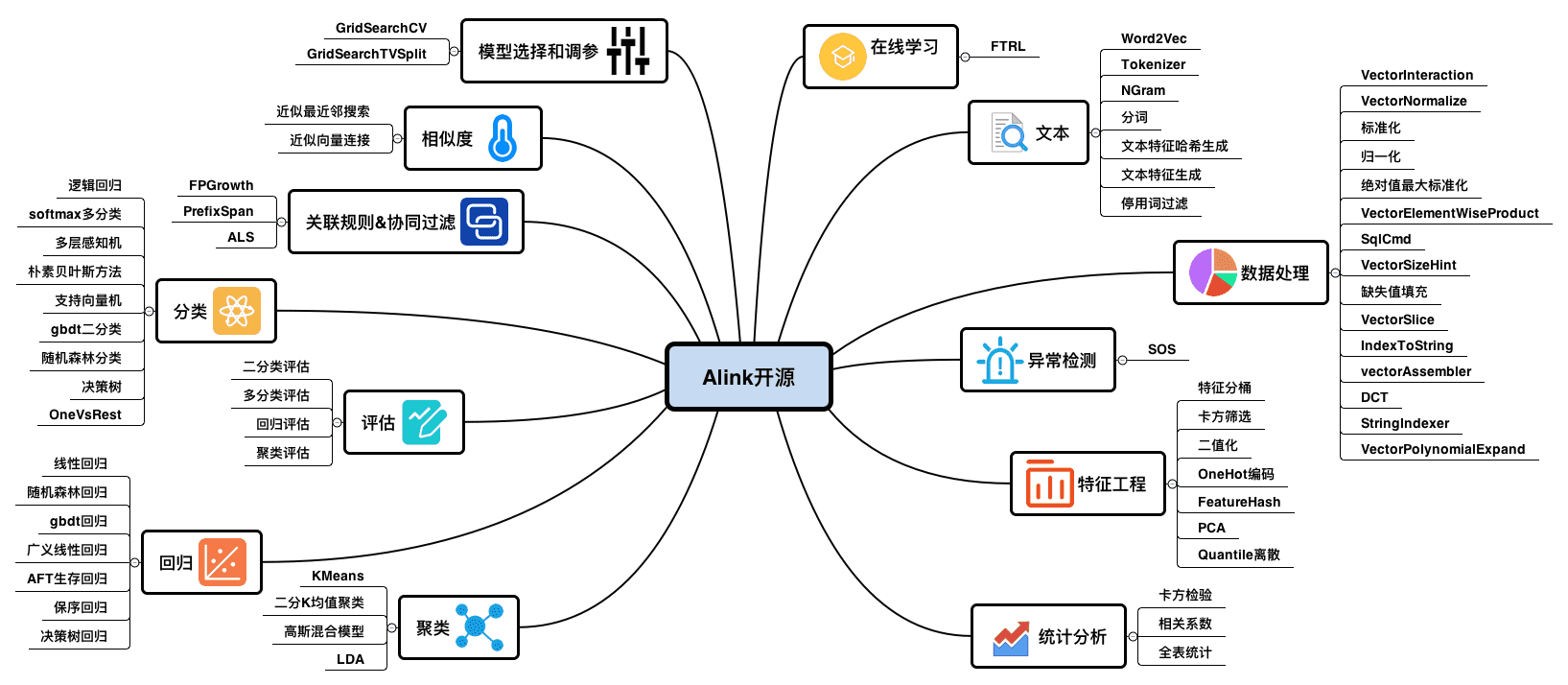
一、Alink结构简析
-
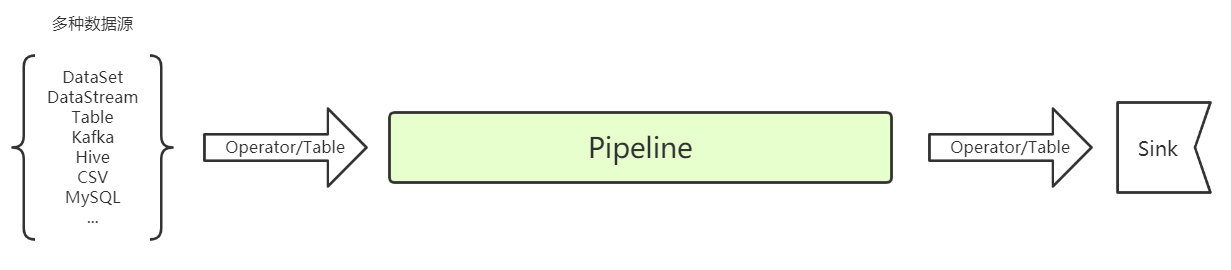
Pipeline结构
- 算法、预处理、特征工程等组件可加载进pipeline进行训练预测,组件也可单独使用
- pipeline构成如下:
-
数据源
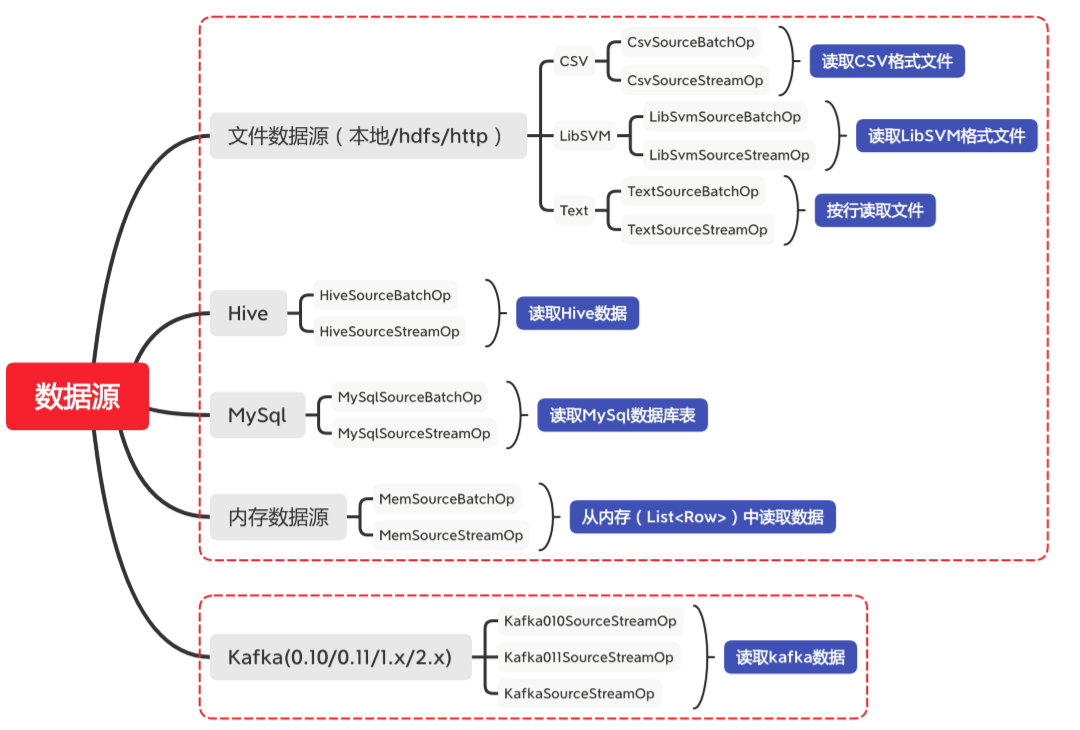
- Alink对各种数据源的操作均为包装成Operator,批与流采用不同Operator。同时,Pipeline也支持Table数据源的输入,但其后续处理也是包装成TableOp,使用外部源Table时要注意设置Environment和Pipeline相同
- Alink可以对以上数据源直接获取,也可对Flink的DataSet/DataStream包装为Operator
-
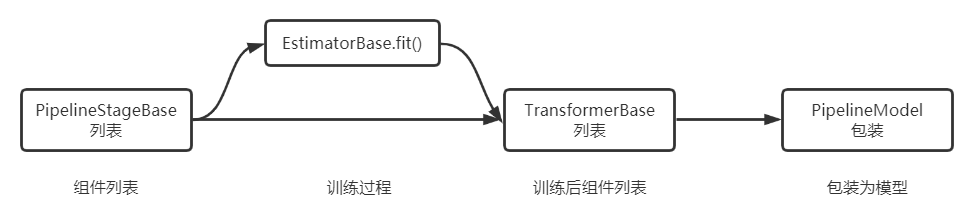
批式/流式算法通用的串联方式
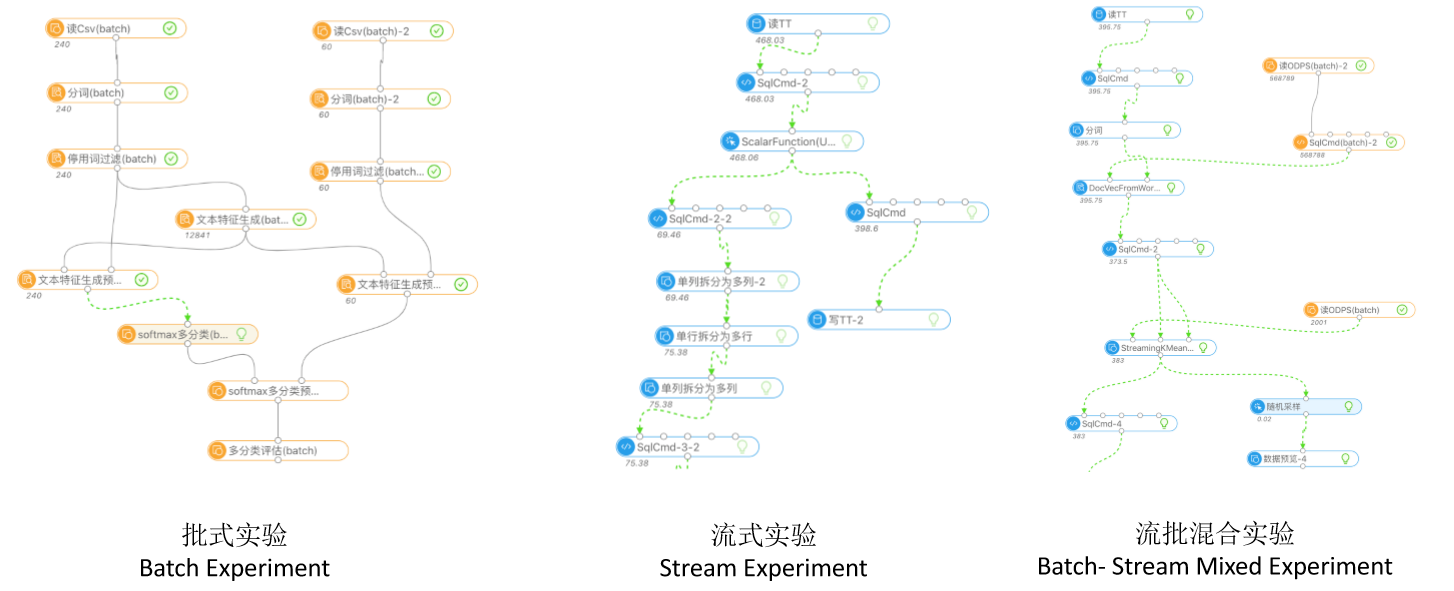
- Alink的fit和transform过程是同时支持BatchOperator和StreamOperator的,大部分数据处理等组件均支持,但根据实际使用的算法,fit过程对pi与流的支持是不同的。
- 训练后或保存的model即可预测批数据也可预测流数据
- 逻辑回归训练/预测过程示例

linkFrom内部完成各业务处理逻辑,同时该部分可继承EstimatorBase或TransformerBase形成PipelineStage
二、Alink使用介绍
-
使用概览
Pipeline pipeline = new Pipeline( new Imputer() .setSelectedCols("review") .setOutputCols("featureText") .setStrategy("value") .setFillValue("null"), new Segment() .setSelectedCol("featureText"), new StopWordsRemover() .setSelectedCol("featureText"), new DocCountVectorizer() .setFeatureType("TF") .setSelectedCol("featureText") .setOutputCol("featureVector"), new LogisticRegression() .setVectorCol("featureVector") .setLabelCol("label") .setPredictionCol("pred") ); //pipeline.add(PipelineStage组件,index) PipelineModel model = pipeline.fit(source); model.save(filepath); PipelineModel model =PipelineModel.load(modelPath); model.transform(dataOperator); //可以model.getLocalPredictor("review string").map(row)形式进行本地预测 Operator.execute(); - 数据获取/保存
1)hive示例
data = HiveSourceBatchOp() .setInputTableName("tbl") .setPartitions("ds=2022/dt=01,ds=2022/dt=02").setHiveVersion("2.0.1") .setHiveConfDir("hdfs://192.168.99.102:9000/hive-2.0.1/conf") .setDbName("mydb") sink = HiveSinkBatchOp() .setHiveVersion("2.0.1") .setHiveConfDir("hdfs://192.168.99.102:9000/hive-2.0.1/conf").setDbName("mydb") .setOutputTableName("tbl_sink") .setOverwriteSink(True)2)Kafka
Kafka011SinkStreamOp sink = new Kafka011SinkStreamOp() .setBootstrapServers("localhost:9092") .setDataFormat("json") .setTopic("iris");3)DataSet
DataSetWrapperBatchOp op = new DataSetWrapperBatchOp(dataSet,filedNames,fieldTypes);
- Alink算法与组件