内容:
1、GPU计算神经网络加速原理
2、脉动阵列计算神经网络原理
3、谷歌TPU架构
4、脉动阵列
参考文献
1、GPU计算神经网络加速原理
GPU实现神经网络加速优化的关键方式是并行化与矢量化,一种最常见的GPU加速神经网络的模式为通用矩阵相乘(General Matrix Multiply),即将各类神经网络核心计算展开为矩阵计算的形式。
下面以卷积神经网络中的加速计算对GPU加速原理进行分析。
卷积:卷积操作如下图所示神经网络中的卷积通过卷积核在特征图上以特定步长平移滑动,通过计算卷积核和特征图上与卷积核相同大小的数据块进行相乘求和,得出输出特征图像上的一个单元点的输出。
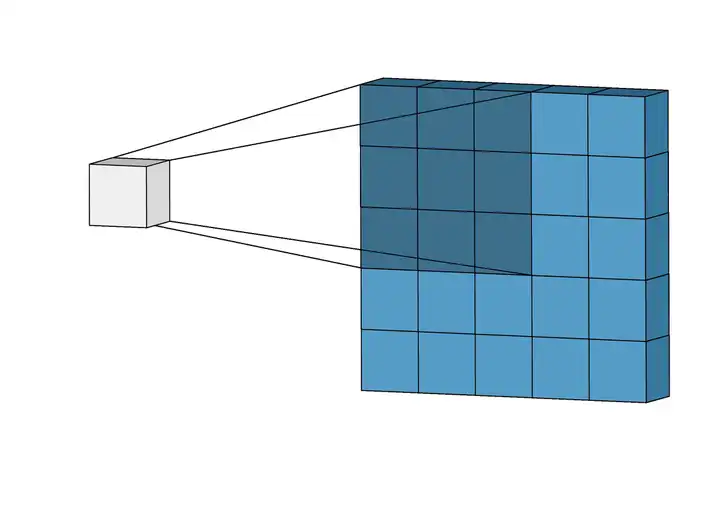
GPU进行卷积加速
GPU上无法直接支持卷积计算,所以在GPU上进行卷积计算时,需要首先将卷积核和特征图按照特定的规律进行预处理展开,称为Img2Col方法。
Img2Col操作如下图所示,以3✖3✖2的特征图和2✖2✖2✖2的卷积核为例,计算操作如下:
- 将每个周期通道1和通道2参与卷积计算的数据按行按列展开,通道1在上通道2在下排成一列。由于需要进行4次计算,因此展开为8✖4的矩阵。
- 同理将卷积核W和G分别按行按列展开,通道1在前通道2在后展开为1行。由于有两个卷积核,所以将两行展开的卷积核按行拼接为2✖8的矩阵。
- 将特征图矩阵和卷积核矩阵进行矩阵乘法,得到2✖4的输出矩阵,其中每一行代表一张输出特征图。

GPU加速局限:
当神经网络的通道数过多造成矩阵过大,以至于GPU无法在将所有通道展开。则需要根据GPU的算力选择部分通道先进行矩阵计算,并输出中间计算结果;再将所有中间计算结果累加得到最终的输出。
GPU单指令多线程处理:
从上图可以观察到,对于展开后的矩阵相乘,左矩阵的每个行向量与右矩阵的每一列向量的操作相同(乘和累加),但是作用于不同的数据上。GPU采用单指令多线程进行处理,每个线程同步的在不同的数据上执行相同的指令流,可以并行化计算。针对上述例子,GPU可以同时使用8个线程进行并行计算。每个线程可在每个周期内并行执行一次乘加计算,多个线程独立并行执行。多线程执行流程如下图所示,理性情况下8个周期即可输出所有点。

2、脉动阵列计算神经网络原理
脉动阵列
是一个二维的滑动阵列,其中每一个节点都是一个脉动计算单元,每个单元在一个周期内完成一次乘加操作。计算单元之间通过横向或纵向的数据通路实现数据的传递。
优点:
- 结构简单,规整,模块化强,可扩充,非常适合VLSI实现;
- PE单元见数据通信距离短,规则,便于数据流和控制流的设计,同步控制等;
- 计算并行度高,脉动阵列中所有单元可以同时计算,可通过流水获得很高的运算效率和吞吐率。
缺点:
- 具有一定的专用性,限制了应用范围。
加速流程
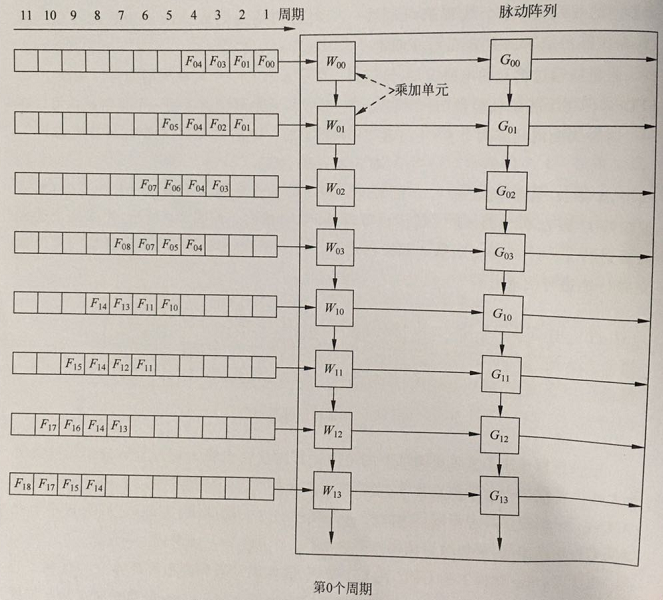
以3✖3✖2的特征图和2✖2✖2✖2的卷积核在8✖2的脉动阵列计算为例,卷积核权重固定在PE单元中,特征值横向脉动传递,中间计算结果纵向脉动传递,计算操作如下:
周期0:两个卷积核W和G的权重静态存储在脉动阵列的计算单元中,同一卷积核的权重排列在同一列;将输入特征图F按列展开,每行相隔一个周期;
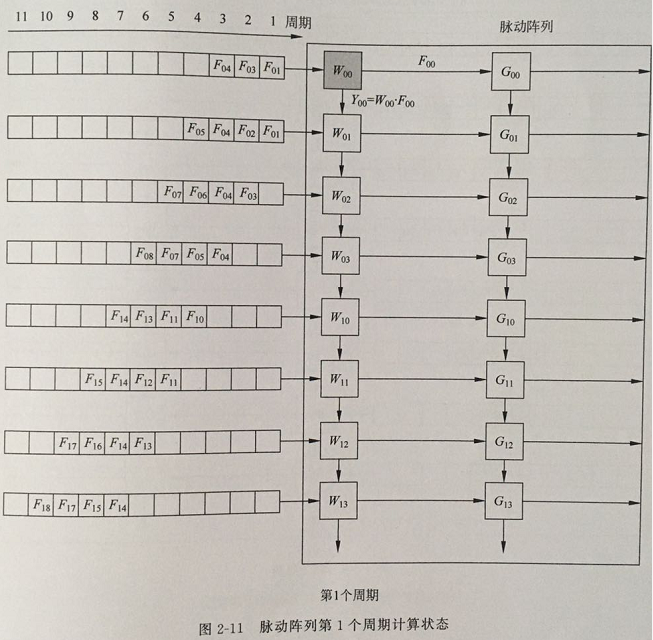
周期1:输入特征图F00进入W00单元,并与W00计算得到Y00的中间计算值;
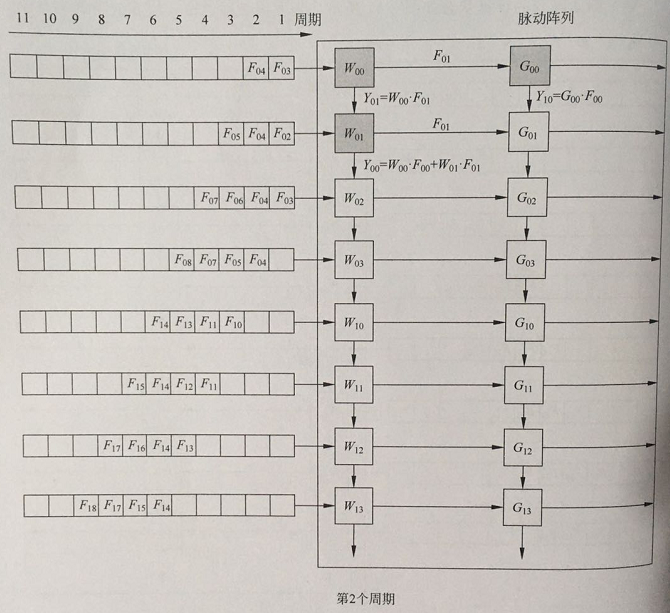
周期2:
横向:F00向右脉动传递至G00单元,计算第二张输出特征图的Y10的第一个中间计算值;
纵向:第二行特征图的F10进入计算单元W01并与其进行计算,计算结果与W00传递的F00中间计算结果累加获得F00的第二个中间计算结果。
同时F01进入W00计算Y01的第一个中间计算结果
以此类推,输入的特征值沿着脉动阵列的行方向不断开启不同卷积核的中间计算结果,而对应着输出特征图的输出点沿着列方向不断进行乘累加。
周期8:在第一列脉动阵列的最后一个计算单元,进行Y00的最后一个中间计算结果的乘累加,得到第一个输出特征图的第一个点。 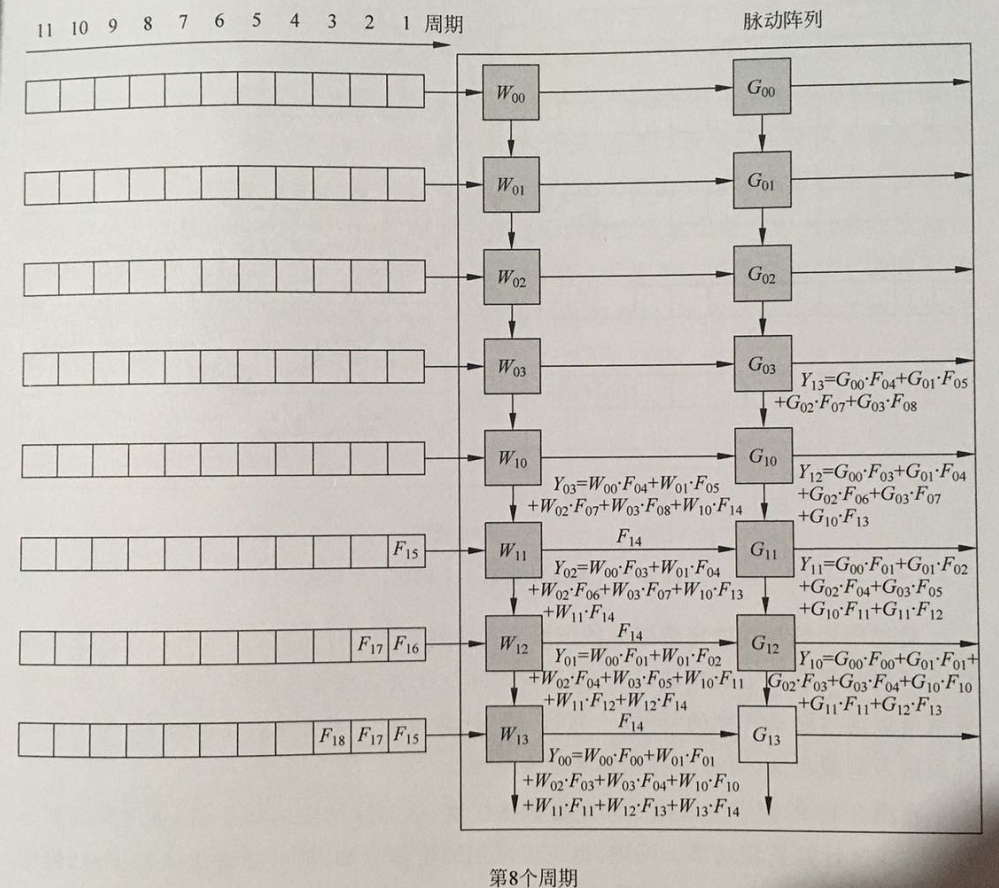
周期9:第一列计算单元输出第一张输出特征图的第二个点,第二列计算单元输出第二张输出特征图的第一个点。
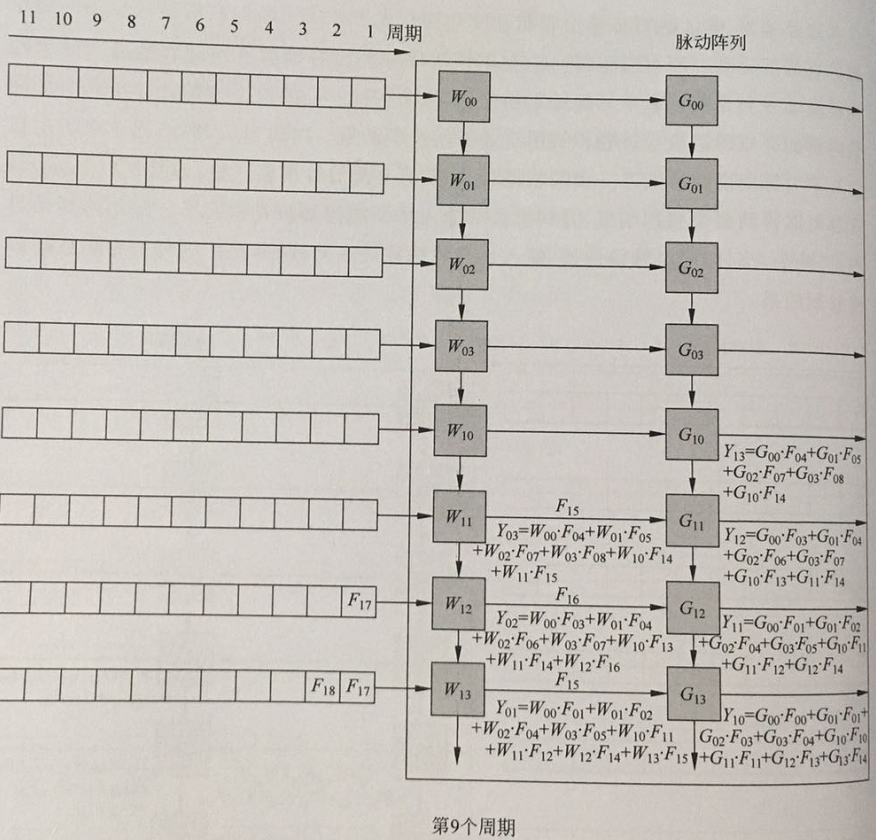
以此类推,每个周期都输出对应输出特征图的点,直至输出所有所有特征图,完成脉动阵列计算卷积神经网络。
启动时间:
脉动阵列的计算方式决定了数据必须按照事先安排好的顺序依次进入,所以每次要填满整个阵列(使计算并行度最大)需要一定的启动时间,这段时间会造成硬件资源的浪费。
启动时间=行数+列数-1 (不是max{行数,列数}-1吗?),当度过启动时间后整个脉动阵列的并行度和吞吐量才达到最大。
脉动方式:
上述例子使用的脉动方式是:固定卷积核权重,横向脉动输入特征值,纵向脉动部分和。实际上可以任意选择脉动这三个变量中的两个,固定其中一个进行卷积,如:固定部分和,脉动特征值和权重的方式实现卷积计算。
脉动阵列大小设计:
脉动阵列的大小由行数和列数组成。这二者可以相等,也可以不相等。
上述实例中脉动阵列的行数与卷积核的大小相同,列数与输出通道数相同。实际中如果卷积核非常大,或者通道数非常多,采用上述方式构建脉动阵列会过于庞大且不利于硬件实现。
为解决上述问题,一般采用分割计算、末端累加等方式解决这一问题,即将多通道的权重数据分割成几个部分,每个部分都能够适合脉动阵列的大小,然后依次对各部分进行计算,最终在阵列底部的累加器中计算出最终结果。
3、谷歌TPU架构
架构组成:脉动阵列、矢量计算单元、主结构模块、队列模块和统一缓存区。
计算流程:

4、脉动阵列
https://www.doc88.com/p-081712870059.html
https://www.zhihu.com/search?type=content&q=%E8%84%89%E5%8A%A8%E9%98%B5%E5%88%97
参考文献
《昇腾AI处理器架构与编程》