数据结构
Memcached中实现了高性能的hashtable。其解决hash冲突的方法采用拉链法。当hashtable 中存储的item个数大于容器大小的1.5倍的时候通知线程进行hashtable 扩容,为了保证在扩容期间的读写性能,扩容线程默认每次只迁移一个bucket。设置一个变量标识当前的迁移进度,在进行读写操作时根据此变量确定是去 old_hashtable 还是 primary_hashtable 进行操作。
在了解hashtable的各种操作之前,我们先了解下Memcached储存数据的基本结构。
1 //item的具体结构 2 typedef struct _stritem { 3 //记录下一个item的地址,主要用于LRU链和freelist链 4 struct _stritem *next; 5 //记录上一个item的地址,主要用于LRU链和freelist链 6 struct _stritem *prev; 7 //记录HashTable的下一个Item的地址 8 struct _stritem *h_next; 9 //最近访问的时间,只有set/add/replace等操作才会更新这个字段 10 //当执行flush命令的时候,需要用这个时间和执行flush命令的时间相比较,来判断是否失效 11 rel_time_t time; /* least recent access */ 12 //缓存的过期时间。设置为0的时候,则永久有效。 13 //如果Memcached不能分配新的item的时候,设置为0的item也有可能被LRU淘汰 14 rel_time_t exptime; /* expire time */ 15 //value数据大小 16 int nbytes; /* size of data */ 17 //引用的次数。通过这个引用的次数,可以判断item是否被其它的线程在操作中。 18 //也可以通过refcount来判断当前的item是否可以被删除,只有refcount -1 = 0的时候才能被删除 19 unsigned short refcount; 20 uint8_t nsuffix; /* length of flags-and-length string */ 21 uint8_t it_flags; /* ITEM_* above */ 22 //slabs_class的ID。 23 uint8_t slabs_clsid;/* which slab class we're in */ 24 uint8_t nkey; /* key length, w/terminating null and padding */ 25 /* this odd type prevents type-punning issues when we do 26 * the little shuffle to save space when not using CAS. */ 27 //数据存储结构 28 union { 29 uint64_t cas; 30 char end; 31 } data[]; 32 } item;
说明:
- Memcached上存储的每一个元素都会有一个Item的结构。
- tem结构主要记录与HashTable之间的关系,以及存储数据的slabs_class的关系以及key的信息,存储的数据和长度等基本信息。
- Item块会被分配在slabclass上。
- HashTable的主要作用是:用于通过key快速查询缓存数据。
HashTable结构图
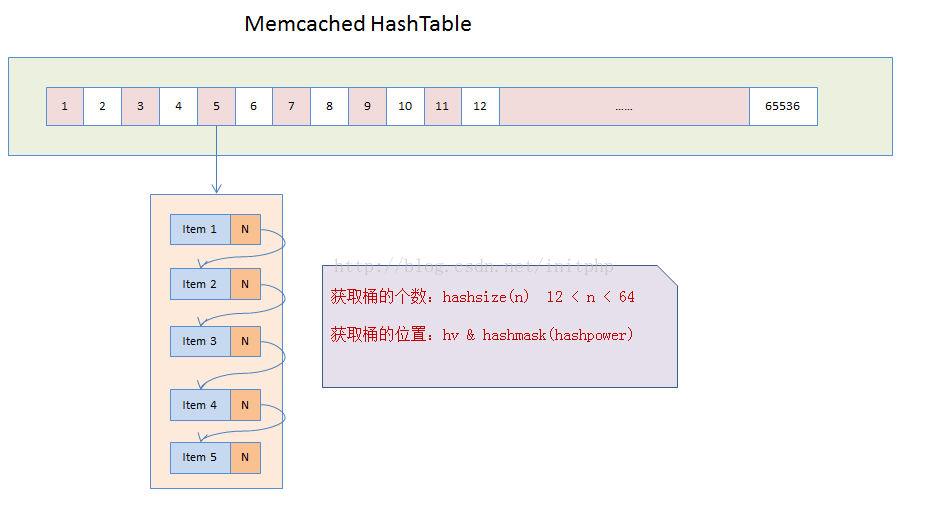
说明:
- Memcached在启动的时候,会默认初始化一个HashTable,这个table的默认长度为65536。
- 我们将这个HashTable中的每一个元素称为桶,每个桶就是一个item结构的单向链表。
- Memcached会将key值hash成一个变量名称为hv的uint32_t类型的值。
- 通过hv与桶的个数之间的按位与计算,hv & hashmask(hashpower),就可以得到当前的key会落在哪个桶上面。
- 然后会将item挂到这个桶的链表上面。链表主要是通过item结构中的h_next实现。
初始化HashTable
HashTable默认设置为16,1 << 16后得到65536个桶。如果用户自定义设置,设置值在12-64之间。
1 //初始化HahsTable表 2 void assoc_init(const int hashtable_init) { 3 //初始化的时候 hashtable_init值需要大于12 小于64 4 //如果hashtable_init的值没有设定,则hashpower使用默认值为16 5 if (hashtable_init) { 6 hashpower = hashtable_init; 7 } 8 //primary_hashtable主要用来存储这个HashTable 9 //hashsize方法是求桶的个数,默认如果hashpower=16的话,桶的个数为:65536 10 primary_hashtable = calloc(hashsize(hashpower), sizeof(void *)); 11 if (! primary_hashtable) { 12 fprintf(stderr, "Failed to init hashtable. "); 13 exit(EXIT_FAILURE); 14 } 15 STATS_LOCK(); 16 stats.hash_power_level = hashpower; 17 stats.hash_bytes = hashsize(hashpower) * sizeof(void *); 18 STATS_UNLOCK(); 19 }
查找
hash 查找的逻辑是优先使用hash 预算定位到bucket,然后循环bucket 链表找到指定的key。需要理解的地方在于查找时可能存在hashtable 正在进行扩展,所以需要确定是在old_hashtable还是primary_hashtable 进行查找
1 //寻找一个Item 2 item *assoc_find(const char *key, const size_t nkey, const uint32_t hv) { 3 item *it; 4 unsigned int oldbucket; 5 6 //判断是否在扩容中... 7 if (expanding && 8 (oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket) 9 { 10 it = old_hashtable[oldbucket]; 11 } else { 12 //获取得到具体的桶的地址 13 it = primary_hashtable[hv & hashmask(hashpower)]; 14 } 15 16 item *ret = NULL; 17 int depth = 0; //循环的深度 18 while (it) { 19 //循环查找桶的list中的Item 20 if ((nkey == it->nkey) && (memcmp(key, ITEM_key(it), nkey) == 0)) { 21 ret = it; 22 break; 23 } 24 it = it->h_next; 25 ++depth; 26 } 27 MEMCACHED_ASSOC_FIND(key, nkey, depth); 28 return ret; 29 }
插入
插入的主要逻辑是找到指定桶的位置,将当前插入的节点设置为桶中位置的链表头结点位置,并且重新设置桶中元素的value。插入时,会判断是否需要扩容,如果扩容,则会在单独的线程中进行。(桶的个数(默认:65536) * 3) / 2。
1 //新增Item操作 2 int assoc_insert(item *it, const uint32_t hv) { 3 unsigned int oldbucket; 4 5 assert(assoc_find(ITEM_key(it), it->nkey) == 0); /* shouldn't have duplicately named things defined */ 6 7 //判断是否在扩容,如果是扩容中,为保证程序继续可用,则需要使用旧的桶 8 if (expanding && 9 (oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket) 10 { 11 it->h_next = old_hashtable[oldbucket]; 12 old_hashtable[oldbucket] = it; 13 } else { 14 //hv & hashmask(hashpower) 按位与计算是在哪个桶上面 15 //将当前的item->h_next 指向桶中首个Item的位置 16 it->h_next = primary_hashtable[hv & hashmask(hashpower)]; 17 //然后将hashtable中的首页Item指向新的Item地址值 18 primary_hashtable[hv & hashmask(hashpower)] = it; 19 } 20 21 hash_items++; //因为是新增操作,则就会增加一个Item 22 //如果hash_items的个数大于当前 (桶的个数(默认:65536) * 3) / 2的时候,就需要重新扩容 23 //因为初始化的桶本身就比较多了,所以扩容必须在单独的线程中处理,每次扩容估计耗时比较长 24 if (! expanding && hash_items > (hashsize(hashpower) * 3) / 2) { 25 assoc_start_expand(); 26 } 27 28 MEMCACHED_ASSOC_INSERT(ITEM_key(it), it->nkey, hash_items); 29 return 1; 30 }
删除
删除接口的主要逻辑是使用_hashitem_before 函数找到要删除item前一个item指针位置,然后将此指针的位置直接指向被删除item 的下一个item 位置。
1 //该方法主要用于寻找 2 static item** _hashitem_before (const char *key, const size_t nkey, const uint32_t hv) { 3 item **pos; 4 unsigned int oldbucket; 5 6 //判断是否在扩容中 7 if (expanding && 8 (oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket) 9 { 10 pos = &old_hashtable[oldbucket]; 11 } else { 12 //返回具体桶的地址 13 pos = &primary_hashtable[hv & hashmask(hashpower)]; 14 } 15 16 //在桶的list中匹配key值是否相同,相同则找到Item 17 while (*pos && ((nkey != (*pos)->nkey) || memcmp(key, ITEM_key(*pos), nkey))) { 18 pos = &(*pos)->h_next; 19 } 20 return pos; 21 } 22 //删除一个桶上的Item 23 void assoc_delete(const char *key, const size_t nkey, const uint32_t hv) { 24 item **before = _hashitem_before(key, nkey, hv); //查询Item是否存在 25 26 //如果Item存在,则当前的Item值指向下一个Item的指针地址 27 if (*before) { 28 item *nxt; 29 hash_items--; //item个数减去1 30 /* The DTrace probe cannot be triggered as the last instruction 31 * due to possible tail-optimization by the compiler 32 */ 33 MEMCACHED_ASSOC_DELETE(key, nkey, hash_items); 34 nxt = (*before)->h_next; 35 (*before)->h_next = 0; /* probably pointless, but whatever. */ 36 *before = nxt; 37 return; 38 } 39 /* Note: we never actually get here. the callers don't delete things 40 they can't find. */ 41 assert(*before != 0); 42 }
_hashitem_before
函数的作用是查找给定item的前一个节点的指针,在delete 接口中调用。
1 static item** _hashitem_before (const char *key, const size_t nkey, const uint32_t hv) { 2 item **pos; 3 unsigned int oldbucket; 4 // 同理是确定是在old_hashtable 还是在primary_hashtable 5 if (expanding && 6 (oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket) 7 { 8 pos = &old_hashtable[oldbucket]; 9 } else { 10 pos = &primary_hashtable[hv & hashmask(hashpower)]; 11 } 12 // 从头结点的位置开始顺序遍历单链表中的节点 13 while (*pos && ((nkey != (*pos)->nkey) || memcmp(key, ITEM_key(*pos), nkey))) { 14 pos = &(*pos)->h_next; 15 } 16 return pos; 17 }
assoc_expand
函数的作用是执行hash表的扩容,执行的过程是将当前primary_hashtable 指定为old_hashtable, 为primary_hashtable 分配内存,primary_hashtable的大小是old_hashtable 的两倍,将标识是否在扩展的bool型变量 expanding 设置为true。将标识扩展进度的变量expand_bucket 设置为0。
1 /* grows the hashtable to the next power of 2. */ 2 static void assoc_expand(void) { 3 old_hashtable = primary_hashtable; 4 5 primary_hashtable = calloc(hashsize(hashpower + 1), sizeof(void *)); 6 if (primary_hashtable) { 7 if (settings.verbose > 1) 8 fprintf(stderr, "Hash table expansion starting "); 9 hashpower++; 10 expanding = true; 11 expand_bucket = 0; 12 STATS_LOCK(); 13 stats_state.hash_power_level = hashpower; 14 stats_state.hash_bytes += hashsize(hashpower) * sizeof(void *); 15 stats_state.hash_is_expanding = true; 16 STATS_UNLOCK(); 17 } else { 18 primary_hashtable = old_hashtable; 19 /* Bad news, but we can keep running. */ 20 } 21 }
assoc_start_expand
函数的作用判断是否进行扩展,进行扩展的临界条件是hashtable 中item 个数大于hash 桶数的1.5倍。满足此临界条件时通知扩展线程进行扩展。
1 void assoc_start_expand(uint64_t curr_items) { 2 if (started_expanding) 3 return; 4 5 if (curr_items > (hashsize(hashpower) * 3) / 2 && 6 hashpower < HASHPOWER_MAX) { 7 started_expanding = true; 8 pthread_cond_signal(&maintenance_cond); 9 } 10 }
start_assoc_maintenance_thread
函数的作用是创建hash 扩展线程,可以根据用户指定的参数设置每次扩展多少个bucket。如果不指定此参数的话,默认每次只扩展一个bucket。
1 int start_assoc_maintenance_thread() { 2 int ret; 3 char *env = getenv("MEMCACHED_HASH_BULK_MOVE"); 4 if (env != NULL) { 5 hash_bulk_move = atoi(env); 6 if (hash_bulk_move == 0) { 7 hash_bulk_move = DEFAULT_HASH_BULK_MOVE; 8 } 9 } 10 pthread_mutex_init(&maintenance_lock, NULL); 11 if ((ret = pthread_create(&maintenance_tid, NULL, 12 assoc_maintenance_thread, NULL)) != 0) { 13 fprintf(stderr, "Can't create thread: %s ", strerror(ret)); 14 return -1; 15 } 16 return 0; 17 }
assoc_maintenance_thread
函数的作用是执行实际的bucket 扩展。具体解释见注释。
1 static void *assoc_maintenance_thread(void *arg) { 2 3 mutex_lock(&maintenance_lock); 4 while (do_run_maintenance_thread) { 5 int ii = 0; 6 7 /* There is only one expansion thread, so no need to global lock. */ 8 // 循环每次扩展的全部bucket 9 for (ii = 0; ii < hash_bulk_move && expanding; ++ii) { 10 item *it, *next; 11 unsigned int bucket; 12 void *item_lock = NULL; 13 14 /* bucket = hv & hashmask(hashpower) =>the bucket of hash table 15 * is the lowest N bits of the hv, and the bucket of item_locks is 16 * also the lowest M bits of hv, and N is greater than M. 17 * So we can process expanding with only one item_lock. cool! 18 */ 19 /* expand_bucket需要锁保护,由于处于同一个bucket 中的特性是 20 这些item 的hv 的低N位是完全相同,对应的item_lock 的位置靠hv 21 的低M位确定,由于item_lock数组大小小于桶数组的大小,所以有 M < N , 22 也就是说处于同一个桶中的item拥有相同item_lock,所以在遍历桶中 23 所有的item 的时候不需要在额外获取item_lock。这里的设计非常精妙~*/ 24 if ((item_lock = item_trylock(expand_bucket))) { 25 // 遍历bucket 中全部item,插入到primary_hashtable 中相应bucket 26 for (it = old_hashtable[expand_bucket]; NULL != it; it = next) { 27 next = it->h_next; 28 bucket = hash(ITEM_key(it), it->nkey) & hashmask(hashpower); 29 it->h_next = primary_hashtable[bucket]; 30 primary_hashtable[bucket] = it; 31 } 32 // old_hashtable 中bucket 内容设置为空 33 old_hashtable[expand_bucket] = NULL; 34 // 维护当前扩展的进度 35 expand_bucket++; 36 /* 如果扩展已经全部完成则设置expanding为false, 37 释放old_hashtable 的内存*/ 38 if (expand_bucket == hashsize(hashpower - 1)) { 39 expanding = false; 40 free(old_hashtable); 41 STATS_LOCK(); 42 stats_state.hash_bytes -= hashsize(hashpower - 1) * sizeof(void *); 43 stats_state.hash_is_expanding = false; 44 STATS_UNLOCK(); 45 if (settings.verbose > 1) 46 fprintf(stderr, "Hash table expansion done "); 47 } 48 49 } else { 50 usleep(10*1000); 51 } 52 // 释放资源 53 if (item_lock) { 54 item_trylock_unlock(item_lock); 55 item_lock = NULL; 56 } 57 } 58 // 如果不在进行扩展,则设置条件变量,等待被触发扩展 59 if (!expanding) { 60 /* We are done expanding.. just wait for next invocation */ 61 started_expanding = false; 62 pthread_cond_wait(&maintenance_cond, &maintenance_lock); 63 /* assoc_expand() swaps out the hash table entirely, so we need 64 * all threads to not hold any references related to the hash 65 * table while this happens. 66 * This is instead of a more complex, possibly slower algorithm to 67 * allow dynamic hash table expansion without causing significant 68 * wait times. 69 */ 70 pause_threads(PAUSE_ALL_THREADS); 71 assoc_expand(); 72 pause_threads(RESUME_ALL_THREADS); 73 } 74 } 75 return NULL; 76 }
线程安全
memcached 使用分段锁实现hashtable 线程安全,分段锁避免了hashtable 中全部的item公用一个锁,公用一个锁的会降低hashtable 的读写性能。下面部分代码是memcached 初始化分段锁数组的逻辑。
if (nthreads < 3) { power = 10; } else if (nthreads < 4) { power = 11; } else if (nthreads < 5) { power = 12; } else if (nthreads <= 10) { power = 13; } else if (nthreads <= 20) { power = 14; } else { /* 32k buckets. just under the hashpower default. */ power = 15; } /* 保证分段锁的数目小于hashtable 桶的个数,这样设计的好处之一是在扩展 的时候针对一个桶中的所有item 对应的是同一个item_lock*/ if (power >= hashpower) { fprintf(stderr, "Hash table power size (%d) cannot be equal to or less than item lock table (%d) ", hashpower, power); fprintf(stderr, "Item lock table grows with `-t N` (worker threadcount) "); fprintf(stderr, "Hash table grows with `-o hashpower=N` "); exit(1); } item_lock_count = hashsize(power); item_lock_hashpower = power; // 分配分段锁数组 item_locks = calloc(item_lock_count, sizeof(pthread_mutex_t)); if (! item_locks) { perror("Can't allocate item locks"); exit(1); }
在对hashtable 进行多线程读写时,首先需要根据hash 算法计算出hv 值,然后根据hv 获取item_lock,获取到item_lock 之后再进行读写操作。这也从侧面解释了为什么memcached在扩展时默认每次只扩展一个bucket,因为在进行扩展的时候需要占有item_lock,每次执行扩展的bucket 数多会影响读写性能。
总结
memcached 的hashtable是典型的拉链式hashtable,实现代码短小易读,使用一个线程进行hashtable的扩展以保证不会出现item增多导致哈希冲突激增降低读写性能的现象,除此之外使用分段锁来保证多线程的读写安全,相比全局锁也可以提升读写性能。memcached hashsize设置为2的整数次幂的设计非常精妙,首先这样可以将查找hash bucket索引的取余操作转化为对(hashsize-1)取按位与操作,在加上分段锁的数目大小小于hashsize 的设置可以保证一个bucket 中所有的item 对应于同一个分段锁,进而保证在扩展bucket中全部内容时只需要获取一次分段锁!