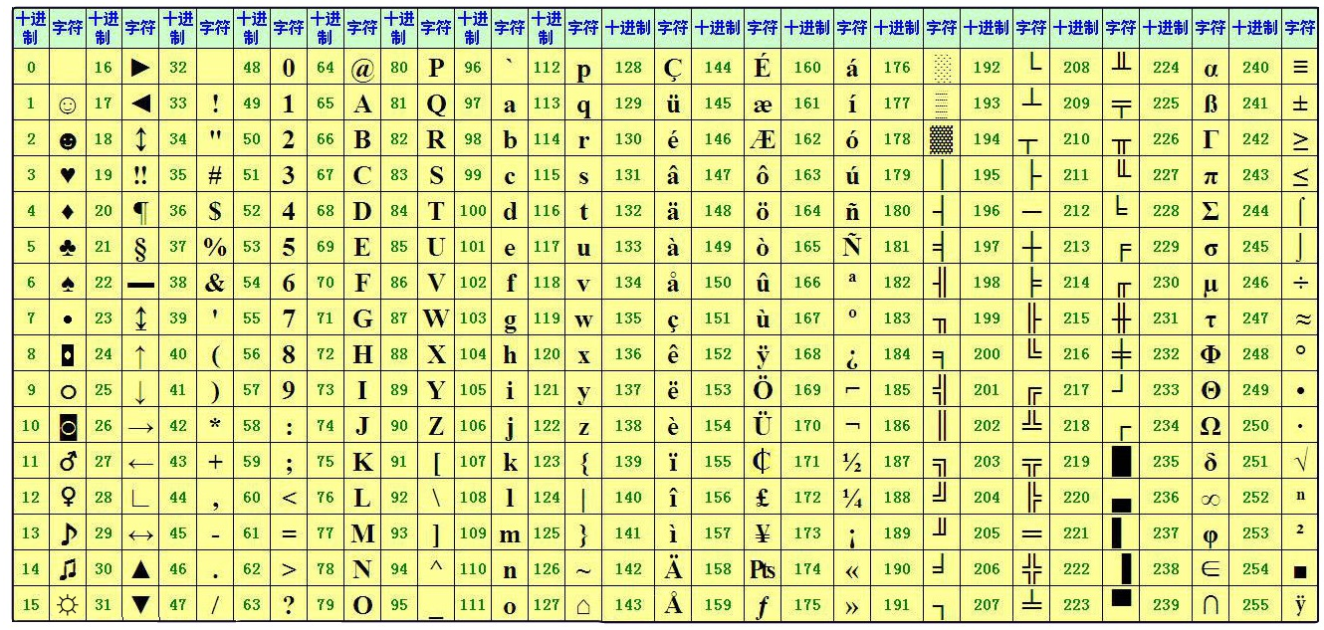
【视频观看速率为 1.0x-1.5x】
【学习疑问:暂未找到更高效、合理的学习方法,学习效率低下,继续探索吧
1、待优化:每日学习时间(分配不足),执行力(执行不足易分心),打卡(跳票有些严重)。
2、关于笔记整理:在luffy-book上,已经有非常详细的记录了,感觉在博客上的再次整理笔记,仅仅起到了一次回顾内容的作用?(建议:跟导师、班级群里,都沟通交流一下学习心得。)
3、关于笔记整理:后边考虑通过Xmind思维导图,来详细整理汇总知识点,用于快速检索记忆。】
2.3、细讲数据类型-列表
2.3.1、列表的增加操作:
追加,appent() ,数据会追加到尾部

插入,insert() ,可插入任何位置

合并 ,extend() ,可以把另一个列表的值合并进来.

列表嵌套,列表里边可以嵌套列表

2.3.2、列表的删除操作:
del 直接删,可以删除列表元素,也可以删除列表。 del names[3] 或 del names

pop 删,删除元素、并把删除的值作为返回值。pop()

clear 清空,clear()

2.3.3、列表的修改操作:

2.3.4、列表的查询操作:index()、count()

2.3.5、切片

*切片的特性是顾头不顾尾,即start的元素会被包含,end-1是实际取出来的值
倒着切:

步长,允许跳着取值

列表反转:a[::-1]

2.3.6、排序 和 反转
排序:sort()


反转:reverse()

2.3.7、循环列表

2.4、细讲数据类型-元组
定义:与列表类似,只不过[]改成()
特性:
1.可存放多个值
2.不可变
3._按照从左到右的顺序定义元组元素,下标从0开始顺序访问,有序
创建
ages = (11, 22, 33, 44, 55)
#或
ages = tuple((11, 22, 33, 44, 55))常用操作
#索引
>>> ages = (11, 22, 33, 44, 55)
>>> ages[0]
11
>>> ages[3]
44
>>> ages[-1]
55
#切片:同list
#循环
>>> for age in ages:
print(age)
11
22
33
44
55
#长度
>>> len(ages)
5
#包含
>>> 11 in ages
True
>>> 66 in ages
False
>>> 11 not in ages
False
注意:元组本身不可变,如果元组中还包含其他可变元素,这些可变元素可以改变。
>>> data
(99, 88, 77, ['Alex', 'Jack'], 33)
>>> data[3][0] = '金角大王'
>>> data
(99, 88, 77, ['金角大王', 'Jack'], 33)
2.5、细讲数据类型-字符串
字符串的常用操作:

# # 字符串前边加r(raw,原生字符),表示转义,与前边再加上\转义是类似的
# name = "lizhen 111"
# print(name)
# name = r"lizhen 111"
# print(name)
# format的使用,字符串格式化,官方推荐使用
# show_me = "Hello , my name is {0} , i am {1} years old."
# print(show_me.format("lizhen" , 30))
# isdigit() ,判读是否为整数,负数不是整数,-号会被认为是特殊字符
# print(name.isdigit())
# print("123".isdigit())
# print("1.1".isdigit())
# print("-1".isdigit())
# isspace,判断是否为空格
# print(" ".isspace())
# print("11 11".isspace())
关于join,只能拼接字符串。
n = ["李祯", "小强", "黄宁明", "李涛"]
print(id(n))
print(n)
print(id("-".join(n)))
print("-".join(n))
# "-".join() 可以把一个列表中元素,设置特定字符拼接出来
# n = ["李祯", "小强", "黄宁明", "李涛"]
# print(id(n))
# print(n)
# print(id("-".join(n)))
# print("-".join(n))
#
# n2 = "huangningming"
# print("-".join(n2))
#
# n3 = " lizhen "
# # print(n3)
# # print(n3.strip()) # 去除两边的空格和特殊字符
# # print(n3.lstrip()) # 去除左侧的空格和特殊字符
# # print(n3.rstrip()) # 去除右侧的空格和特殊字符
# n4 = "lizhen"
# print(n4)
# print(n4.rjust(25, "*")) # 字符串左侧,打印25个*
# print(n4.ljust(25, "*")) # 字符串右侧,打印25个*
关于字符串内置方法, lower() 与 casefold() ,都可以把字符串,由大写转换为小写。
区别:lower() 只对 ASCII 也就是 'A-Z'有效,但是其它一些语言里面存在小写的情况就没办法了。文档里面举得例子是德语中'ß'的小写是'ss':
建议:汉语 & 英语环境下面,继续用 lower()没问题;要处理其它语言且存在大小写情况的时候再用casefold()
# n5 = "lizhen"
# print(n5.capitalize()) # 首字母大写
n6 = "LiZHen"
print(n6.casefold()) # 大写全部转小写
# print(n6.swapcase()) # 大写变小写,小写变大写
print(n6)
name = "LiZhen"
print(id(name))
# print(id(name.lower()))
# print(id(name.upper()))
print(name.lower())
# print(name.upper())
print(name)
# n7 = "Welcome to beijing"
# print(n7.endswith("ing")) # endswith , 判断以什么为结尾
# print(n7.endswith("ong"))
# print(n7.startswith("Wel")) # startswith , 判断以什么为开头
# print(n7.startswith("wel"))
# print(n7.count("o"))
# print(n7.find("to"))
# print(n7.replace("o", "OOO", 1))
# print(n7.split())
#
# n8 = "Welcom,e t, obeijing"
# print(n8.split(","))
# print(n8.split(",", 1))
2.6、细讲数据类型-字典
# ##### 创建
# print(list([1,2,3]))
# print(dict(name="lizhen", age=18))
# person = {"name": "牛魔王", "age": 18} # 方式1
# person = dict(name="牛魔王" , age=18) # 方式2
# person = dict({"name": "牛魔王", "age": 18}) # 方式3,该方式不常用
# print(person)
# key = ["李祯", "小明", "小强"]
# dict_piliang = {}.fromkeys(key, 18) # 方式4,批量生成value值
# print(dict_piliang)
# ##### 增
# person = {"name": "李祯", "age": 18}
# print(type(person))
# print(person)
#
# person["job"] = "teacher"
# print(person)
#
# person["name"]= "牛魔王"
# print(person)
#
# person["salary"] = [1000,2000,3000] # 新增的时候,已经有了这个key,则会修改。没有key则新增。
# print(person)
#
# person.setdefault("salary",[1000,2000,3000,6666]) # setdefault,在新增的时候,如果发现已经有这个key,就不会再新增了。
# print(person)
#
# person.setdefault("haveFriendGirl", ["大老婆", "小老婆", "小情人"])
# print(person)
# ##### 删
# person = {'name': '牛魔王', 'age': 18, 'job': 'teacher','haveFriendGirl': ['大老婆', '小老婆', '小情人'],
# 'salary': [1000, 2000, 3000]}
# del person["salary"]
# print(person)
# del person # 直接删除该字典,再打印字典就会报错了。
# print(person)
# print(person.pop("job")) # 删除指定键,并且返回改键的值
# print(person)
# print(person.popitem()) # 随机删除一个键值,但是我测试没有随机删、一直删最后一对键值?数据量太小了?
# print(person)
#
# person.clear() # 清空
# print(person)
# ##### 改
# person = {'name': 'Jack Li', 'age': 18}
# person2 = {'age': 30, "salary": [111,222,333]}
# print(person)
# print(person2)
#
# person.update(person2) # 2个字典合并,并且更新
# print(person)
# ##### 查
# person = {'name': 'Jack Li', 'age': 18}
# # person2 = {'age': 30, "salary": [111,222,333]}
# # print(person["name"])
# # print(person["name2"]) # 如果字典中不存在这个键值,则会报错
# print(person.get("name"))
# print(person.get("name2"))
# print("name" in person)
# print("name2" in person)
# print(person.keys())
# print(person.values())
# print(person.items())
# ##### 循环
# # 1、for k in dic.keys()
# person = {'name': '牛魔王', 'age': 18, 'job': 'teacher'}
# for i1 in person.keys():
# print(i1)
# # 2、for k,v in dic.items()
# person = {'name': '牛魔王', 'age': 18, 'job': 'teacher'}
# print(person.items())
#
# for i in person.items():
# print(i)
#
# for k,v in person.items():
# print(k,v)
# # 3、for k in dic # 推荐用这种,效率速度最快
# person = {'name': '牛魔王', 'age': 18, 'job': 'teacher'}
# for i in person: # 官方推荐,效率最高的一种循环
# # print("键为{0},值为{1}.".format(i, person[i]))
# print(i,person[i])
# # 求长度
# person = {'name': '牛魔王', 'age': 18, 'job': 'teacher'}
# print(len(person)) # len() ,通用方法
2.7、细讲数据类型-集合

# # 学python的用户
# python_users = [1,2,3,6,8]
# # 学前端web的用户
# web_users = [2,4,6,10,15]
#
# #取出既学python、又学前端web的用户
# both_users = []
#
# for i in python_users:
# if i in web_users:
# both_users.append(i)
#
# # 打印
# print(both_users)
# 集合:主要做两件事,去重和关系运算
# test = [1, 2, 3, 6, 8, 2, 4, 6, 10, 15]
# print(test)
# test1 = set(test) #set()是集合的语法
# print(test1)
# print(type(test1))
#
# # 增
# test1.add("66")
# print(test1)
#
# test1.add(2)
# print(test1)
# 删
# test1.discard(10) # 删除值
# test1.discard(10) # 没有值时,也不会报错
# print(test1)
# test1.pop() # 随机删
# print(test1)
# test1.remove(8)
# print(test1)
# 查
# print(2 in test1)
# 改,呵呵,不能改。
# #关系运算
s_1024 = {"黄宁明", "老男孩", "李祯", "牛魔王", "李涛", "熊星宇", "Jack"}
s_pornhub = {"牛魔王", "Alex", "小明", "李祯", "Jack", "刘德华"}
print("喜欢看{0}的人:{1}".format("1024社区", s_1024))
print("喜欢看{0}的人:{1}".format("pornhub社区", s_pornhub))
# 交集 &, elements in both set
# print(s_1024 & s_pornhub)
# 并集 | 合集
# print(s_1024 | s_pornhub)
# 差集 -, only in 1024
# print(s_1024 - s_pornhub)
# 差集 -, only in pornhub
# print(s_pornhub - s_1024)
# 对称差集 ^,把脚踩2只船的人T出去
# print(s_1024 ^ s_pornhub)
# 两个集合之间一般有3种关系,相交、包含、不相交。在Python中分别用下面的方法判断:
print(s_1024.isdisjoint(s_pornhub)) # 判断2个集合是不是相交,返回True 或 False
print(s_1024.issubset(s_pornhub)) # 判断s_1024是不是s_pornhub的子集,返回True 或 False
print(s_1024.issuperset(s_pornhub)) # 判断s_1024是不是s_pornhub的父集,返回True 或 False
print({1,2,3}.issubset({1,2,3,4,5}))
print({1,2,3,4,5}.issuperset({1,2,3}))
2.8、二进制
长城,狼烟,0-1(开关,是否点燃),人数。
比如第1根烟,就让它代表1。点着了就是1,没点就是0。
比如第2根烟,就让它代表2。点着了就是2。
比如第3根烟,就让它代表4。点着了就是4。

规律:(从右[前]往左[后])
1、后面每根烟的值=前面所有烟的值相加+1
2、例如:8根烟,能表示的数字,就是2**8【2的8次方】
3、逢2进1。
规则:
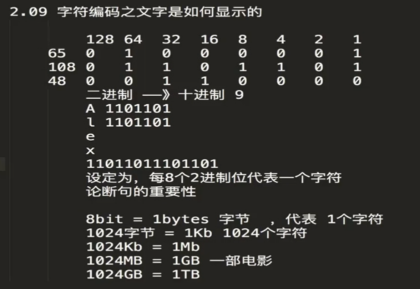
1、论断句的重要性,8个二进制数字,代表一个字符(ASCII表中、最大字符也就255)。
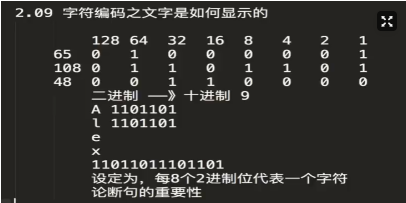
2.9、字符编码
ASCII字符编码表
bit(比特),计算机中最小的表示单位。
8bits=1bytes(代表1个字符),bytes是计算机中最小的存储单位。


py2 vs py3
py3全面支持unicode,py2不支持、所以无法写中文。
py文件首行写上
方法1# coding:utf-8 即可设定好编码。 【导师推荐写法】
方法2# -*- encoding:utf-8 -*- 【官方推荐写法】




# # 十六进制转十进制,公式:
# # 1000 = 1x16^3(16的3次方)+ 0x16^2(16的2次方)+ 0x16^1(16的1次方)+ 0x1(16的0次方)
# shijinzhi_num = 1*16**3 + 0*16**2 + 0*16**1 + 0*16**0
# print(shijinzhi_num)
# shiliu_num = hex(shijinzhi_num)
# print(shiliu_num)
#
# # 计算十六进制转为十进制 FC45
# num_FC45 = 15*16**3 + 12*16**2 + 4*16**1 + 5*16**0
# print(num_FC45)
# print(hex(64581))
# 十进制转十六进制
num23612_convert16 = []
print(23612//16)
print(23612%16) # c
print(1475//16)
print(1475%16) # 3
print(92//16)
print(92%16) # c
print(5//16)
print(5%16) # 5
print("5c3c")
print(hex(23612))
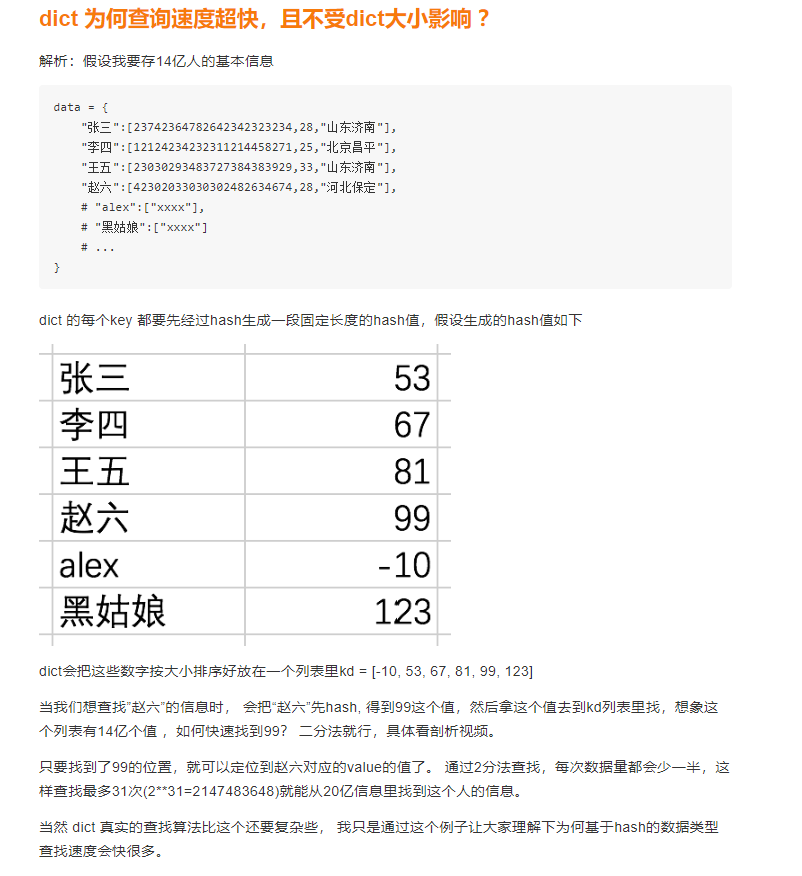
2.10、HASH
 、
、
print(hash("我爱你"))
print(hash("我爱你"))
print(hash("我爱你"))


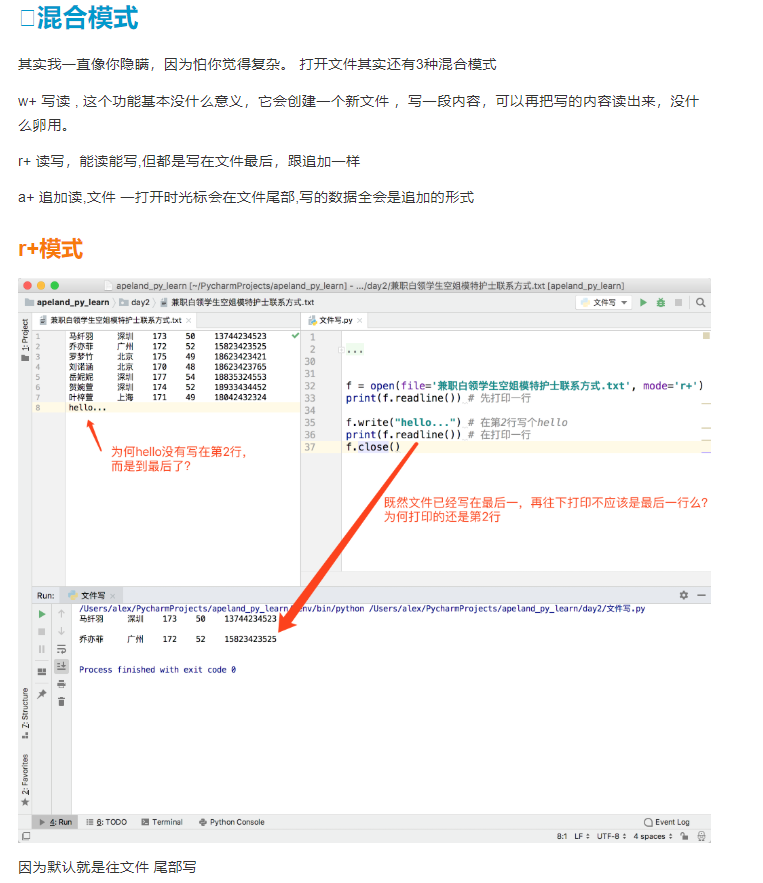
2.11、用Python操作文件




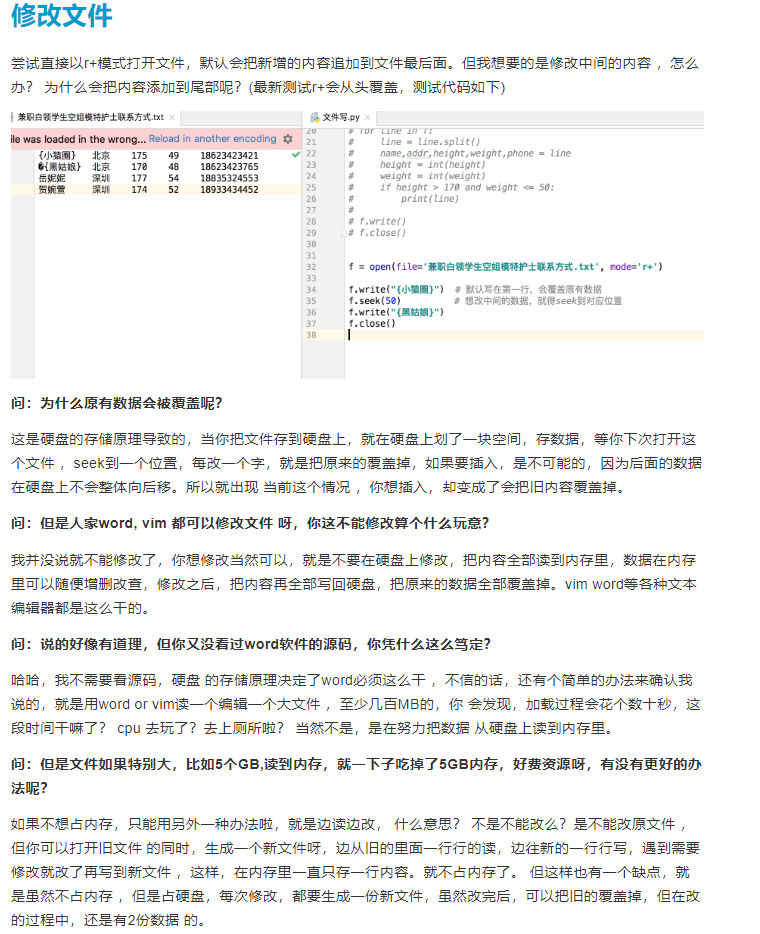

# 文件操作代码练习:
全局操作文件: https://www.cnblogs.com/lizhen416/p/13592303.html
模拟登录: https://www.cnblogs.com/lizhen416/p/13610613.html