RC,RS方便运行无状态的pod实例,但是怎么方便来运行一些有状态实例?
1.复制有状态pod
ReplicaSet通过一个pod模板创建多个pod副本。这些副本除了它们的名字和IP地址不同外,没有别的差异。如果pod模板里描述了一个关联到特定持久卷声明的数据卷,那么ReplicaSet的所有副本都将共享这个持久卷声明,也就是绑定到同持久卷声明,也就是绑到同一个声明的持久卷(如下图10.1所示)
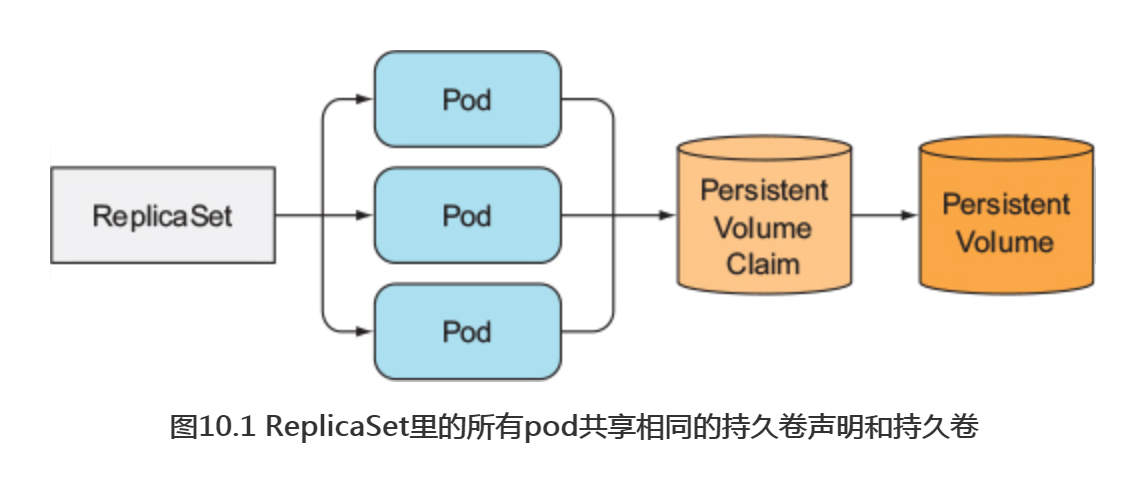
因为是在pod模板里关联声明的,又会依据pod模板创建多个pod副本,则不能对每个副本都指定独立的持久卷声明。所以也不能通过一个ReplicaSet来运行一个每个实例都需要独立存储的分布式数据存储服务,至少通过单个ReplicaSet是做不到的。起码很多API对象都不能提供这样的数据存储服务,还需要其他的对象。
1.1 运行每个实例都有单独存储的多副本
那如何运行一个pod的多个副本,让每个pod都有独立的存储卷呢?ReplicaSet会依据一个pod创建一致的副本,所以不能通过它们来达到目的,那你可以使用什么呢?
手动创建pod
可以手动创建多个pod,每个pod使用一个独立的持久卷声明,但是因为没有一个ReplicaSet在后面对应它们,所以需要手动管理它们。当有的pod消失后(比如节点故障),需要手动创建它们。因此这不是一个好的选择。
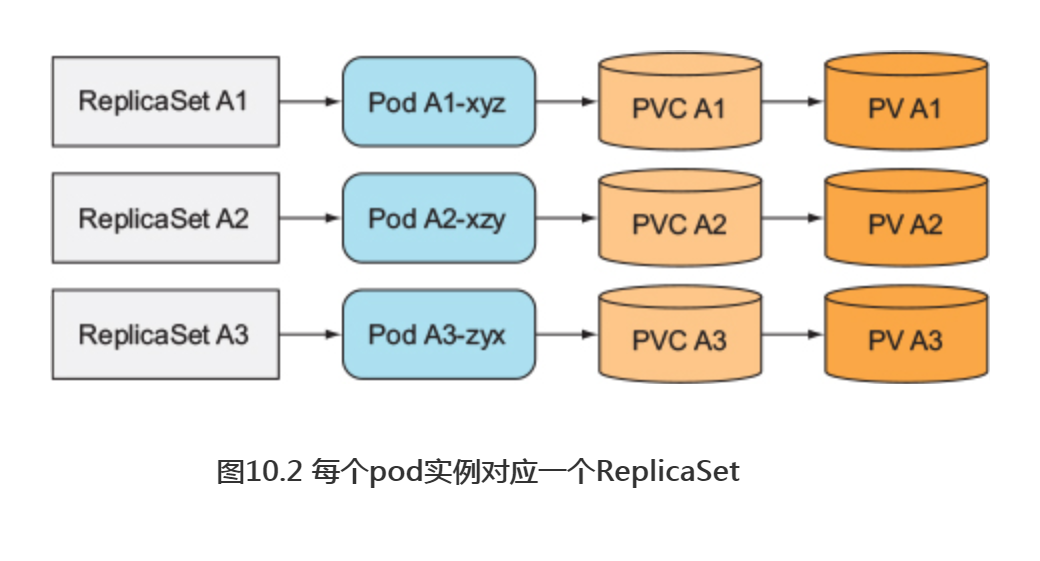
一个pod实例对应一个ReplicaSet
与直接创建不同,可以创建多个ReplicaSet,每个ReplicaSet的副本数设为1, 做到pod和ReplicaSet的一一对应,为每个ReplicaSet的pod模板关联一个专属的持久卷声明(如图10.2所示)。
尽管这种方法能保证在节点故障或者pod误删时能自动重新调度创建,但是与单个ReplicaSet相比,它还是显得比较笨重的。例如,在这种情况下要如何伸缩pod?扩容的话,必须重新创建新的ReplicaSet。
所以说使用多个ReplicaSet也不是最好的方案。 那是否可以创建一个ReplicaSet, 即使在共享一个存储卷的情况下,让每个pod实例都独立保持自己的持久化状态呢?
使用同一数据卷中的不同目录
一个比较取巧的做法是:所有pod共享同一数据卷, 但是每个pod在数据卷中使用不同的数据目录(如图10.3所示)。
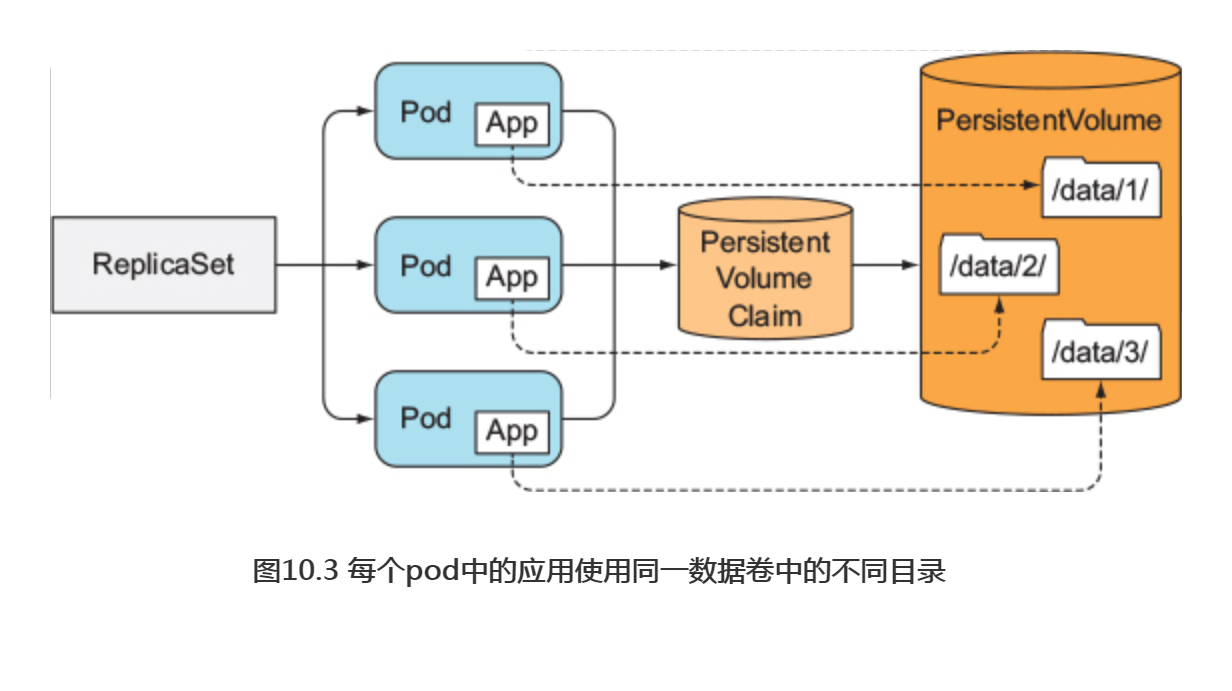
因为不能在一个pod模板中差异化配置pod副本,所以不能指定一个实例使用哪个特定目录!但是可以让每个实例自动选择(或创建)一个别的实例还没有使用的数据目录。 这种方案要求实例之间相互协作, 其正确性很难保证, 同时共享存储也会成为整个应用的性能瓶颈。
1.2 每个pod都提供稳定的标识
除了上面说的存储需求,集群应用也会要求每一个实例拥有生命周期内唯一标识。pod可以随时被删掉,然后被新的pod替代。当一个ReplicaSet中的pod被替换时,尽管新的pod也可能使用被删掉pod数据卷中的数据,但它却是拥有全新主机名和IP的崭新pod。 在一些应用中, 当启动的实例拥有完全新的网络标识, 但还使用旧实例的数据时, 很可能引起问题。
为什么一些应用需要维护一个稳定的网络标识呢?这个需求在有状态的分布式应用中很普遍。 这类应用要求管理者在每个集群成员的配置文件中列出所有其他集群成员和它们的IP地址(或主机名)。 但是在Kubernetes中, 每次重新调度一个pod, 这个新的pod就有一个新的主机名和IP地址, 这样就要求当集群中任何一个成员被重新调度后, 整个应用集群都需要重新配置。
每个pod 实例配置单独的 Service
一个比较取巧的做法是:针对集群中的每个成员实例, 都创建一个独立的KubernetesService来提供稳定的网络地址。因为服务IP是固定的,可以在配置文件中指定集群成员对应的服务IP(而不是podIP)。
这种做法跟之前提到的一 种方法类似:为每个成员创建一个ReplicaSet, 并配置独立存储。 把这两种方法结合起来就构成如图10.4所示的结构(额外添加一个访问集群所有成员的服务,因为需要它来服务集群中的客户端)。
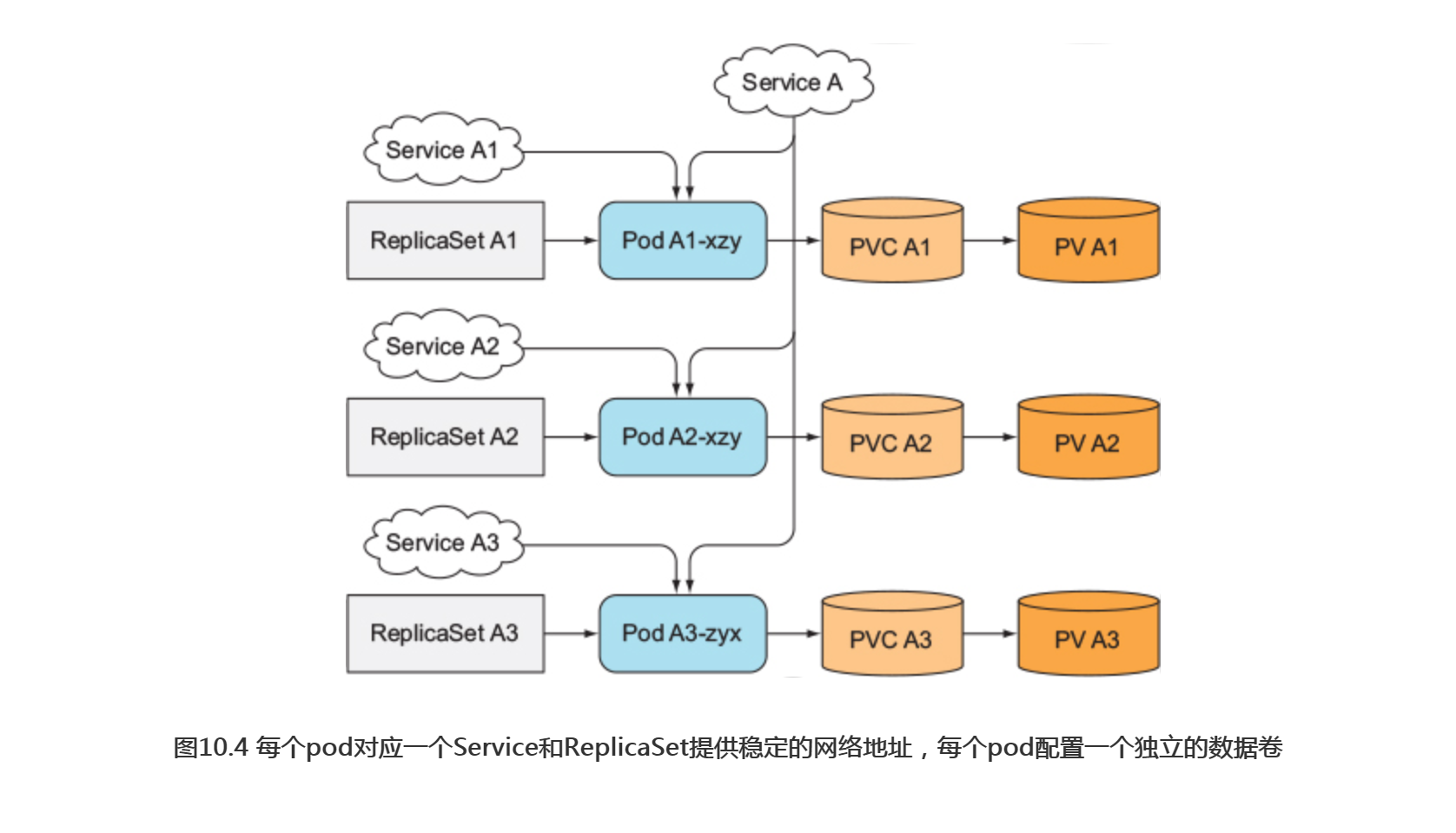
这种解决方案不仅令人厌恶, 而且它也不是一个完美的解决办法。 每个单独的pod没法知道它对应的Service (所以也无法知道对应的稳定IP), 所以它们不能在别的pod里通过服务IP自行注册。
幸运的是, Kubernetes为我们提供了这类需求的完美解决方案。
2.了解Statefulset
可以创建一个Statefulset资源替代ReplicaSet 来运行这类pod。它是专门定制的一类应用,这类应用中每一个实例都是不可替代的个体,都拥有稳定的名字和状态。
2.1 对比 Statefulset和ReplicaSet
要很好地理解Statefulset的用途,最好先与ReplicaSet或ReplicationControllers对比一下。首先拿一个通用的类比来解释它们。
通过宠物与牛的类比来理解有状态
你可能己经听说过宠物与牛的类比。先简单介绍一下。可以把应用看作宠物或牛。
注意:Statefulset最初被称为PetSet,这个名字来源于宠物与牛的类比。
我们倾向于把应用看作宠物,给每个实例起一个名字,细心照顾每个实例。但是也许把它们看成牛更为合适,并不需要对单独的实例有太多关心。这样就可以非常方便地替换掉不健康的实例,就跟农场主替换掉一头生病的牛一样。
对于无状态的应用实例来说,行为非常像农场里的牛。一个实例挂掉后并没什么影响,可以创建一个新实例,而让用户完全无感知。
另一方面,有状态的应用的一个实例更像一个宠物。若一只宠物死掉,不能买到一只完全一样的,而不让用户感知到。若要替换掉这只宠物,需要找到一只行为举止与之完全一致的宠物。对应用来说,意味着新的实例需要拥有跟旧的案例完全一致的状态和标识。
Statefulset与ReplicaSet或ReplicationController的对比
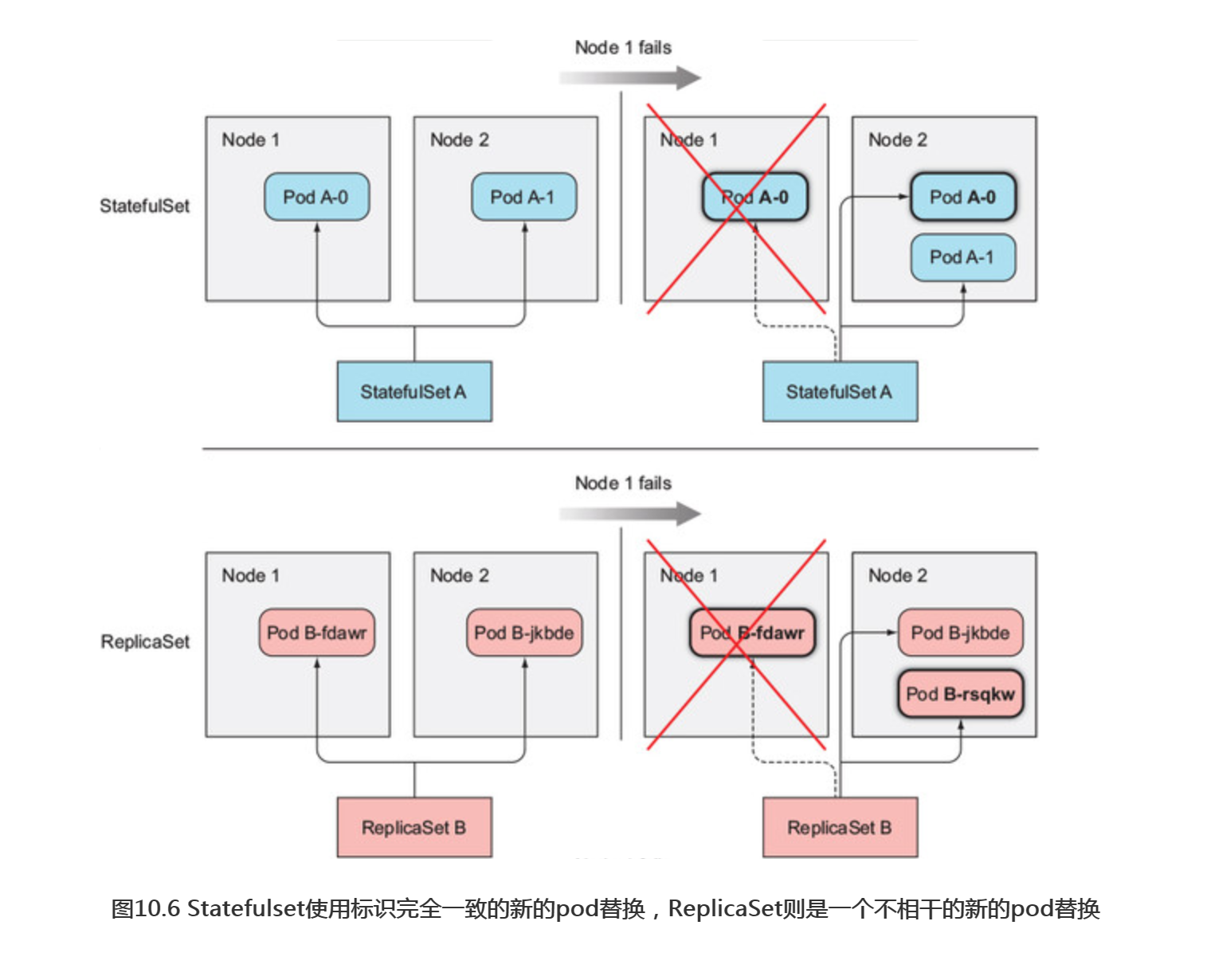
RelicaSet或ReplicationController管理的pod副本比较像牛,这是因为它们都是 无状态的,任何时候它们都可以被一个全新的pod替换。然而有状态的pod需要不同的方法,当一个有状态的pod挂掉后(或者它所在的节点故障),这个pod实例需要在别的节点上重建,但是新的实例必须与被替换的实例拥有相同的名称、网络标识和状态。这就是StatefulSet如何管理pod的。
Statefulset保证了pod在重新调度后保留它们的标识和状态。它让你方便地扩容、缩容。与ReplicaSet类似,Statefulset也会指定期望的副本个数,它决定了在同一时间内运行的宠物的数量。与ReplicaSet类似,pod也是依据Statefulset的pod模板创建的(想象一下曲奇饼干模板)。与ReplicaSet不同的是,Statefuilset创建的pod副本并不是完全一样的。每个pod都可以拥有一组独立的数据卷(持久化状态)而有所区别。另外“宠物”pod的名字都是规律的(固定的),而不是每个新pod都随机获取一个名字。
2.2 提供稳定的网络标识
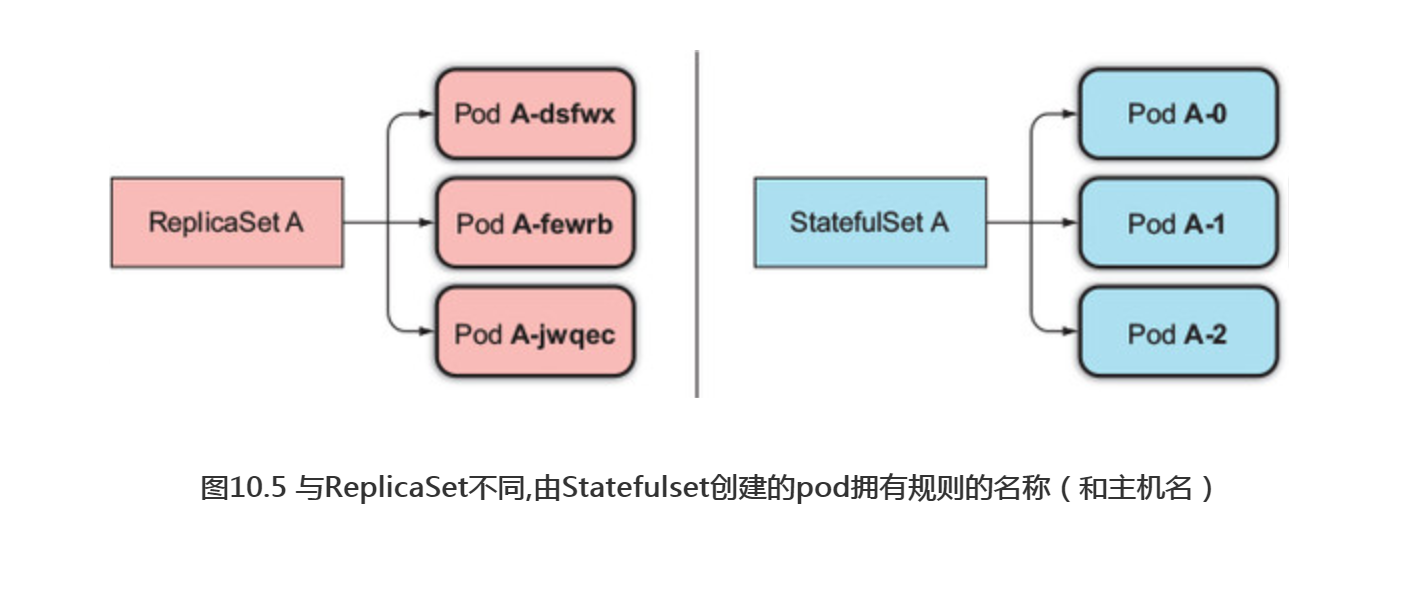
一个Statefulset创建的每个pod都有一个从零开始的顺序索引,这个会体现在pod的名称和主机名上,同样还会体现在pod对应的固定存储上。这些pod的名称则是可预知的,因为它是由Statefolset的名称加该实例的顺序索引值组成的。不同于pod随机生成一个名称,这样有规则的pod名称是很方便管理的,如图10.5所示。
控制服务介绍
让pod拥有可预知的名称和主机名并不是全部,与普通的pod不一样的是,有状态的pod有时候需要通过其主机名来定位,而无状态的pod则不需要,因为每个无状态的pod都是一样的,在需要的时候随便选择一个即可。但对于有状态的pod来说,因为它们都是彼此不同的(比如拥有不同的状态),通常希望操作的是其中特定的一个。
基于以上原因,一个Statefulset通常要求你创建一个用来记录每个pod网络标记的headlessService。通过这个Service,每个pod将拥有独立的DNS记录,这样集群里它的伙伴或者客户端可以通过主机名方便地找到它。比如说,一个属于default命名空间,名为foo的控制服务,它的一个pod名称为A-0,那么可以通过下面的完整域名来访问它:a-0.foo.default.svc.cluster.local。而在ReplicaSet中这样是行不通的。
另外,也可以通过DNS服务,查找域名foo.default.svc.cluster.local对应的所有SRV记录,获取一个Statefulset中所有pod的名称。后面在介绍SRV记录,解释如何通过它来发现一个Statefolset中的所有成员。
替换消失的宠物
当一个Statefulset管理的一个pod实例消失后(pod所在节点发生故障,或有人手动删除pod),Statefulset会保证重启一个新的pod实例替换它,这与ReplicaSet类似。但与ReplicaSet不同的是,新的pod会拥有与之前pod完全一致的名称和主机名(ReplicaSet和Statefulset的差异如图1.6所示。
pod运行在哪个节点上并不重要, 新的pod并不一定会调度到相同的节点上。 对于有状态的pod来说也是这样,即使新的pod被调度到一个不同的节点,也同样可以通过主机名来访问。
扩缩容Statefulset
扩容一个Statefulset会使用下一个还没用到的顺序索引值创建一个新的pod实例。比如,要把一个Statefulset从两个实例扩容到三个实例,那么新实例的索引值就会是2 (现有实例使用的索引值为0和1)。
当缩容一个Statefulset时,比较好的是很明确哪个pod将要被删除。作为对比,ReplicaSet的缩容操作则不同,不知道哪个实例会被删除,也不能指定先删除哪个实例(也许这个功能会在将来实现)。缩容一个Statefulset将会最先删除最高索引值的实例(如图10.7所示),所以缩容的结果是可预知的。
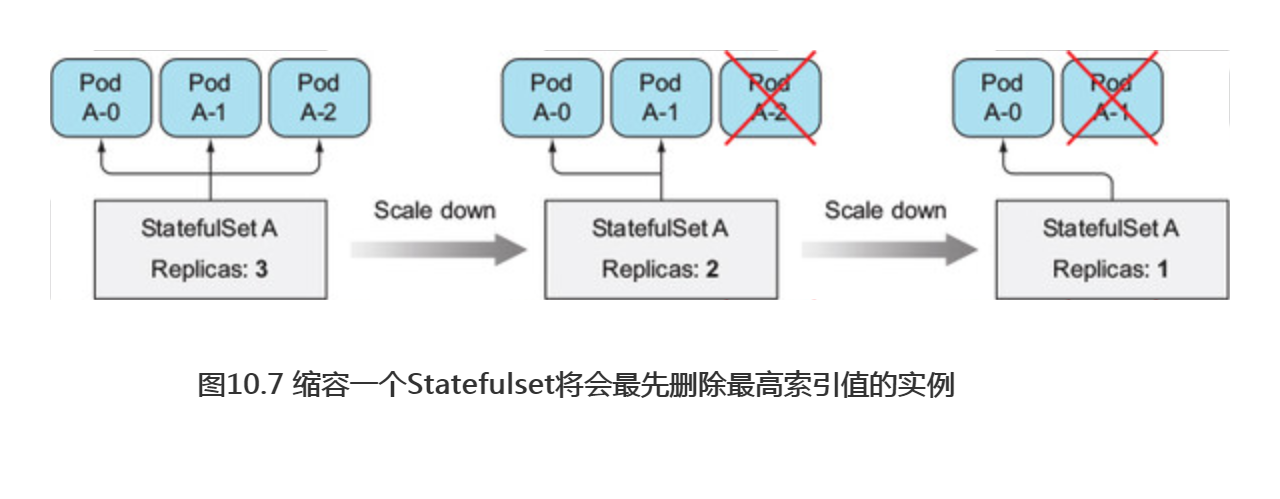
因为Statefulset缩容任何时候只会操作一个pod实例,所以有状态应用的缩容不会很迅速。举例来说,一个分布式存储应用若同时下线多个节点,则可能导致其数据丢失。比如说一个数据项副本数设置为2的数据存储应用,若同时有两个节点下线,一份数据记录就会丢失,如果它正好保存在这两个节点上。若缩容是线性的,则分布式存储应用就有时间把丢失的副本复制到其他节点,保证数据不会丢失。
基于以上原因,Statefulset在有实例不健康的情况下是不允许做缩容操作的。若一个实例是不健康的,而这时再缩容一个实例的话,也就意味着你实际上同时失去了两个集群成员。
2.3 为每个有状态实例提供稳定的专属存储
已经了解了Statefulset如何保证一个有状态的pod拥有稳定的标识,那存储呢?一个有状态的pod需要拥有自己的存储,即使该有状态的pod被重新调度(新的pod与之前pod的标识完全一致),新的实例也必须挂载着相同的存储。那Statefulset是如何做到这一点的呢?
很明显,有状态的pod的存储必须是持久的,并且与pod解耦。通过在pod中关联一个持久卷声明的名称,就可以为pod提供持久化存储。因为持久卷声明与持久卷是一对一的关系,所以每个Statefulset的pod都需要关联到不同的持久卷声明,与独自的持久卷相对应。因为所有的pod实例都是依据一个相同的pod模板创建的,那它们是如何关联到不同的持久卷的呢?并且由谁来创建这些持久卷呢?当然你肯定不想手在动创建Statefulset之前,依据pod的个数创建相同数量的持久卷量。当然不用这么做!
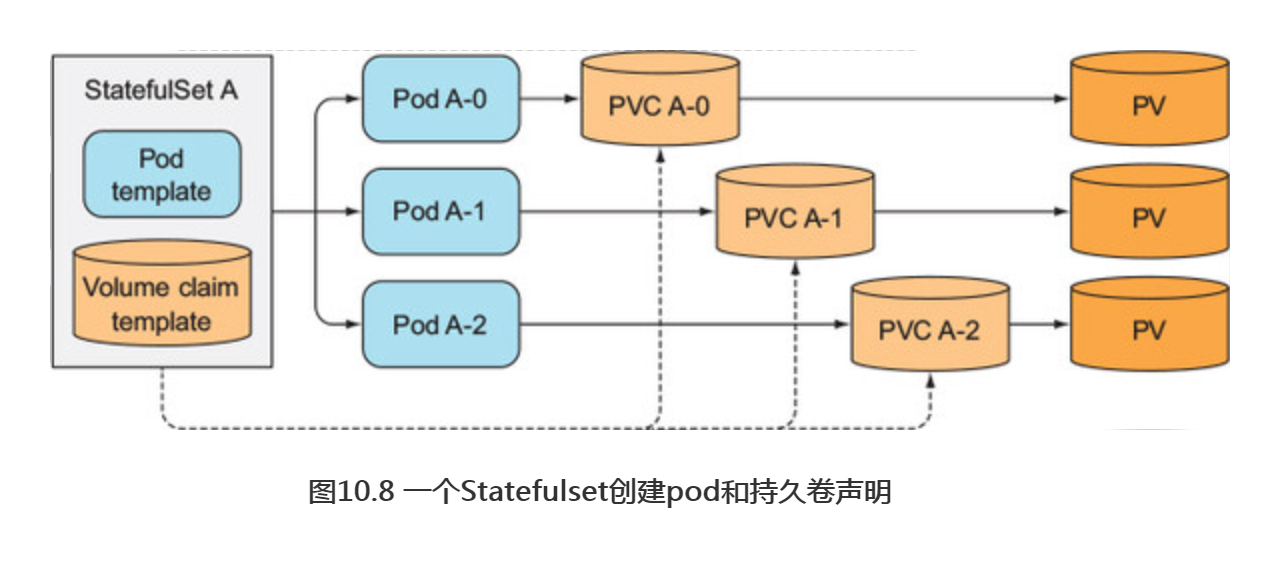
在pod模板中添加卷声明模板
像Statefulset创建pod—样,Statefulset也需要创建持久卷声明。所以一个Statefulset可以拥有一个或多个卷声明模板,这些持久卷声明会在创建pod前创建出来,绑定到一个pod实例上(如图10.8所示)。
声明的持久卷既可以通过administrator用户预先创建出来,也可以由持久卷的动态供应机制实时创建出来。
持久卷的创建和删除
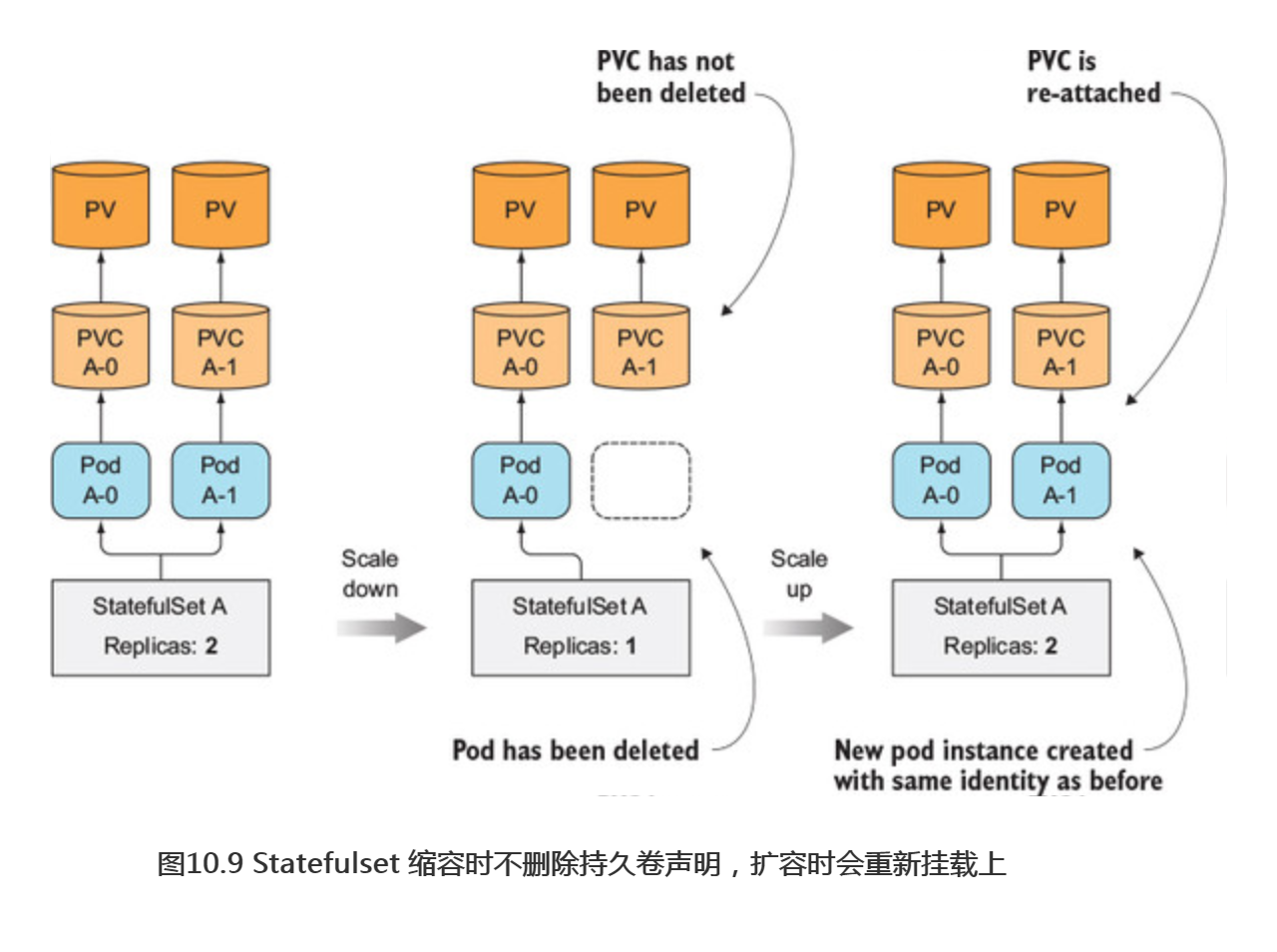
扩容Statefulset增加一个副本数时,会创建两个或更多的API对象(一个pod和与之关联的一个或多个持久卷声明)。但是对缩容来说,则只会删除一个pod,而遗留下之前创建的声明。当你知道一个声明被删除会发生什么的话,你就明白为什么这么做了。当一个声明被删除后,与之绑定的持久卷就会被回收或删除,则其上面的数据就会丢失。
因为有状态的pod是用来运行有状态应用的,所以其在数据卷上存储的数据非常重要,在Statefulset缩容时删除这个声明将是灾难性的,特别是对于Statefulset来说,缩容就像减少其replicas数值一样简单。基于这个原因,当你需要释放特定的持久卷时,需要手动删除对应的持久卷声明。
重新挂载持久卷声明到相同pod的新实例上
因为缩容Statefulset时会保留持久卷声明,所以在随后的扩容操作中,新的pod实例会使用绑定在持久卷上的相同声明和其上的数据(如图10.9所示)。当因为误操作而缩容一个Statefulset后,可以做一次扩容来弥补自己的过失,新的pod实例会运行到与之前完全一致的状态(名字也是一样的)。
2.4 Statefulset 的保障
如之前描述的,Statefulset的行为与ReplicaSet或ReplicationController是不一 样的。Statefulset不仅拥有稳定的标记和独立的存储,它的pod还有其他的一些保障。
稳定标识和独立存储的影响
通常来说,无状态的pod是可以替代的,而有状态的pod则不行。之前己经描述了一个有状态的pod总是会被一个完全一致的pod替换(两者有相同的名称、主机名和存储等)。这个替换发生在Kubernetes发现旧的pod不存在时(例如手动删除这个pod)。
那么当Kubernetes不能确定一个pod的状态时呢?如果它创建一个完全一致的pod,那系统中就会有两个完全一致的pod在同时运行。这两个pod会绑定到相同的存储,所以这两个相同标记的进程会同时写相同的文件。对于ReplicaSet的pod来说,这不是问题,因为应用本来就是设计为在相同的文件上工作的。并且我们知道 RepicaSet会以一个随机的标识来创建pod,所以不可能存在两个相同标识的进程同时运行。
介绍Statefulset的at-most-one的语义
Kubernetes必须保证两个拥有相同标记和绑定相同持久卷声明的有状态的pod实例不会同时运行。一个Statefulset必须保证有状态的pod实例的加语义。
也就是说一个Statefulset必须在准确确认一个pod不再运行后,才会去创建它的替换pod。这对如何处理节点故障有很大的影响,会在后面详细介绍。在做这些之前,需要先创建一个Statefulset,看看它是如何工作的。
3.使用Statefulset
为了展示Statefulset的行为,将会创建一个小的集群数据存储。没有太多功能,就像石器时代的一个数据存储。
3.1 创建应用和容器镜像
使用的kubia应用作为基础来扩展它,达到它的每个pod实例都能用来存储和接收一个数据项。
#代码10.1 一个简单的有状态应用:kubia-pet-image/app.js const http = require('http'); const os = require('os'); const fs = require('fs'); const dataFile = "/var/data/kubia.txt"; function fileExists(file) { try { fs.statSync(file); return true; } catch (e) { return false; } } var handler = function(request, response) { if (request.method == 'POST') { var file = fs.createWriteStream(dataFile); file.on('open', function (fd) { request.pipe(file); console.log("New data has been received and stored."); response.writeHead(200); response.end("Data stored on pod " + os.hostname() + " "); }); } else { var data = fileExists(dataFile) ? fs.readFileSync(dataFile, 'utf8') : "No data posted yet"; response.writeHead(200); response.write("You've hit " + os.hostname() + " "); response.end("Data stored on this pod: " + data + " "); } }; var www = http.createServer(handler); www.listen(8080);
当应用接收到一POST请求时,它把请求中的body数据内容写入/var/data/kubia.txt文件中。而在收到GET请求时,它返回主机名和存储数据(文件中的内容)。这是应用的第一版本。它还不是一个集群应用,但它足够可以开始工作。在本章的后面,会来扩展这个应用。
用来构建这个容器镜像的Dockerfile文件与之前的一样,如下面的代码清单
#代码10.2 有状态应用的 Dockerfile : kubia-pet-image/Dockerfile FROM node:7 ADD app.js /app.js ENTRYPOINT ["node", "app.js"]
构建镜像kubia-pet。
3.2 通过Statefulset部署应用
为了部署应用,需要创建两个(或三个)不同类型的对象:
-
- 存储数据文件的持久卷(当集群不支持持久卷的动态供应时,需要手动创建)
- Statefulset必需的一个控制Service
- Statefulset本身
对于每一个pod实例,Statefulset都会创建一个绑定到一个持久卷上的持久卷声明。如果集群支持动态供应,就不需要手动创建持久卷(可跳过下一节)。如果不支持的话,可以按照下一节所述创建它们。
创建持久化存储卷
因为会调度Statefulset创建三个副本,所以这里需要三个持久卷。如果计划调度创建更多副本,那么需要创建更多持久卷。
每个环境创建磁盘的方式都不一样。
如果使用Minikube,用以下方式
kind: List apiVersion: v1 items: - apiVersion: v1 kind: PersistentVolume metadata: name: pv-a spec: capacity: storage: 1Mi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle hostPath: path: /tmp/pv-a - apiVersion: v1 kind: PersistentVolume metadata: name: pv-b spec: capacity: storage: 1Mi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle hostPath: path: /tmp/pv-b - apiVersion: v1 kind: PersistentVolume metadata: name: pv-c spec: capacity: storage: 1Mi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle hostPath: path: /tmp/pv-c
如果使用谷歌的Kubernetes引擎,需要首先创建实际的GCE持久磁盘:
$ gcloud compute disks create --size=1GiB --zone=europe-west1-b pv-a $ gcloud compute disks create --size=1GiB --zone=europe-west1-b pv-b $ gcloud compute disks create --size=1GiB --zone=europe-west1-b pv-c
注意:保证创建的持久磁盘和运行的节点在同一区域。
然后通过persistent-volumes-gcepd.yaml文件创建需要的待久卷,如下面的代码清单所示。
kind: List #这是创建三个持久卷的文件描述 apiVersion: v1 items: - apiVersion: v1 kind: PersistentVolume metadata: name: pv-a spec: capacity: storage: 1Mi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle gcePersistentDisk: pdName: pv-a fsType: nfs4 - apiVersion: v1 kind: PersistentVolume metadata: name: pv-b ......
注意:在上一节通过在同一YAML文件中添加三个横杠(---)来区分定义多个资原,这里使用另外一种方去,定义一个List对象,然后把各个资源作为List对象的各个项目。上述两种方法的效果是一样的。
通过上诉文件创建了pv-a、pv-b和pv-c三个持久卷。它们使用GCE持久磁盘和指定的存储策略,所以它们并不适合没有运行在谷歌Kubernetes引擎(Google KubernetesEngine)或谷歌计算引擎(Google Compute Engine)上的集群。如果集群运行在其他地方,必须修改持久卷的定义,使用正确的卷类型,比如NFS(网络文件系统)或其他类似的类型。
创建控制Service
如之前所述,在部署一个Statefulset之前,需要创建一个用于在有状态的pod之间提供网络标识的headlessService。下面的代码显示了Service的详细信息。
#代码10.4 在 Statefulset 中使用的 headless service : kubia-service-headless.yaml apiVersion: v1 kind: Service metadata: name: kubia spec: clusterIP: None #Statefulset的控制Service必须是headless模式 selector: app: kubia ports: - name: http port: 80
上面指定了clusterIP为None,这就标记了它是一个headless Service。它使得pod之间可以彼此发现(后续会用到这个功能)。创建完这个Service之后,就可以继续往下创建实际的Statefulset了。
创建Statefulset代码
#代码10.5 Statefulset 详单:kubia-statefulset.yaml apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: kubia spec: serviceName: kubia replicas: 2 template: metadata: labels: #Statefulset创建的pod都带有app=kubia标签 app: kubia spec: containers: - name: kubia image: luksa/kubia-pet ports: - name: http containerPort: 8080 volumeMounts: - name: data mountPath: /var/data volumeClaimTemplates: - metadata: name: data spec: resources: requests: storage: 1Mi accessModes: - ReadWriteOnce
这个Statefulset 详单与创建ReplicaSet和Deployment 的详单没太多区别,这里使用的新组件是volumeClaimTemplates列表。 其中仅仅定义了一个名为daaa的卷声明, 会依据这个模板为每个pod都创建一个持久卷声明。pod通过在其详单中包含一个PersistentVolumeClaim卷来关联一个声明。 但在上面的pod模板中并没有这样的卷, 这是因为在Statefulset创建指定pod时, 会自动将PersistentVolumeClaim卷添加到pod详述中,然后将这个卷关联到一个声明上。
创建Statefulset
现在就要创建Statefulset了:
$ kubectl create -f kubia-statefulset.yaml statefulset "kubia" created
现在列出pod:
$ kubectl get po
NAME READY STATUS RESTARTS AGE
kubia-0 0/1 ContainerCreating 0 1s
有没有发现不同之处?是否记得一个ReplicationController或ReplicaSet会同时 创建所有的pod实例?Statefulset配置去创建两个副本,但是它仅仅创建了单个pod。
不要担心,这里没有出错。第二个pod会在第一个pod运行并且处于就绪状态后创建。Statefulset这样的行为是因为:状态明确的集群应用对同时有两个集群成员启动引起的竞争情况是非常敏感的。所以依次启动每个成员是比较安全可靠的。特定的有状态应用集群在两个或多个集群成员同时启动时引起的竞态条件是非常敏感的,所以在每个成员完全启动后再启动剩下的会更加安全。
再次列出pod并查看pod的创建过程:
$ kubectl get po NAME READY STATUS RESTARTS AGE kubia-0 1/1 Running 0 8s kubia-1 0/1 ContainerCreating 0 2s
可以看到第一个启动的pod状态是running,第二个pod已经创建并在启动过程中。
检查生成的有状态pod
现在让我们看一下第一个pod的详细参数,看一下Statefulset如何从pod模板和持久卷声明模板来构建pod, 如下面的代码清单所示。
#代码 10.6 Statefulset创建的有状态pod $ kubectl get po kubia-0 -o yaml apiVersion: v1 kind: Pod metadata: ... spec: containers: - image: luksa/kubia-pet ... volumeMounts: - mountPath: /var/data name: data - mountPath: /var/run/secrets/kubernetes.io/serviceaccount name: default-token-r2m41 readOnly: true ... volumes: - name: data persistentVolumeClaim: claimName: data-kubia-0 - name: default-token-r2m41 secret: secretName: default-token-r2m41
通过持久卷声明模板来创建持久卷声明和pod中使用的与持久卷声明相关的数据卷。
检查生成的持久卷声明
现在列出生成的持久卷声明来确定它们被创建了:
$ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESSMODES AGE data-kubia-0 Bound pv-c 0 37s data-kubia-1 Bound pv-a 0 37s
生成的持久卷声明的名称由在volumeClaimTemplate字段中定义的名称和每个pod的名称组成。可以检查声明的YAML文件来确认它们符合模板的定义。
3.3 使用pod
现在你的数据存储集群的节点都已经运行,可以开始使用它们了。因为之前创建的Service处于headless模式,所以不能通过它来访问你的pod。需要直接连接每个单独的pod来访问(或者创建一个普通的Service,但是这样还是不允许访问指定的pod)。
其它篇章也有讲解如何直接访问pod:借助另一个pod,然后在里面运行curl命令或者使用端口转发。这次来介绍另外一种方法,通过API服务器作为代理。
通过API服务器与pod通信
API服务器的一个很有用的功能就是通过代理直接连接到指定的pod。如果想请求当前的kubia-0 pod,可以通过如下URL:
<apiServerHost>:<port>/api/v1/namespaces/default/pods/kubia-0/proxy/<path>
因为API服务器是有安全保障的,所以通过API服务器发送请求到pod是烦琐的(需要额外在每次请求中添加授权令牌)。所以这次使用代理这种简单的方式。
$ kubectl proxy
Starting to serve on 127.0.0.1:8001
现在,因为要通过kubectl代理来与API服务器通信,将使用localhost:8001来代替实际的API服务器主机地址和端口。将发送一个如下所示的请求到kubia-0 pod:
$ curl localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/ You've hit kubia-0 Data stored on this pod: No data posted yet
返回的消息表明你的请求被正确收到,并在kubia-0pod的应用中被正确处理。
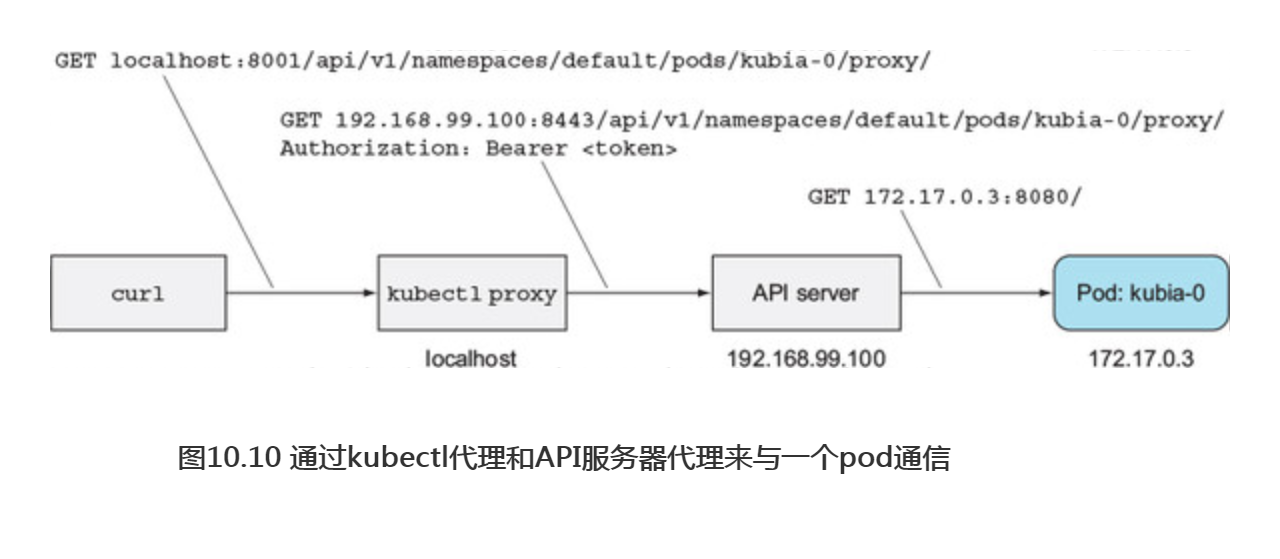
因为正在使用代理的方式,通过API服务器与pod通信,每个请求都会经过两个代理(第一个是kubectl代理,第二个是把请求代理到pod的API服务器)。详细的描述如图10.10所示。
上面介绍的是发送一个GET请求到pod,也可以通过API服务器发送POST请求。发送POST请求使用的代理URL与发送GET请求一致。
当应用收到一个POST请求时,它把请求的主体内容保存到本地一个文件中。发送一个POST请求到 kubia-0 pod 的示例:
$ curl -X POST -d "Hey there! This greeting was submitted to kubia-0." localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/ Data stored on pod kubia-0
你发送的数据现在已经保存到pod中,那让检查一下当再次发送一个GET 请求时, 它是否返回存储的数据:
$ curl localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/ You've hit kubia-0 Data stored on this pod: Hey there! This greeting was submitted to kubia-0.
到目前为止都工作正常。现在看看集群其他节点(kubia-1 pod):
$ curl localhost:8001/api/v1/namespaces/default/pods/kubia-1/proxy/ You've hit kubia-1 Data stored on this pod: No data posted yet
与期望的一致,每个节点拥有独自的状态。下面验证一下这些状态是否持久的
删除一个有状态pod来检查重新调度的pod是否关联了相同的存储
你将会删除kubia-0 pod,等待它被重新调度,然后就可以检查它是否会返回与之前一致的数据:
$ kubectl delete po kubia-0 pod "kubia-0" deleted
你列出当前pod, 可以看到该pod正在终止运行:
$ kubectl get po NAME READY STATUS RESTARTS AGE kubia-0 1/1 Terminating 0 3m kubia-1 1/1 Running 0 3m
当它一旦成功终止, Statefulset会重新创建一个具有相同名称的新的pod:
$ kubectl get po NAME READY STATUS RESTARTS AGE kubia-0 0/1 ContainerCreating 0 6s kubia-1 1/1 Running 0 4m $ kubectl get po NAME READY STATUS RESTARTS AGE kubia-0 1/1 Running 0 9s kubia-1 1/1 Running 0 4m
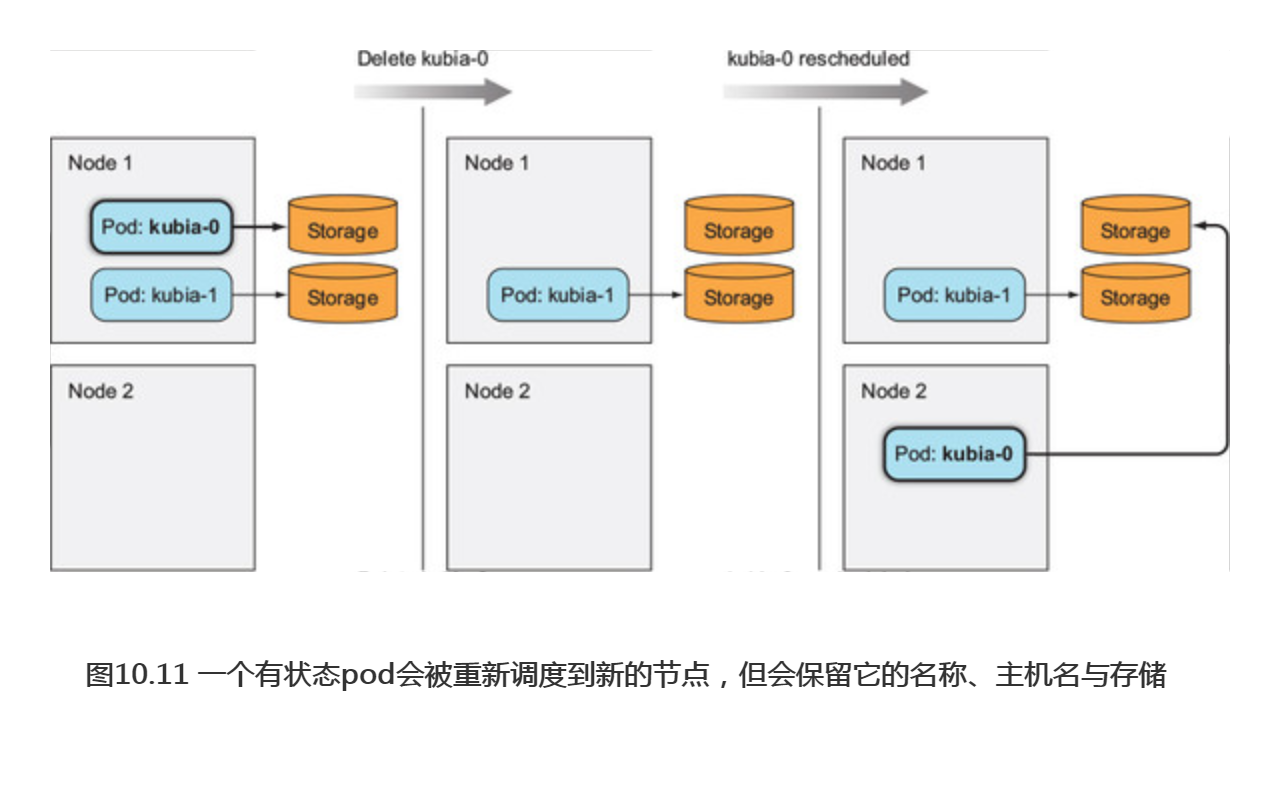
请记住,新的pod可能会被调度到集群中的任何一个节点,并不一定保持与旧的pod所在的节点一致。旧的pod的全部标记(名称、主机名和存储)实际上都会转移到新的pod上(如果10.11所示)。如果使用Minikube,将看不到这些,因为它仅仅运行在单个节点上,但是对于多个节点的集群来说,可以看到新的pod会被调度到与之前pod不一样的节点上。
现在新的pod已经运行了,那让检查一下它是否拥有与之前的pod一样的标记。pod的名称是一样的,那它的主机名和持久化数据呢?可以通过访问pod来确认:
$ curl localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/ You've hit kubia-0 Data stored on this pod: Hey there! This greeting was submitted to kubia-0
从pod返回的信息表明它的主机名和持久化数据与之前pod是完全一致的,所以可以确认Statefulset会使用一个完全一致的pod来替换被删除的pod。
扩缩容Statefulset
缩容一个Statefulset,然后在完成后再扩容它,与删除一个pod后让Statefulset立马重新创建它的表现是没有区别的。需要记住的是,缩容一个Statefulset只会删除对应的pod,留下卸载后的持久卷声明。可以尝试缩容一个Statefulset,来进行确认。
需要明确的关键点是,缩容/扩容都是逐步进行的,与Statefulset最初被创建时会创建各自的pod—样。当缩容超过一个实例的时候,会首先删除拥有最高索引值的pod。只有当这个pod被完全终止后,才会开始删除拥有次高索引值的pod。
通过一个普通的非headless的Service暴露Statefulset的pod
在阅读这一章的最后一部分之前,需要为pod添加一个适当的非headless Service,这是因为客户端通常不会直接连接pod,而是通过一个服务。
#代码10. 7 —个用来访问有状态pod的常规Service: kubia-service-public.yaml apiVersion: v1 kind: Service metadata: name: kubia-public spec: selector: app: kubia ports: - port: 80 targetPort: 8080
因为它不是外部暴露的Service(它是一个常规ClusterlPService,不是一个NodePort或LoadBalancer-type Service),只能在你的集群内部访问它。那是否需要一个pod来访问它呢?答案是不需要。
通过API服务器访问集群内部的服务
不通过额外的pod来访问集群内部的服务的话,与之前使用访问单独pod的方法一样,可以使用API服务器提供的相同代理属性来访问。
代理请求到Service的URL路径格式如下:
/api/v1/namespaces/<namespace>/services/<service name>/proxy/<path>
因此可以在本地机器上运行curl命令,通过kubectl代理来访问服务(之前启动过kubectl proxy,现在它应该还在运行着):
$ curl localhost:8001/api/v1/namespaces/default/services/kubia-public/proxy/ You've hit kubia-1 Data stored on this pod: No data posted yet
客户端(集群内部)同样可以通过kubia-public服务来存储或者读取你的集群中的数据。 当然,每个请求会随机分配到一个集群节点上,所以每次都会随机获取一个节点上的数据。 后面会改进它。
4.在Statefulset中发现伙伴节点
我们仍然需要弄清楚一件很重要的事情。集群应用中很重要的一个需求是伙伴节点彼此能发现——这样才可以找到集群中的其他成员。一个Statefulset中的成员需要很容易地找到其他的所有成员。当然它可以通过与API服务器通信来获取,但是Kubernetes的一个目标是设计功能来帮助应用完全感觉不到Kubernetes的存在。因此让应用与API服务器通信的设计是不允许的。
那如何使得一个pod可以不通过API与其他伙伴通信呢?是否有已知的广泛存在的技术来帮助达到目的呢?那使用域名系统(DNS)如何?这依赖于对DNS系统有多熟悉,可能理解什么是A、CNAME或MX记录的用处是什么。DNS记录里还有其他一些不是那么知名的类型,SRV记录就是其中的一个。
介绍SRV记录
SRV记录用来指向提供指定服务的服务器的主机名和端口号。Kubernetes通过 一个headless seivice创建SRV记录来指向pod的主机名。
可以在一个临时pod里运行DNS查询工具-dig命令,列出有状态pod的SRV记录。示例命令如下:
$ kubectl run -it srvlookup --image=tutum/dnsutils --rm --restart=Never -- dig SRV kubia.default.svc.cluster.local
上面的命令运行一个名为srvlookup的一次性pod(--restart=Never),它会关联控制台(-it)并且在终止后立即删除(--rm)。这个pod依据tutum/dnsutils镜像启动单独的容器,然后运行下面的命令
dig SRV kubia.default.svc.cluster.local
下面的代码清单显示了这个命令的输出结果。
代码 10.8列出你的headlessService的DNS SRV记录 ... ;; ANSWER SECTION: k.d.s.c.l. 30 IN SRV 10 33 0 kubia-0.kubia.default.svc.cluster.local. k.d.s.c.l. 30 IN SRV 10 33 0 kubia-1.kubia.default.svc.cluster.local. ;; ADDITIONAL SECTION: kubia-0.kubia.default.svc.cluster.local. 30 IN A 172.17.0.4 kubia-1.kubia.default.svc.cluster.local. 30 IN A 172.17.0.6 ...
注意:为了让记录可以在一行里显示,对真实名称做了缩减,对应kubia.d.s.c.l.的全称是kubia.default.svc.cluster.local。
上面的ANSWER SECTION显示了两条指向后台headless service的SRV记录。 同时如ADDITIONAL SECTION所示,每个pod都拥有独自的一条记录。
当一个pod要获取一个Statefulset里的其他pod列表时,需要做的就是触发一次SRVDNS查询。例如,在Node.js中查询命令为:
dns.resolveSrv("kubia.default.svc.cluster.local", callBackFunction);
可以在你的应用中使用上述命令让每个pod发现它的伙伴pod。
注意:返回的SRV记录顺序是随机的,因为它们拥有相同的优先级。所以不要期望总是看到kubia-0会排在kubia-1前面。
4.1 通过DNS实现伙伴间彼此发现
原始的数据存储服务还不是集群级别的,每个数据存储节点都是完全独立于其他节点的它们彼此之间没有通信。下一步做的就是让它们彼此通信。
客户端通过kubia-public Service连接数据存储服务,并且会到达集群里随机的一个节点。集群可以存储多条数据项,但是客户端当前却不能看到所有的数据项。因为服务把请求随机地送达一个pod,所以若客户端想获取所有pod的数据,必须发送很多次请求,一直到它的请求发送到所有的pod为止。
可以通过让节点返回所有集群节点数据的方式来改进这个行为。为了达到目的,节点需要能找到它所有的伙伴节点。可以使用上面的Stattfulset和SRV记录来实现这个功能。
可以如下面的代码清单所示修改应用源码。
... const dns = require('dns'); const dataFile = "/var/data/kubia.txt"; const serviceName = "kubia.default.svc.cluster.local"; const port = 8080; ... var handler = function(request, response) { if (request.method == 'POST') { ... } else { response.writeHead(200); if (request.url == '/data') { var data = fileExists(dataFile) ? fs.readFileSync(dataFile, 'utf8') : "No data posted yet"; response.end(data); } else { response.write("You've hit " + os.hostname() + " "); response.write("Data stored in the cluster: "); dns.resolveSrv(serviceName, function (err, addresses) { #通过DNS查询获取SRV记录 if (err) { response.end("Could not look up DNS SRV records: " + err); return; } var numResponses = 0; if (addresses.length == 0) { response.end("No peers discovered."); } else { addresses.forEach(function (item) { var requestOptions = { host: item.name, port: port, path: '/data' }; httpGet(requestOptions, function (returnedData) { numResponses++; response.write("- " + item.name + ": " + returnedData); response.write(" "); if (numResponses == addresses.length) { response.end(); } }); }); } }); } } }; ...
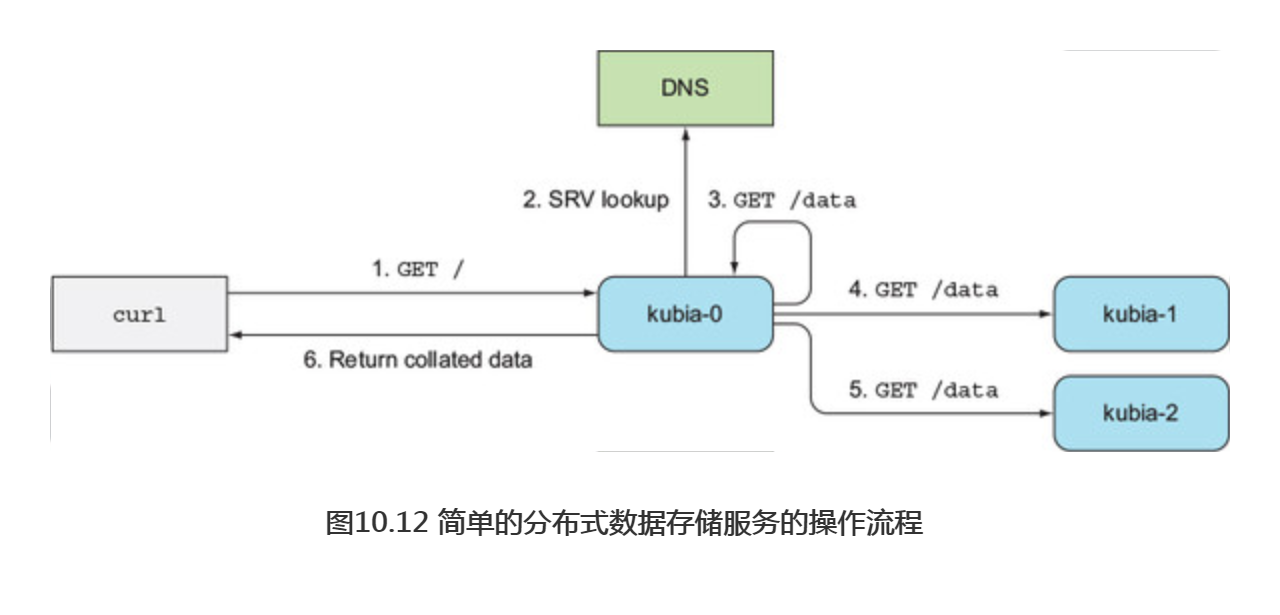
图10.12展示了一个GET请求到达应用后的处理过程。首先收到请求的服务器会触发一次headless kubia服务的SRV记录查询,然后发送GET请求到服务背后的每一个pod(也会发送给自己,虽说没有必要,这里只是为了保证代码简单易懂),然后返回所有节点和它们的数据信息的列表。
4.2 更新Statefulset
现在你的Statefulset己经运行起来,那让我们看一下如何更新它的pod模板,让它使用新的镜像。同时也会修改副本数为3。通常会使用kubectl edit命令来更新Statefulset (另一个选择是patch命令)。
$ kubectl edit statefulset kubia
上面的命令会使用默认的编辑器打开Statefulset的定义。在定义中,修改spec.replicas为3,修改spec.template.spec.containers.image属性指向新的镜像(使用luksa/kubia-pet-peers替换luksa/kubia-pet)。然后保存文件并退出,Statefulset就会更新。之前Statefulset有两个副本,现在应该可以看到一个新的名叫kubia-2的副本启动了。通过下面的代码列出pod来确认:
$ kubectl get po NAME READY STATUS RESTARTS AGE kubia-0 1/1 Running 0 25m kubia-1 1/1 Running 0 26m kubia-2 0/1 ContainerCreating 0 4s
新的pod实例会使用新的镜像运行,那己经存在的两个副本呢?通过它们的寿命可以看出它们并没有更新。这是符合预期的。因为,首先Statefuset更像ReplicaSet,而不是Deployment,所以在模板被修改后,它们不会重启更新。需要手动删除这些副本,然后Statefulset会依据新的模板重新调度启动它们。
$ kubectl delete po kubia-0 kubia-1 pod "kubia-0" deleted pod "kubia-1" deleted
注意:Kubernetes1.7版本开始,Statefulset支持与Deployment和DaemonSet—样的滚动升级。通过kubectl explain获取Statefulset的spec.updateStrategy相关文档来获取更多信息。
4.3 尝试集群数据存储
当两个pod都启动后,即可测试新的新石器时代的数据存储是否按预期一样工作了。如下面的代码清单所示,发送一些请求到集群。
#代码10.10 通过service往集群数据存储中写入数据 $ curl -X POST -d "The sun is shining" localhost:8001/api/v1/namespaces/default/services/kubia-public/proxy/ Data stored on pod kubia-1 $ curl -X POST -d "The weather is sweet" localhost:8001/api/v1/namespaces/default/services/kubia-public/proxy/ Data stored on pod kubia-0
现在,读取存储的数据,如下面的代码清单所示。
#代码 10.11从数据存储中读取数据 $ curl localhost:8001/api/v1/namespaces/default/services/kubia-public/proxy/ You've hit kubia-2 stored on each cluster node: -kubia-0.kubia.default.svc.cluster.local: The weather is sweet -kubia-1.kubia.default.svc.cluster.local: The sun is shining -kubia-2.kubia.default.svc.cluster.local: No data posted yet
非常棒!当一个客户端请求到达集群中任意一个节点后,它会发现它的所有伙伴节点,然后通过它们收集数据,然后把收集到的所有数据返回给客户端。即使扩容或缩容Statefulset,服务于客户端请求的pod都会找到所有的伙伴节点。
这个应用本身也许没太多用处,但这里希望你觉得这是一种有趣的方式,一个多副本Statefulset应用的实例如何发现它的伙伴,并且随需求做到横向扩展。
5.了解Statefulset如何处理节点失效
在2.4节中,阐述了Kubernetes必须完全保证:一个有状态pod在创建它的代替者之前已经不再运行,当一个节点突然失效,Kubernetes并不知道节点或者它上面的pod的状态。它并不知道这些pod是否还在运行,或者它们是否还存在,甚至是否还能被客户端访问到,或者仅仅是Kubelet停止向主节点上报本节点状态。
因为一个Statefulset要保证不会有两个拥有相同标记和存储的pod同时运行,当一个节点似乎失效时,Statefulset在明确知道一个pod不再运行之前,它不能或者不应该创建一个替换pod。
只有当集群的管理者告诉它这些信息的时候,它才能明确知道。为了做到这一点,管理者需要删除这个pod,或者删除整个节点(这么做会删除所有调度到该节点上的pod)。
作为这一章中的最后一个练习,你会看到当一个集群节点网络断开后,Statefulset和节点上的pod都会发生些什么。
5.1 模拟一个节点的网络断开
通过关闭节点的ethO网络接口来模拟节点的网络断开。因为这个例子需要多个节点,所以不能在Minikube上运行,可以使用谷歌的Kubernetes引擎来运行。
关闭节点的网络适配器
为了关闭一个节点的网络接口,需要通过ssh登录一个节点:
$ gcloud compute ssh gke-kubia-default-pool-32a2cac8-m0g1
然后在节点内部运行如下命令:
$ sudo ifconfig eth0 down
之后ssh链接就会中断,所以需要开启一个新的终端来继续执行。
通过Kubernetes管理节点检查节点的状态
当这个节点的网络接口关闭以后,运行在这个节点上的Kubelet服务就无法与 Kubernetes API服务器通信,无法汇报本节点和上面的pod都在正常运行。
过了一段时间后,控制台就会标记该节点状态为NotReady。如下面的代码清单所示,当列出节点时可以看到这些。
#代码10.12 观察到一个失效的节点状态变为NotReady $ kubectl get node NAME STATUS AGE VERSION gke-kubia-default-pool-32a2cac8-596v Ready 16m v1.6.2 gke-kubia-default-pool-32a2cac8-m0g1 NotReady 16m v1.6.2 gke-kubia-default-pool-32a2cac8-sgl7 Ready 16m v1.6.2
因为控制台不会再收到该节点发送的状态更新,该节点上面的所有pod状态都会变为Unknown。如下面的代码清单所示,列举pod信息就可以看到。
#代码10.13观察到节点变为NotReady后,其上的pod状态就会改变 $ kubectl get po NAME READY STATUS RESTARTS AGE kubia-0 1/1 Unknown 0 15m kubia-1 1/1 Running 0 14m kubia-2 1/1 Running 0 13m
正如看到的这样,kubia-0 pod的状态不再己知,这是因为关闭了这个pod之前运行(也许正在运行)的节点的网络接口。
当一个pod状态为Unknow时会发生什么
若该节点过段时间正常连通,并且重新汇报它上面的pod状态,那这个pod就会重新被标记为Runing。但如果这个pod的未知状态持续几分钟后(这个时间是可以配置的),这个pod就会自动从节点上驱逐。这是由主节点(Kubernetes的控制组件)处理的。它通过删除pod的资源来把它从节点上驱逐。
当Kubelet发现这个pod被标记为删除状态后,它开始终止运行该pod。在上面的示例中,Kubelet己不能与主节点通信(因为你断开了这个节点的网络),这也就意味着这个pod会一直运行着。
解释一下当前的状况。通过kubectl describe命令查看kubia-0 pod的详细信息,如下面的代码清单所示。
#代码10.14 显示未知状态的pod的详情 $ kubectl describe po kubia-0 Name: kubia-0 Namespace: default Node: gke-kubia-default-pool-32a2cac8-m0g1/10.132.0.2 ... Status: Terminating (expires Tue, 23 May 2017 15:06:09 +0200) Reason: NodeLost Message: Node gke-kubia-default-pool-32a2cac8-m0g1 which was running pod kubia-0 is unresponsive
可以看到这个pod的状态为Terminating,原因是NodeLost。在信息中说明的是节点不回应导致的不可达。
注意:这里展示的是控制组件看到的信息。实际上这个pod对应的容器并被没有被终止,还在正常运行。
5.2 手动删除pod
己经明确这个节点不会再回来,但是所有处理客户端请求的三个pod都必须是正常运行的。所以需要把kubia-0 pod重新调度到一个健康的节点上。如之前提到的那样,需要手动删除整个节点或者这个pod。
正常删除pod
使用一直使用的方式删除该pod:
$ kubectl delete po kubia-0 pod "kubia-0" deleted
是不是所有的都做完了?删除pod后,Statefulset应该会立刻创建一个替换的pod,这个pod会被调度到剩下可用的节点上。再次列举pod信息来确认:
$ kubectl get po NAME READY STATUS RESTARTS AGE kubia-0 1/1 Unknown 0 15m kubia-1 1/1 Running 0 14m kubia-2 1/1 Running 0 13m
非常奇怪,你刚刚删除了这个pod, kubectl也返回说它己经被删除。那为什么这个pod还在呢?
注意:列表中的kubia-0 pod不是一个有相同名字的新pod,在从它的AGE列中就可以看出。如果它是一个新pod,它的“年龄”只会是几秒钟。
为什么pod没有被删除
在删除pod之前,这个pod己经被标记为删除。这是因为控制组件己经删除了它(把它从节点驱逐)。
如果再次检查一下代码清单10.14,可以看出这个pod的状态是Terminating。这个pod之前己经被标记为删除,只要它所在节点上的Kubelet通知API服务器说这个pod的容器己经终止,那么它就会被清除掉。但是因为这个节点上的网络断开了,所以上述情况永远不会发生。
强制删除pod
现在你唯一可以做的是告诉API服务器不用等待kubelet来确认这个pod已经不再运行,而是直接删除它。可以按照下面所述执行:
$ kubectl delete po kubia-0 --force --grace-period 0 warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely. pod "kubia-0" deleted
需要同时使用--force和--grace-period 0两个选项。然后kubectl会对你做的事情发出警告信息。如果你再次列举pod,就可以看到一个新的kubia-0 pod被创建出来:
$ kubectl get po NAME READY STATUS RESTARTS AGE kubia-0 0/1 ContainerCreating 0 8s kubia-1 1/1 Running 0 20m kubia-2 1/1 Running 0 19m
警告:除非确认节点不再运行或者不会再可以访问(永远不会再可以访问), 否则不要强制删除有状态的pod。
在继续操作之前,你可能希望把之前断掉连接的节点恢复正常。可以通过GCE web控制台或在一个终端上执行下面的命令来重启该节点:
$ gcloud compute instances reset <node name>